 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Challenges of Persian User-generated Textual Content: A Machine Learning-Based Approach
Paper and Code
Jan 20, 2021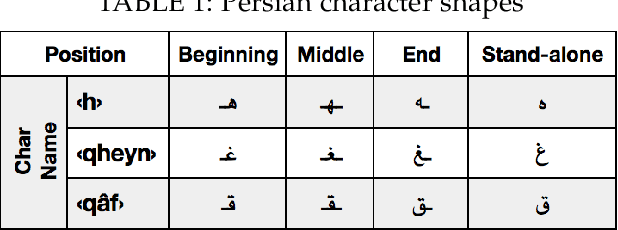
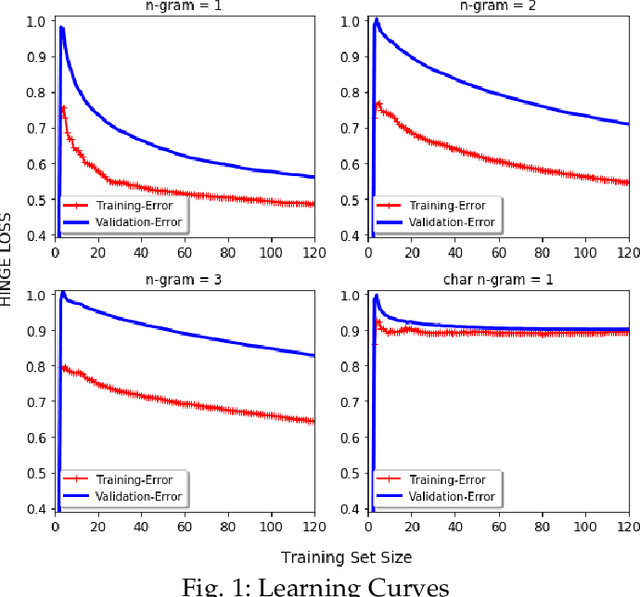
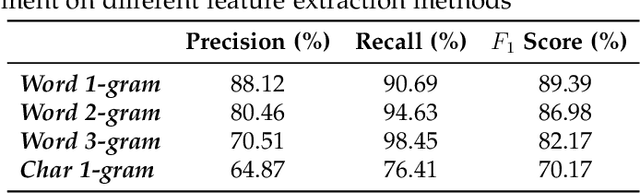
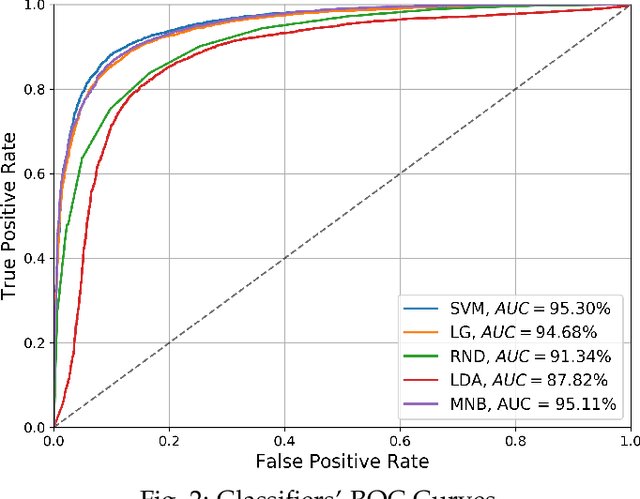
Over recent years a lot of research papers and studies have been published on the development of effective approaches that benefit from a large amount of user-generated content and build intelligent predictive models on top of them. This research applies machine learning-based approaches to tackle the hurdles that come with Persian user-generated textual content. Unfortunately, there is still inadequate research in exploiting machine learning approaches to classify/cluster Persian text. Further, analyzing Persian text suffers from a lack of resources; specifically from datasets and text manipulation tools. Since the syntax and semantics of the Persian language is different from English and other languages, the available resources from these languages are not instantly usable for Persian. In addition, recognition of nouns and pronouns, parts of speech tagging, finding words' boundary, stemming or character manipulations for Persian language are still unsolved issues that require further studying. Therefore, efforts have been made in this research to address some of the challenges. This presented approach uses a machine-translated datasets to conduct sentiment analysis for the Persian language. Finally, the dataset has been rehearsed with different classifiers and feature engineering approaches. The results of the experiments have shown promising state-of-the-art performance in contrast to the previous efforts; the best classifier was Support Vector Machines which achieved a precision of 91.22%, recall of 91.71%, and F1 score of 91.46%.