 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring LDA Topic Stability from Clusters of Replicated Runs
Paper and Code
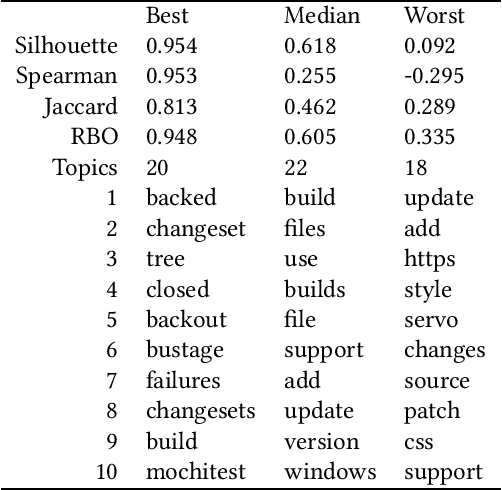
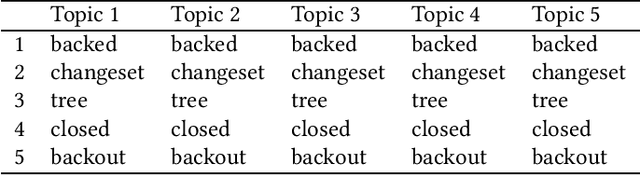
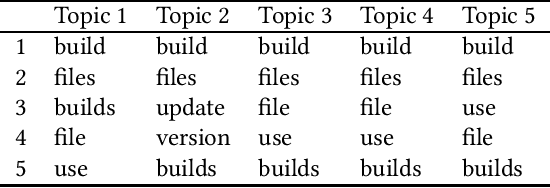
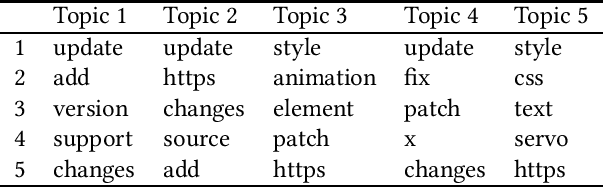
Background: Unstructured and textual data is increasing rapidly and Latent Dirichlet Allocation (LDA) topic modeling is a popular data analysis methods for it. Past work suggests that instability of LDA topics may lead to systematic errors. Aim: We propose a method that relies on replicated LDA runs, clustering, and providing a stability metric for the topics. Method: We generate k LDA topics and replicate this process n times resulting in n*k topics. Then we use K-medioids to cluster the n*k topics to k clusters. The k clusters now represent the original LDA topics and we present them like normal LDA topics showing the ten most probable words. For the clusters, we try multiple stability metrics, out of which we recommend Rank-Biased Overlap, showing the stability of the topics inside the clusters. Results: We provide an initial validation where our method is used for 270,000 Mozilla Firefox commit messages with k=20 and n=20. We show how our topic stability metrics are related to the contents of the topics. Conclusions: Advances in text mining enable us to analyze large masses of text in software engineering but non-deterministic algorithms, such as LDA, may lead to unreplicable conclusions. Our approach makes LDA stability transparent and is also complementary rather than alternative to many prior works that focus on LDA parameter tuning.