 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimized 3D Gaussian Splatting using Coarse-to-Fine Image Frequency Modulation
Mar 18, 2025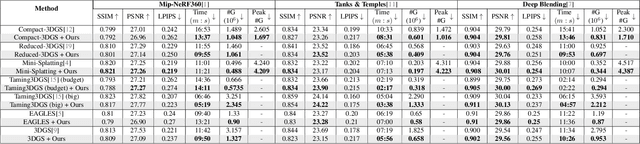
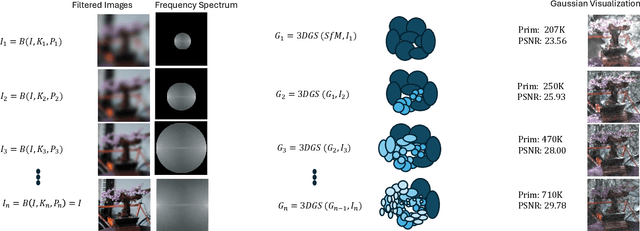
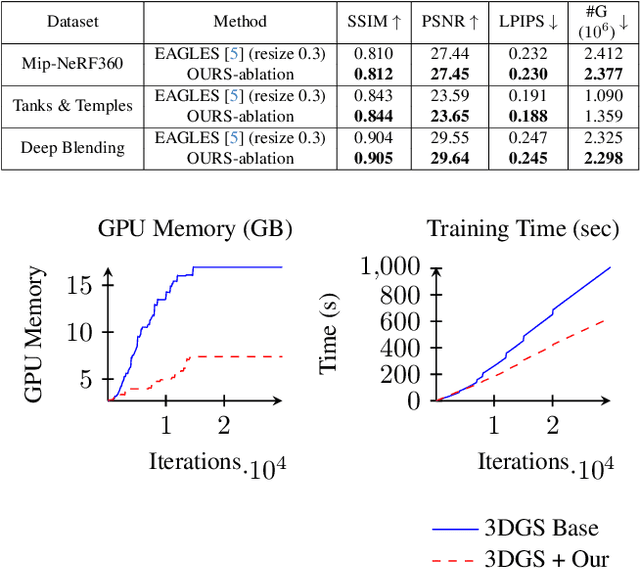

The field of Novel View Synthesis has been revolutionized by 3D Gaussian Splatting (3DGS), which enables high-quality scene reconstruction that can be rendered in real-time. 3DGS-based techniques typically suffer from high GPU memory and disk storage requirements which limits their practical application on consumer-grade devices. We propose Opti3DGS, a novel frequency-modulated coarse-to-fine optimization framework that aims to minimize the number of Gaussian primitives used to represent a scene, thus reducing memory and storage demands. Opti3DGS leverages image frequency modulation, initially enforcing a coarse scene representation and progressively refining it by modulating frequency details in the training images. On the baseline 3DGS, we demonstrate an average reduction of 62% in Gaussians, a 40% reduction in the training GPU memory requirements and a 20% reduction in optimization time without sacrificing the visual quality. Furthermore, we show that our method integrates seamlessly with many 3DGS-based techniques, consistently reducing the number of Gaussian primitives while maintaining, and often improving, visual quality. Additionally, Opti3DGS inherently produces a level-of-detail scene representation at no extra cost, a natural byproduct of the optimization pipeline. Results and code will be made publicly available.
Joint Reconstruction of Spatially-Coherent and Realistic Clothed Humans and Objects from a Single Image
Feb 25, 2025
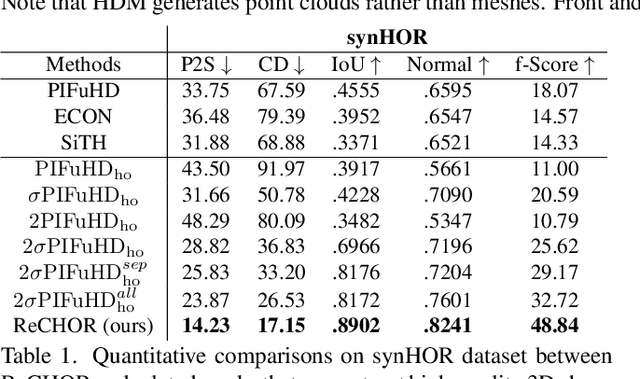
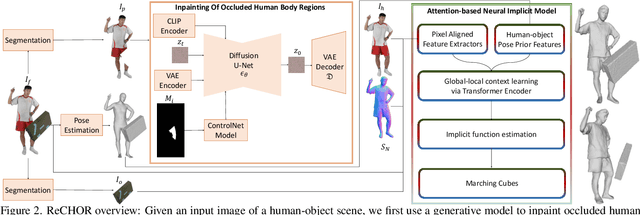
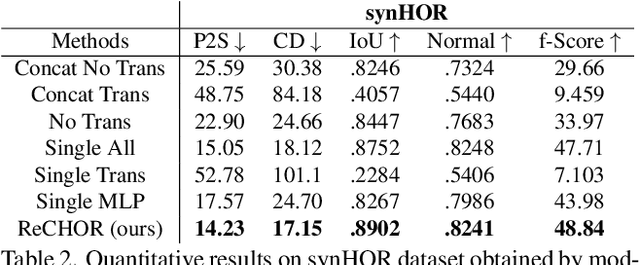
Recent advances in human shape learning have focused on achieving accurate human reconstruction from single-view images. However, in the real world, humans share space with other objects. Reconstructing images with humans and objects is challenging due to the occlusions and lack of 3D spatial awareness, which leads to depth ambiguity in the reconstruction. Existing methods in monocular human-object reconstruction fail to capture intricate details of clothed human bodies and object surfaces due to their template-based nature. In this paper, we jointly reconstruct clothed humans and objects in a spatially coherent manner from single-view images, while addressing human-object occlusions. A novel attention-based neural implicit model is proposed that leverages image pixel alignment to retrieve high-quality details, and incorporates semantic features extracted from the human-object pose to enable 3D spatial awareness. A generative diffusion model is used to handle human-object occlusions. For training and evaluation, we introduce a synthetic dataset with rendered scenes of inter-occluded 3D human scans and diverse objects. Extensive evaluation on both synthetic and real datasets demonstrates the superior quality of proposed human-object reconstructions over competitive methods.
COSMU: Complete 3D human shape from monocular unconstrained images
Jul 15, 2024
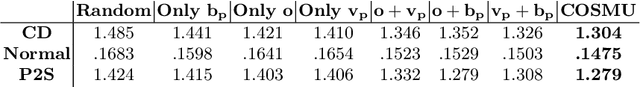
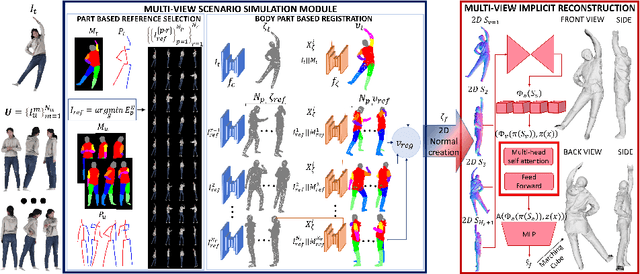
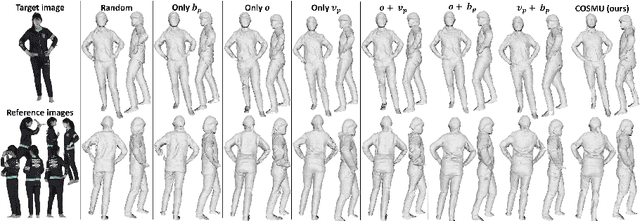
We present a novel framework to reconstruct complete 3D human shapes from a given target image by leveraging monocular unconstrained images. The objective of this work is to reproduce high-quality details in regions of the reconstructed human body that are not visible in the input target. The proposed methodology addresses the limitations of existing approaches for reconstructing 3D human shapes from a single image, which cannot reproduce shape details in occluded body regions. The missing information of the monocular input can be recovered by using multiple views captured from multiple cameras. However, multi-view reconstruction methods necessitate accurately calibrated and registered images, which can be challenging to obtain in real-world scenarios. Given a target RGB image and a collection of multiple uncalibrated and unregistered images of the same individual, acquired using a single camera, we propose a novel framework to generate complete 3D human shapes. We introduce a novel module to generate 2D multi-view normal maps of the person registered with the target input image. The module consists of body part-based reference selection and body part-based registration. The generated 2D normal maps are then processed by a multi-view attention-based neural implicit model that estimates an implicit representation of the 3D shape, ensuring the reproduction of details in both observed and occluded regions. Extensive experiments demonstrate that the proposed approach estimates higher quality details in the non-visible regions of the 3D clothed human shapes compared to related methods, without using parametric models.
Gaussian Splatting with Localized Points Management
Jun 13, 2024
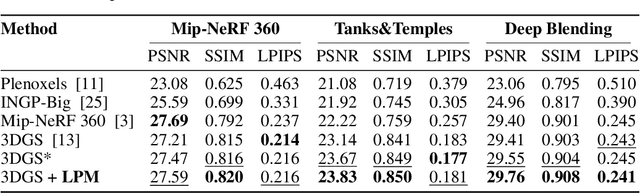
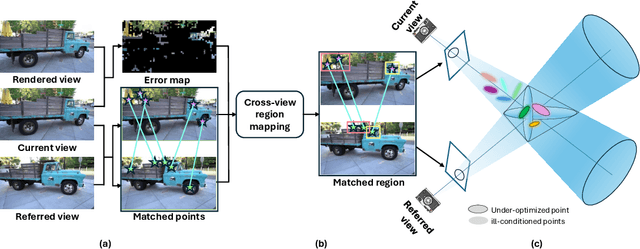

Point management is a critical component in optimizing 3D Gaussian Splatting (3DGS) models, as the point initiation (e.g., via structure from motion) is distributionally inappropriate. Typically, the Adaptive Density Control (ADC) algorithm is applied, leveraging view-averaged gradient magnitude thresholding for point densification, opacity thresholding for pruning, and regular all-points opacity reset. However, we reveal that this strategy is limited in tackling intricate/special image regions (e.g., transparent) as it is unable to identify all the 3D zones that require point densification, and lacking an appropriate mechanism to handle the ill-conditioned points with negative impacts (occlusion due to false high opacity). To address these limitations, we propose a Localized Point Management (LPM) strategy, capable of identifying those error-contributing zones in the highest demand for both point addition and geometry calibration. Zone identification is achieved by leveraging the underlying multiview geometry constraints, with the guidance of image rendering errors. We apply point densification in the identified zone, whilst resetting the opacity of those points residing in front of these regions so that a new opportunity is created to correct ill-conditioned points. Serving as a versatile plugin, LPM can be seamlessly integrated into existing 3D Gaussian Splatting models. Experimental evaluation across both static 3D and dynamic 4D scenes validate the efficacy of our LPM strategy in boosting a variety of existing 3DGS models both quantitatively and qualitatively. Notably, LPM improves both vanilla 3DGS and SpaceTimeGS to achieve state-of-the-art rendering quality while retaining real-time speeds, outperforming on challenging datasets such as Tanks & Temples and the Neural 3D Video Dataset.
Localized Gaussian Point Management
Jun 06, 2024Point management is a critical component in optimizing 3D Gaussian Splatting (3DGS) models, as the point initiation (e.g., via structure from motion) is distributionally inappropriate. Typically, the Adaptive Density Control (ADC) algorithm is applied, leveraging view-averaged gradient magnitude thresholding for point densification, opacity thresholding for pruning, and regular all-points opacity reset. However, we reveal that this strategy is limited in tackling intricate/special image regions (e.g., transparent) as it is unable to identify all the 3D zones that require point densification, and lacking an appropriate mechanism to handle the ill-conditioned points with negative impacts (occlusion due to false high opacity). To address these limitations, we propose a Localized Point Management (LPM) strategy, capable of identifying those error-contributing zones in the highest demand for both point addition and geometry calibration. Zone identification is achieved by leveraging the underlying multiview geometry constraints, with the guidance of image rendering errors. We apply point densification in the identified zone, whilst resetting the opacity of those points residing in front of these regions so that a new opportunity is created to correct ill-conditioned points. Serving as a versatile plugin, LPM can be seamlessly integrated into existing 3D Gaussian Splatting models. Experimental evaluation across both static 3D and dynamic 4D scenes validate the efficacy of our LPM strategy in boosting a variety of existing 3DGS models both quantitatively and qualitatively. Notably, LPM improves both vanilla 3DGS and SpaceTimeGS to achieve state-of-the-art rendering quality while retaining real-time speeds, outperforming on challenging datasets such as Tanks & Temples and the Neural 3D Video Dataset.
ANIM: Accurate Neural Implicit Model for Human Reconstruction from a single RGB-D image
Mar 18, 2024



Recent progress in human shape learning, shows that neural implicit models are effective in generating 3D human surfaces from limited number of views, and even from a single RGB image. However, existing monocular approaches still struggle to recover fine geometric details such as face, hands or cloth wrinkles. They are also easily prone to depth ambiguities that result in distorted geometries along the camera optical axis. In this paper, we explore the benefits of incorporating depth observations in the reconstruction process by introducing ANIM, a novel method that reconstructs arbitrary 3D human shapes from single-view RGB-D images with an unprecedented level of accuracy. Our model learns geometric details from both multi-resolution pixel-aligned and voxel-aligned features to leverage depth information and enable spatial relationships, mitigating depth ambiguities. We further enhance the quality of the reconstructed shape by introducing a depth-supervision strategy, which improves the accuracy of the signed distance field estimation of points that lie on the reconstructed surface. Experiments demonstrate that ANIM outperforms state-of-the-art works that use RGB, surface normals, point cloud or RGB-D data as input. In addition, we introduce ANIM-Real, a new multi-modal dataset comprising high-quality scans paired with consumer-grade RGB-D camera, and our protocol to fine-tune ANIM, enabling high-quality reconstruction from real-world human capture.
Tragic Talkers: A Shakespearean Sound- and Light-Field Dataset for Audio-Visual Machine Learning Research
Dec 04, 2022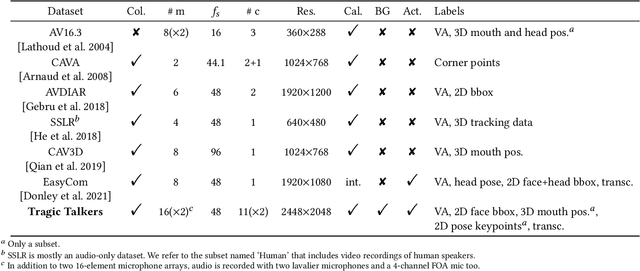

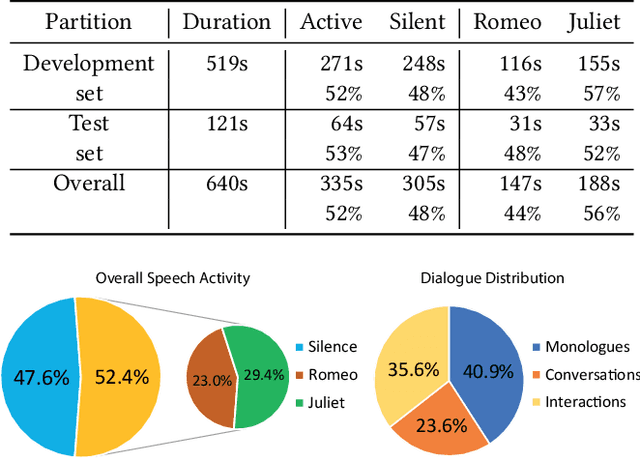
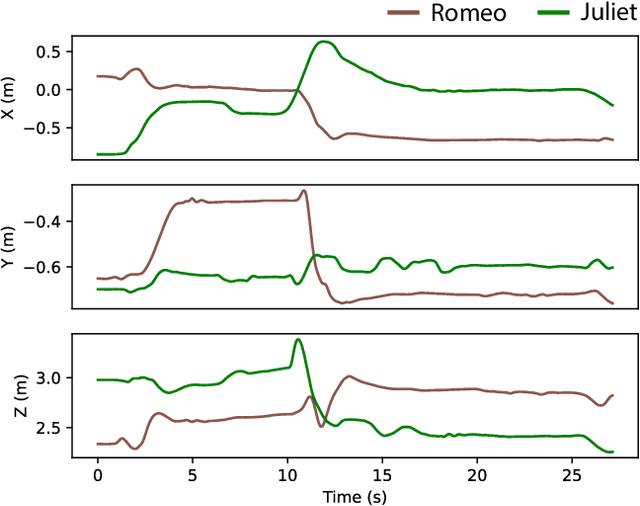
3D audio-visual production aims to deliver immersive and interactive experiences to the consumer. Yet, faithfully reproducing real-world 3D scenes remains a challenging task. This is partly due to the lack of available datasets enabling audio-visual research in this direction. In most of the existing multi-view datasets, the accompanying audio is neglected. Similarly, datasets for spatial audio research primarily offer unimodal content, and when visual data is included, the quality is far from meeting the standard production needs. We present "Tragic Talkers", an audio-visual dataset consisting of excerpts from the "Romeo and Juliet" drama captured with microphone arrays and multiple co-located cameras for light-field video. Tragic Talkers provides ideal content for object-based media (OBM) production. It is designed to cover various conventional talking scenarios, such as monologues, two-people conversations, and interactions with considerable movement and occlusion, yielding 30 sequences captured from a total of 22 different points of view and two 16-element microphone arrays. Additionally, we provide voice activity labels, 2D face bounding boxes for each camera view, 2D pose detection keypoints, 3D tracking data of the mouth of the actors, and dialogue transcriptions. We believe the community will benefit from this dataset as it can assist multidisciplinary research. Possible uses of the dataset are discussed.
Super-resolution 3D Human Shape from a Single Low-Resolution Image
Aug 23, 2022
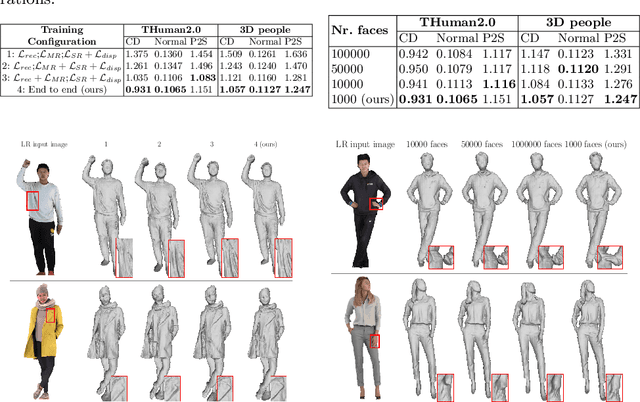
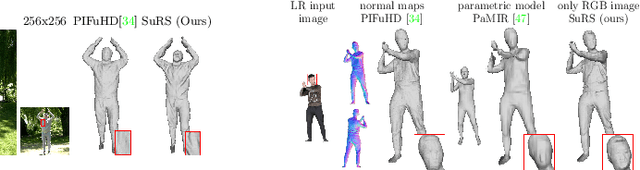
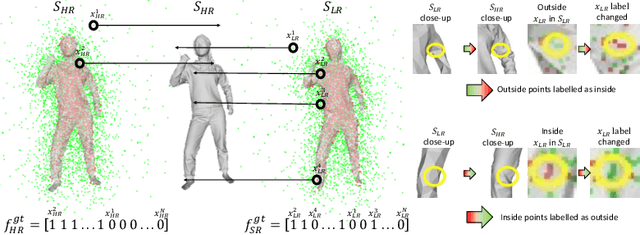
We propose a novel framework to reconstruct super-resolution human shape from a single low-resolution input image. The approach overcomes limitations of existing approaches that reconstruct 3D human shape from a single image, which require high-resolution images together with auxiliary data such as surface normal or a parametric model to reconstruct high-detail shape. The proposed framework represents the reconstructed shape with a high-detail implicit function. Analogous to the objective of 2D image super-resolution, the approach learns the mapping from a low-resolution shape to its high-resolution counterpart and it is applied to reconstruct 3D shape detail from low-resolution images. The approach is trained end-to-end employing a novel loss function which estimates the information lost between a low and high-resolution representation of the same 3D surface shape. Evaluation for single image reconstruction of clothed people demonstrates that our method achieves high-detail surface reconstruction from low-resolution images without auxiliary data. Extensive experiments show that the proposed approach can estimate super-resolution human geometries with a significantly higher level of detail than that obtained with previous approaches when applied to low-resolution images.
Super-Resolution Appearance Transfer for 4D Human Performances
Aug 31, 2021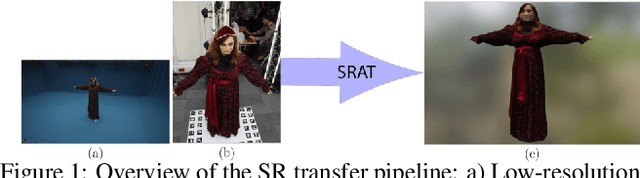
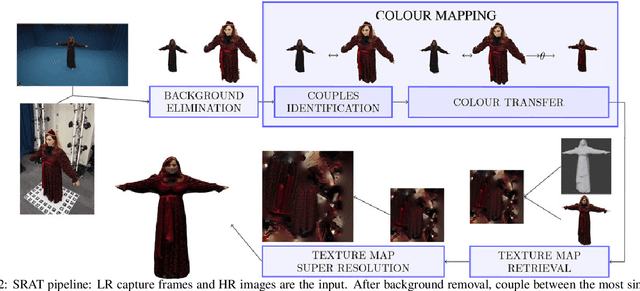
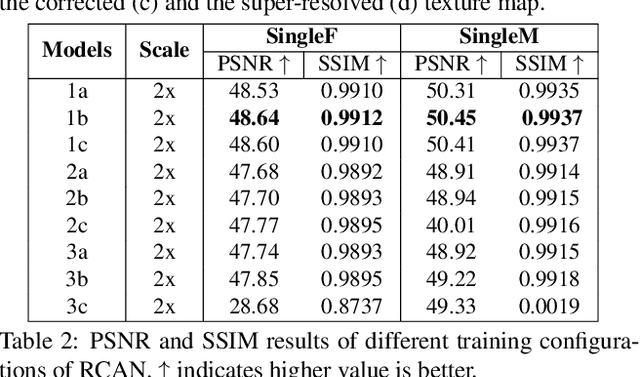

A common problem in the 4D reconstruction of people from multi-view video is the quality of the captured dynamic texture appearance which depends on both the camera resolution and capture volume. Typically the requirement to frame cameras to capture the volume of a dynamic performance ($>50m^3$) results in the person occupying only a small proportion $<$ 10% of the field of view. Even with ultra high-definition 4k video acquisition this results in sampling the person at less-than standard definition 0.5k video resolution resulting in low-quality rendering. In this paper we propose a solution to this problem through super-resolution appearance transfer from a static high-resolution appearance capture rig using digital stills cameras ($> 8k$) to capture the person in a small volume ($<8m^3$). A pipeline is proposed for super-resolution appearance transfer from high-resolution static capture to dynamic video performance capture to produce super-resolution dynamic textures. This addresses two key problems: colour mapping between different camera systems; and dynamic texture map super-resolution using a learnt model. Comparative evaluation demonstrates a significant qualitative and quantitative improvement in rendering the 4D performance capture with super-resolution dynamic texture appearance. The proposed approach reproduces the high-resolution detail of the static capture whilst maintaining the appearance dynamics of the captured video.
Attention-based Multi-Reference Learning for Image Super-Resolution
Aug 31, 2021
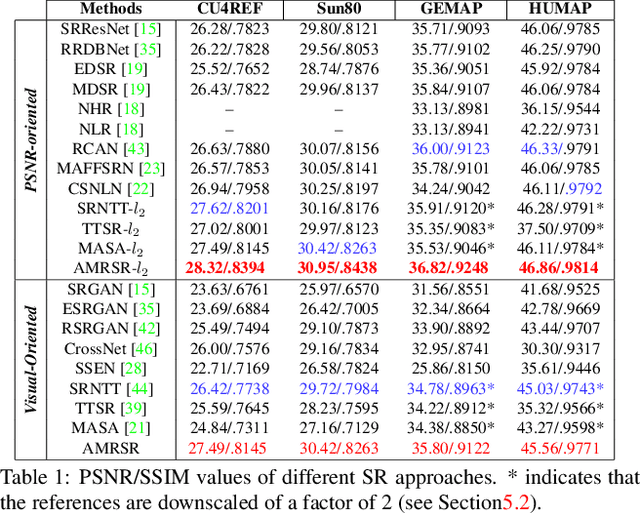
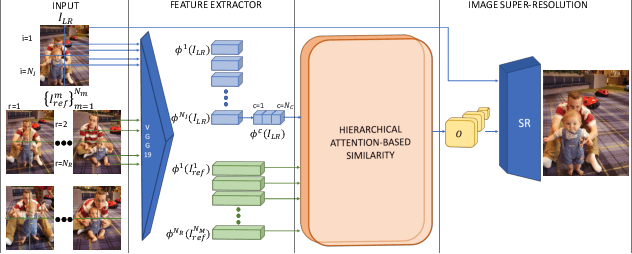
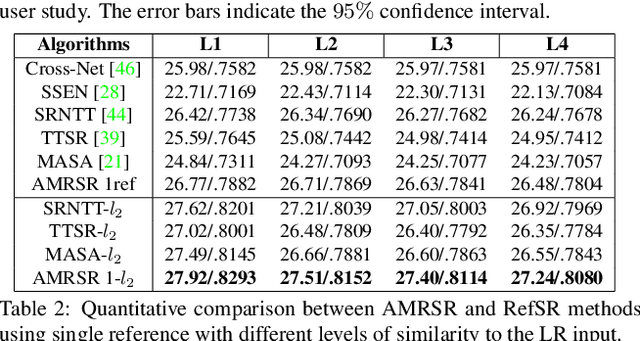
This paper proposes a novel Attention-based Multi-Reference Super-resolution network (AMRSR) that, given a low-resolution image, learns to adaptively transfer the most similar texture from multiple reference images to the super-resolution output whilst maintaining spatial coherence. The use of multiple reference images together with attention-based sampling is demonstrated to achieve significantly improved performance over state-of-the-art reference super-resolution approaches on multiple benchmark datasets. Reference super-resolution approaches have recently been proposed to overcome the ill-posed problem of image super-resolution by providing additional information from a high-resolution reference image. Multi-reference super-resolution extends this approach by providing a more diverse pool of image features to overcome the inherent information deficit whilst maintaining memory efficiency. A novel hierarchical attention-based sampling approach is introduced to learn the similarity between low-resolution image features and multiple reference images based on a perceptual loss. Ablation demonstrates the contribution of both multi-reference and hierarchical attention-based sampling to overall performance. Perceptual and quantitative ground-truth evaluation demonstrates significant improvement in performance even when the reference images deviate significantly from the target image. The project website can be found at https://marcopesavento.github.io/AMRSR/