 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCR-Bionic Hand: Anatomical Structural Priors for Dexterous Manipulation
Jun 11, 2026Dexterous robotic hands are usually formulated as high dimensional active control systems governed by degrees of freedom, actuation, and algorithms. Human hand dexterity, however, is partly encoded in the physical architecture of bones, ligaments, tendons, aponeuroses, and intrinsic muscles. This work describes that contribution as two linked forms of structural intelligence: structural prior generation, in which wrist to finger tenodesis, FDS/FDP routing, and the dorsal extensor hood transform low dimensional posture inputs into default grasp configurations and PIP to DIP coordination; and muscle mediated modulation, in which extrinsic muscles, lumbricals, and interossei regulate MCP posture, distal stability, fingertip force paths, and contact states around that default state. Based on this framework, MCR-Bionic Hand is developed as a 1:1 musculoskeletal biomimetic hand integrating a two row eight bone wrist, cross wrist tendons, anatomical flexor routing, volar plate and collateral ligament constraints, the dorsal extensor hood, and intrinsic muscle pathways within one body. Functional demonstrations and geometric mechanical models show that wrist posture induces multi joint pre shaping, the extensor hood maps PIP posture to a coupled DIP response, and intrinsic plus pathways modulate distal stability and fingertip action direction after grasp formation. Contact rich tasks, including coin rotation, pen transfer, dorsal coin flipping, and cube manipulation, show that MCR-Bionic links low dimensional state generation with fine post contact modulation. These results suggest that anatomical biomimetics is valuable not for visual similarity, but for identifying human hand structures that perform part of control.
Dynamic Avatar-Scene Rendering from Human-centric Context
Nov 13, 2025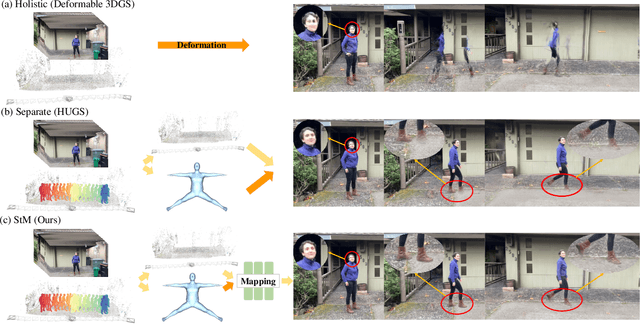
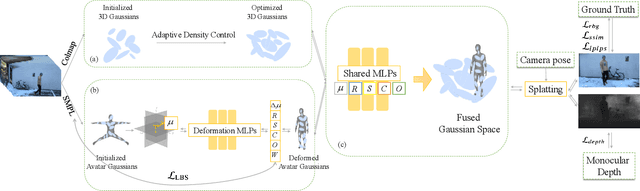


Reconstructing dynamic humans interacting with real-world environments from monocular videos is an important and challenging task. Despite considerable progress in 4D neural rendering, existing approaches either model dynamic scenes holistically or model scenes and backgrounds separately aim to introduce parametric human priors. However, these approaches either neglect distinct motion characteristics of various components in scene especially human, leading to incomplete reconstructions, or ignore the information exchange between the separately modeled components, resulting in spatial inconsistencies and visual artifacts at human-scene boundaries. To address this, we propose {\bf Separate-then-Map} (StM) strategy that introduces a dedicated information mapping mechanism to bridge separately defined and optimized models. Our method employs a shared transformation function for each Gaussian attribute to unify separately modeled components, enhancing computational efficiency by avoiding exhaustive pairwise interactions while ensuring spatial and visual coherence between humans and their surroundings. Extensive experiments on monocular video datasets demonstrate that StM significantly outperforms existing state-of-the-art methods in both visual quality and rendering accuracy, particularly at challenging human-scene interaction boundaries.
PathoPainter: Augmenting Histopathology Segmentation via Tumor-aware Inpainting
Mar 06, 2025



Tumor segmentation plays a critical role in histopathology, but it requires costly, fine-grained image-mask pairs annotated by pathologists. Thus, synthesizing histopathology data to expand the dataset is highly desirable. Previous works suffer from inaccuracies and limited diversity in image-mask pairs, both of which affect training segmentation, particularly in small-scale datasets and the inherently complex nature of histopathology images. To address this challenge, we propose PathoPainter, which reformulates image-mask pair generation as a tumor inpainting task. Specifically, our approach preserves the background while inpainting the tumor region, ensuring precise alignment between the generated image and its corresponding mask. To enhance dataset diversity while maintaining biological plausibility, we incorporate a sampling mechanism that conditions tumor inpainting on regional embeddings from a different image. Additionally, we introduce a filtering strategy to exclude uncertain synthetic regions, further improving the quality of the generated data. Our comprehensive evaluation spans multiple datasets featuring diverse tumor types and various training data scales. As a result, segmentation improved significantly with our synthetic data, surpassing existing segmentation data synthesis approaches, e.g., 75.69% -> 77.69% on CAMELYON16. The code is available at https://github.com/HongLiuuuuu/PathoPainter.
Adaptive Prototype Learning for Multimodal Cancer Survival Analysis
Mar 06, 2025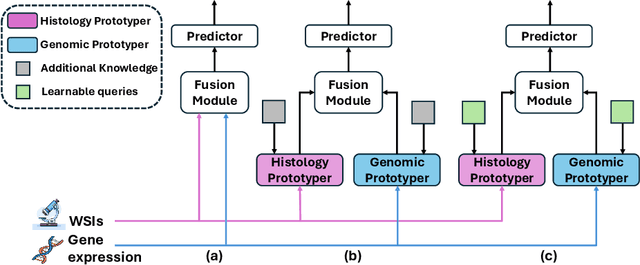



Leveraging multimodal data, particularly the integration of whole-slide histology images (WSIs) and transcriptomic profiles, holds great promise for improving cancer survival prediction. However, excessive redundancy in multimodal data can degrade model performance. In this paper, we propose Adaptive Prototype Learning (APL), a novel and effective approach for multimodal cancer survival analysis. APL adaptively learns representative prototypes in a data-driven manner, reducing redundancy while preserving critical information. Our method employs two sets of learnable query vectors that serve as a bridge between high-dimensional representations and survival prediction, capturing task-relevant features. Additionally, we introduce a multimodal mixed self-attention mechanism to enable cross-modal interactions, further enhancing information fusion. Extensive experiments on five benchmark cancer datasets demonstrate the superiority of our approach over existing methods. The code is available at https://github.com/HongLiuuuuu/APL.
FAM Diffusion: Frequency and Attention Modulation for High-Resolution Image Generation with Stable Diffusion
Nov 27, 2024



Diffusion models are proficient at generating high-quality images. They are however effective only when operating at the resolution used during training. Inference at a scaled resolution leads to repetitive patterns and structural distortions. Retraining at higher resolutions quickly becomes prohibitive. Thus, methods enabling pre-existing diffusion models to operate at flexible test-time resolutions are highly desirable. Previous works suffer from frequent artifacts and often introduce large latency overheads. We propose two simple modules that combine to solve these issues. We introduce a Frequency Modulation (FM) module that leverages the Fourier domain to improve the global structure consistency, and an Attention Modulation (AM) module which improves the consistency of local texture patterns, a problem largely ignored in prior works. Our method, coined Fam diffusion, can seamlessly integrate into any latent diffusion model and requires no additional training. Extensive qualitative results highlight the effectiveness of our method in addressing structural and local artifacts, while quantitative results show state-of-the-art performance. Also, our method avoids redundant inference tricks for improved consistency such as patch-based or progressive generation, leading to negligible latency overheads.
Single Image, Any Face: Generalisable 3D Face Generation
Sep 25, 2024

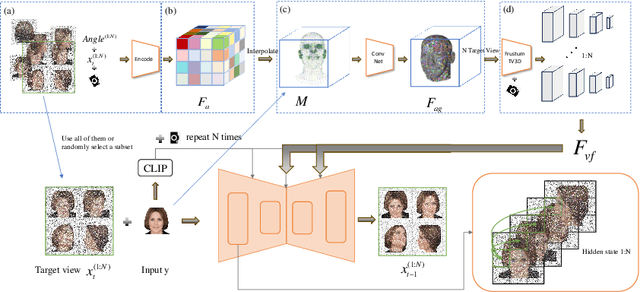

The creation of 3D human face avatars from a single unconstrained image is a fundamental task that underlies numerous real-world vision and graphics applications. Despite the significant progress made in generative models, existing methods are either less suited in design for human faces or fail to generalise from the restrictive training domain to unconstrained facial images. To address these limitations, we propose a novel model, Gen3D-Face, which generates 3D human faces with unconstrained single image input within a multi-view consistent diffusion framework. Given a specific input image, our model first produces multi-view images, followed by neural surface construction. To incorporate face geometry information in a generalisable manner, we utilise input-conditioned mesh estimation instead of ground-truth mesh along with synthetic multi-view training data. Importantly, we introduce a multi-view joint generation scheme to enhance appearance consistency among different views. To the best of our knowledge, this is the first attempt and benchmark for creating photorealistic 3D human face avatars from single images for generic human subject across domains. Extensive experiments demonstrate the superiority of our method over previous alternatives for out-of-domain singe image 3D face generation and top competition for in-domain setting.
FrozenSeg: Harmonizing Frozen Foundation Models for Open-Vocabulary Segmentation
Sep 05, 2024



Open-vocabulary segmentation poses significant challenges, as it requires segmenting and recognizing objects across an open set of categories in unconstrained environments. Building on the success of powerful vision-language (ViL) foundation models, such as CLIP, recent efforts sought to harness their zero-short capabilities to recognize unseen categories. Despite notable performance improvements, these models still encounter the critical issue of generating precise mask proposals for unseen categories and scenarios, resulting in inferior segmentation performance eventually. To address this challenge, we introduce a novel approach, FrozenSeg, designed to integrate spatial knowledge from a localization foundation model (e.g., SAM) and semantic knowledge extracted from a ViL model (e.g., CLIP), in a synergistic framework. Taking the ViL model's visual encoder as the feature backbone, we inject the space-aware feature into the learnable queries and CLIP features within the transformer decoder. In addition, we devise a mask proposal ensemble strategy for further improving the recall rate and mask quality. To fully exploit pre-trained knowledge while minimizing training overhead, we freeze both foundation models, focusing optimization efforts solely on a lightweight transformer decoder for mask proposal generation-the performance bottleneck. Extensive experiments demonstrate that FrozenSeg advances state-of-the-art results across various segmentation benchmarks, trained exclusively on COCO panoptic data, and tested in a zero-shot manner. Code is available at https://github.com/chenxi52/FrozenSeg.
AV-GS: Learning Material and Geometry Aware Priors for Novel View Acoustic Synthesis
Jun 14, 2024



Novel view acoustic synthesis (NVAS) aims to render binaural audio at any target viewpoint, given a mono audio emitted by a sound source at a 3D scene. Existing methods have proposed NeRF-based implicit models to exploit visual cues as a condition for synthesizing binaural audio. However, in addition to low efficiency originating from heavy NeRF rendering, these methods all have a limited ability of characterizing the entire scene environment such as room geometry, material properties, and the spatial relation between the listener and sound source. To address these issues, we propose a novel Audio-Visual Gaussian Splatting (AV-GS) model. To obtain a material-aware and geometry-aware condition for audio synthesis, we learn an explicit point-based scene representation with an audio-guidance parameter on locally initialized Gaussian points, taking into account the space relation from the listener and sound source. To make the visual scene model audio adaptive, we propose a point densification and pruning strategy to optimally distribute the Gaussian points, with the per-point contribution in sound propagation (e.g., more points needed for texture-less wall surfaces as they affect sound path diversion). Extensive experiments validate the superiority of our AV-GS over existing alternatives on the real-world RWAS and simulation-based SoundSpaces datasets.
Gaussian Splatting with Localized Points Management
Jun 13, 2024
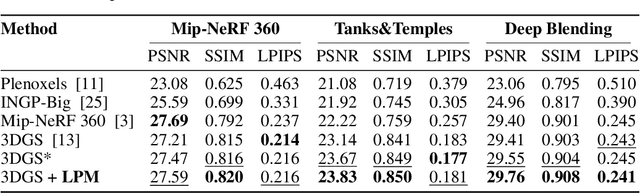
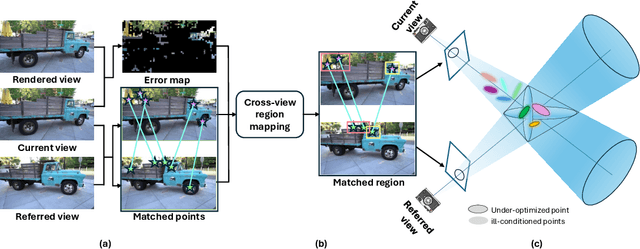

Point management is a critical component in optimizing 3D Gaussian Splatting (3DGS) models, as the point initiation (e.g., via structure from motion) is distributionally inappropriate. Typically, the Adaptive Density Control (ADC) algorithm is applied, leveraging view-averaged gradient magnitude thresholding for point densification, opacity thresholding for pruning, and regular all-points opacity reset. However, we reveal that this strategy is limited in tackling intricate/special image regions (e.g., transparent) as it is unable to identify all the 3D zones that require point densification, and lacking an appropriate mechanism to handle the ill-conditioned points with negative impacts (occlusion due to false high opacity). To address these limitations, we propose a Localized Point Management (LPM) strategy, capable of identifying those error-contributing zones in the highest demand for both point addition and geometry calibration. Zone identification is achieved by leveraging the underlying multiview geometry constraints, with the guidance of image rendering errors. We apply point densification in the identified zone, whilst resetting the opacity of those points residing in front of these regions so that a new opportunity is created to correct ill-conditioned points. Serving as a versatile plugin, LPM can be seamlessly integrated into existing 3D Gaussian Splatting models. Experimental evaluation across both static 3D and dynamic 4D scenes validate the efficacy of our LPM strategy in boosting a variety of existing 3DGS models both quantitatively and qualitatively. Notably, LPM improves both vanilla 3DGS and SpaceTimeGS to achieve state-of-the-art rendering quality while retaining real-time speeds, outperforming on challenging datasets such as Tanks & Temples and the Neural 3D Video Dataset.
Localized Gaussian Point Management
Jun 06, 2024Point management is a critical component in optimizing 3D Gaussian Splatting (3DGS) models, as the point initiation (e.g., via structure from motion) is distributionally inappropriate. Typically, the Adaptive Density Control (ADC) algorithm is applied, leveraging view-averaged gradient magnitude thresholding for point densification, opacity thresholding for pruning, and regular all-points opacity reset. However, we reveal that this strategy is limited in tackling intricate/special image regions (e.g., transparent) as it is unable to identify all the 3D zones that require point densification, and lacking an appropriate mechanism to handle the ill-conditioned points with negative impacts (occlusion due to false high opacity). To address these limitations, we propose a Localized Point Management (LPM) strategy, capable of identifying those error-contributing zones in the highest demand for both point addition and geometry calibration. Zone identification is achieved by leveraging the underlying multiview geometry constraints, with the guidance of image rendering errors. We apply point densification in the identified zone, whilst resetting the opacity of those points residing in front of these regions so that a new opportunity is created to correct ill-conditioned points. Serving as a versatile plugin, LPM can be seamlessly integrated into existing 3D Gaussian Splatting models. Experimental evaluation across both static 3D and dynamic 4D scenes validate the efficacy of our LPM strategy in boosting a variety of existing 3DGS models both quantitatively and qualitatively. Notably, LPM improves both vanilla 3DGS and SpaceTimeGS to achieve state-of-the-art rendering quality while retaining real-time speeds, outperforming on challenging datasets such as Tanks & Temples and the Neural 3D Video Dataset.