 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Image, Any Face: Generalisable 3D Face Generation
Paper and Code
Sep 25, 2024

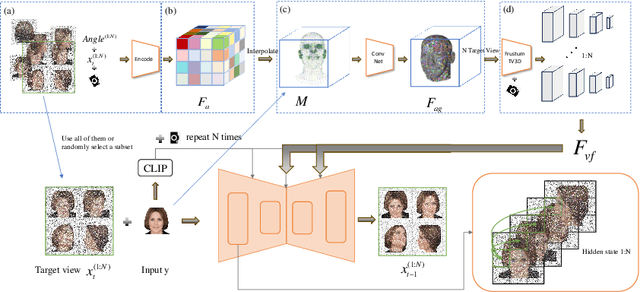

The creation of 3D human face avatars from a single unconstrained image is a fundamental task that underlies numerous real-world vision and graphics applications. Despite the significant progress made in generative models, existing methods are either less suited in design for human faces or fail to generalise from the restrictive training domain to unconstrained facial images. To address these limitations, we propose a novel model, Gen3D-Face, which generates 3D human faces with unconstrained single image input within a multi-view consistent diffusion framework. Given a specific input image, our model first produces multi-view images, followed by neural surface construction. To incorporate face geometry information in a generalisable manner, we utilise input-conditioned mesh estimation instead of ground-truth mesh along with synthetic multi-view training data. Importantly, we introduce a multi-view joint generation scheme to enhance appearance consistency among different views. To the best of our knowledge, this is the first attempt and benchmark for creating photorealistic 3D human face avatars from single images for generic human subject across domains. Extensive experiments demonstrate the superiority of our method over previous alternatives for out-of-domain singe image 3D face generation and top competition for in-domain setting.