 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToS: A Team of Specialists ensemble framework for Stereo Sound Event Localization and Detection with distance estimation in Video
Jan 24, 2026Sound event localization and detection with distance estimation (3D SELD) in video involves identifying active sound events at each time frame while estimating their spatial coordinates. This multimodal task requires joint reasoning across semantic, spatial, and temporal dimensions, a challenge that single models often struggle to address effectively. To tackle this, we introduce the Team of Specialists (ToS) ensemble framework, which integrates three complementary sub-networks: a spatio-linguistic model, a spatio-temporal model, and a tempo-linguistic model. Each sub-network specializes in a unique pair of dimensions, contributing distinct insights to the final prediction, akin to a collaborative team with diverse expertise. ToS has been benchmarked against state-of-the-art audio-visual models for 3D SELD on the DCASE2025 Task 3 Stereo SELD development set, consistently outperforming existing methods across key metrics. Future work will extend this proof of concept by strengthening the specialists with appropriate tasks, training, and pre-training curricula.
Region-Specific Audio Tagging for Spatial Sound
Sep 11, 2025Audio tagging aims to label sound events appearing in an audio recording. In this paper, we propose region-specific audio tagging, a new task which labels sound events in a given region for spatial audio recorded by a microphone array. The region can be specified as an angular space or a distance from the microphone. We first study the performance of different combinations of spectral, spatial, and position features. Then we extend state-of-the-art audio tagging systems such as pre-trained audio neural networks (PANNs) and audio spectrogram transformer (AST) to the proposed region-specific audio tagging task. Experimental results on both the simulated and the real datasets show the feasibility of the proposed task and the effectiveness of the proposed method. Further experiments show that incorporating the directional features is beneficial for omnidirectional tagging.
Reverberation-based Features for Sound Event Localization and Detection with Distance Estimation
Apr 11, 2025Sound event localization and detection (SELD) involves predicting active sound event classes over time while estimating their positions. The localization subtask in SELD is usually treated as a direction of arrival estimation problem, ignoring source distance. Only recently, SELD was extended to 3D by incorporating distance estimation, enabling the prediction of sound event positions in 3D space (3D SELD). However, existing methods lack input features designed for distance estimation. We argue that reverberation encodes valuable information for this task. This paper introduces two novel feature formats for 3D SELD based on reverberation: one using direct-to-reverberant ratio (DRR) and another leveraging signal autocorrelation to provide the model with insights into early reflections. Pre-training on synthetic data improves relative distance error (RDE) and overall SELD score, with autocorrelation-based features reducing RDE by over 3 percentage points on the STARSS23 dataset. The code to extract the features is available at github.com/dberghi/SELD-distance-features.
Leveraging Reverberation and Visual Depth Cues for Sound Event Localization and Detection with Distance Estimation
Oct 29, 2024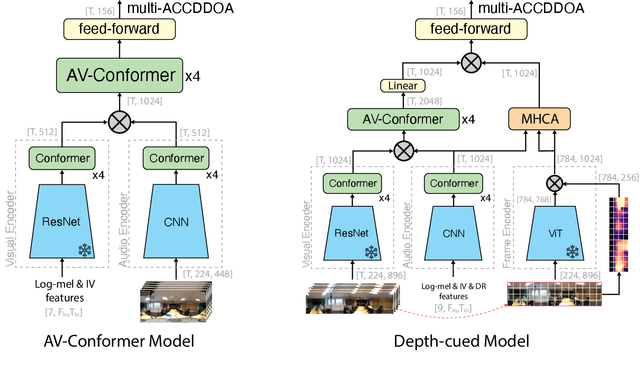
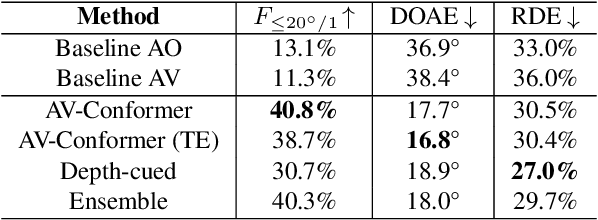


This report describes our systems submitted for the DCASE2024 Task 3 challenge: Audio and Audiovisual Sound Event Localization and Detection with Source Distance Estimation (Track B). Our main model is based on the audio-visual (AV) Conformer, which processes video and audio embeddings extracted with ResNet50 and with an audio encoder pre-trained on SELD, respectively. This model outperformed the audio-visual baseline of the development set of the STARSS23 dataset by a wide margin, halving its DOAE and improving the F1 by more than 3x. Our second system performs a temporal ensemble from the outputs of the AV-Conformer. We then extended the model with features for distance estimation, such as direct and reverberant signal components extracted from the omnidirectional audio channel, and depth maps extracted from the video frames. While the new system improved the RDE of our previous model by about 3 percentage points, it achieved a lower F1 score. This may be caused by sound classes that rarely appear in the training set and that the more complex system does not detect, as analysis can determine. To overcome this problem, our fourth and final system consists of an ensemble strategy combining the predictions of the other three. Many opportunities to refine the system and training strategy can be tested in future ablation experiments, and likely achieve incremental performance gains for this audio-visual task.
Text-Queried Target Sound Event Localization
Jun 23, 2024
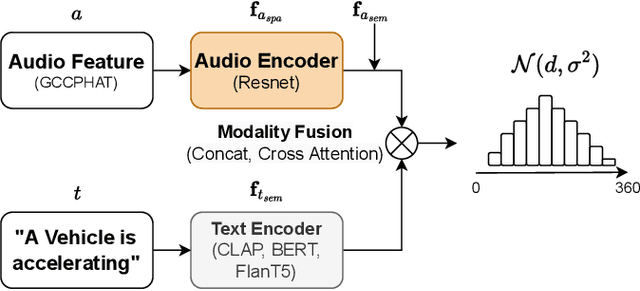
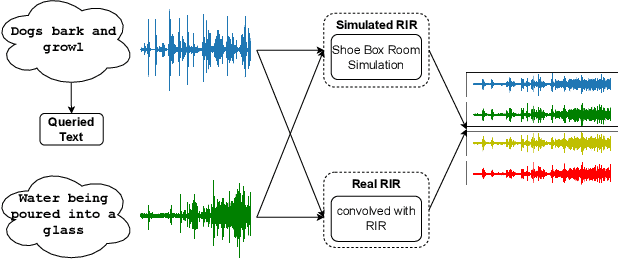
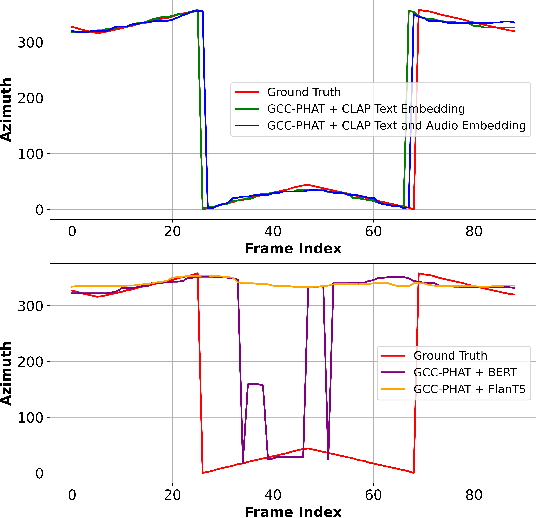
Sound event localization and detection (SELD) aims to determine the appearance of sound classes, together with their Direction of Arrival (DOA). However, current SELD systems can only predict the activities of specific classes, for example, 13 classes in DCASE challenges. In this paper, we propose text-queried target sound event localization (SEL), a new paradigm that allows the user to input the text to describe the sound event, and the SEL model can predict the location of the related sound event. The proposed task presents a more user-friendly way for human-computer interaction. We provide a benchmark study for the proposed task and perform experiments on datasets created by simulated room impulse response (RIR) and real RIR to validate the effectiveness of the proposed methods. We hope that our benchmark will inspire the interest and additional research for text-queried sound source localization.
Audio-Visual Talker Localization in Video for Spatial Sound Reproduction
Jun 01, 2024


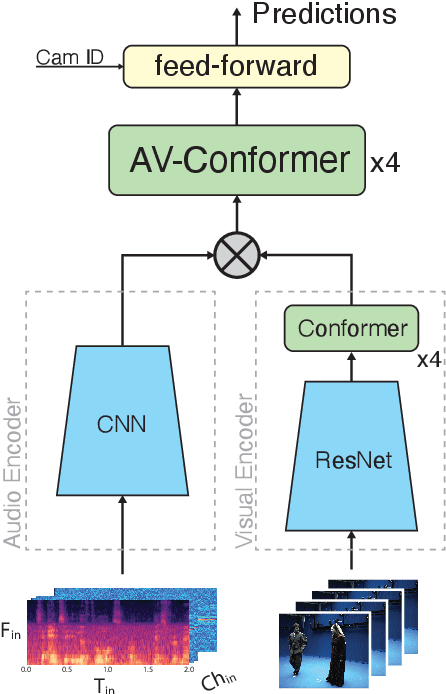
Object-based audio production requires the positional metadata to be defined for each point-source object, including the key elements in the foreground of the sound scene. In many media production use cases, both cameras and microphones are employed to make recordings, and the human voice is often a key element. In this research, we detect and locate the active speaker in the video, facilitating the automatic extraction of the positional metadata of the talker relative to the camera's reference frame. With the integration of the visual modality, this study expands upon our previous investigation focused solely on audio-based active speaker detection and localization. Our experiments compare conventional audio-visual approaches for active speaker detection that leverage monaural audio, our previous audio-only method that leverages multichannel recordings from a microphone array, and a novel audio-visual approach integrating vision and multichannel audio. We found the role of the two modalities to complement each other. Multichannel audio, overcoming the problem of visual occlusions, provides a double-digit reduction in detection error compared to audio-visual methods with single-channel audio. The combination of multichannel audio and vision further enhances spatial accuracy, leading to a four-percentage point increase in F1 score on the Tragic Talkers dataset. Future investigations will assess the robustness of the model in noisy and highly reverberant environments, as well as tackle the problem of off-screen speakers.
Leveraging Visual Supervision for Array-based Active Speaker Detection and Localization
Dec 21, 2023



Conventional audio-visual approaches for active speaker detection (ASD) typically rely on visually pre-extracted face tracks and the corresponding single-channel audio to find the speaker in a video. Therefore, they tend to fail every time the face of the speaker is not visible. We demonstrate that a simple audio convolutional recurrent neural network (CRNN) trained with spatial input features extracted from multichannel audio can perform simultaneous horizontal active speaker detection and localization (ASDL), independently of the visual modality. To address the time and cost of generating ground truth labels to train such a system, we propose a new self-supervised training pipeline that embraces a ``student-teacher'' learning approach. A conventional pre-trained active speaker detector is adopted as a ``teacher'' network to provide the position of the speakers as pseudo-labels. The multichannel audio ``student'' network is trained to generate the same results. At inference, the student network can generalize and locate also the occluded speakers that the teacher network is not able to detect visually, yielding considerable improvements in recall rate. Experiments on the TragicTalkers dataset show that an audio network trained with the proposed self-supervised learning approach can exceed the performance of the typical audio-visual methods and produce results competitive with the costly conventional supervised training. We demonstrate that improvements can be achieved when minimal manual supervision is introduced in the learning pipeline. Further gains may be sought with larger training sets and integrating vision with the multichannel audio system.
Fusion of Audio and Visual Embeddings for Sound Event Localization and Detection
Dec 14, 2023Sound event localization and detection (SELD) combines two subtasks: sound event detection (SED) and direction of arrival (DOA) estimation. SELD is usually tackled as an audio-only problem, but visual information has been recently included. Few audio-visual (AV)-SELD works have been published and most employ vision via face/object bounding boxes, or human pose keypoints. In contrast, we explore the integration of audio and visual feature embeddings extracted with pre-trained deep networks. For the visual modality, we tested ResNet50 and Inflated 3D ConvNet (I3D). Our comparison of AV fusion methods includes the AV-Conformer and Cross-Modal Attentive Fusion (CMAF) model. Our best models outperform the DCASE 2023 Task3 audio-only and AV baselines by a wide margin on the development set of the STARSS23 dataset, making them competitive amongst state-of-the-art results of the AV challenge, without model ensembling, heavy data augmentation, or prediction post-processing. Such techniques and further pre-training could be applied as next steps to improve performance.
Audio-Visual Speaker Tracking: Progress, Challenges, and Future Directions
Oct 23, 2023



Audio-visual speaker tracking has drawn increasing attention over the past few years due to its academic values and wide application. Audio and visual modalities can provide complementary information for localization and tracking. With audio and visual information, the Bayesian-based filter can solve the problem of data association, audio-visual fusion and track management. In this paper, we conduct a comprehensive overview of audio-visual speaker tracking. To our knowledge, this is the first extensive survey over the past five years. We introduce the family of Bayesian filters and summarize the methods for obtaining audio-visual measurements. In addition, the existing trackers and their performance on AV16.3 dataset are summarized. In the past few years, deep learning techniques have thrived, which also boosts the development of audio visual speaker tracking. The influence of deep learning techniques in terms of measurement extraction and state estimation is also discussed. At last, we discuss the connections between audio-visual speaker tracking and other areas such as speech separation and distributed speaker tracking.
Audio Inputs for Active Speaker Detection and Localization via Microphone Array
Jul 27, 2023
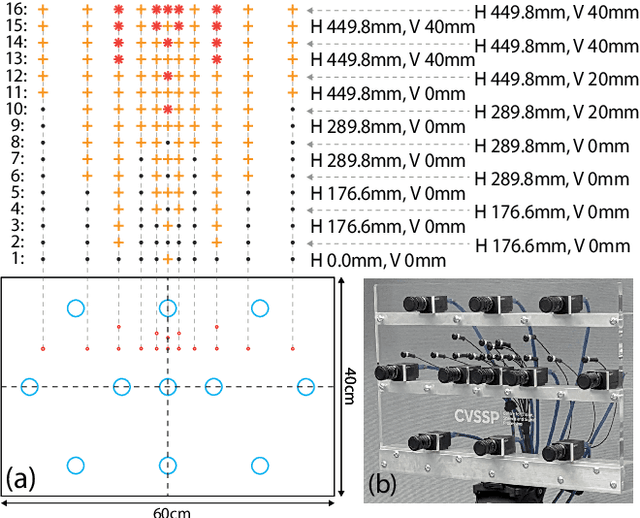

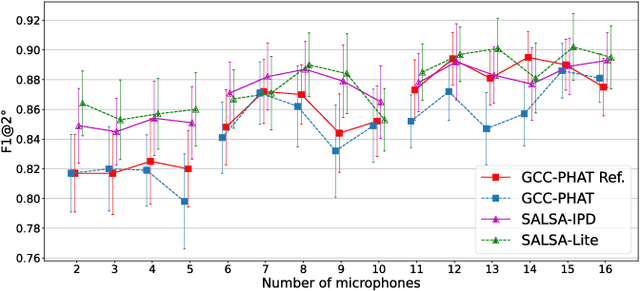
This study considers the problem of detecting and locating an active talker's horizontal position from multichannel audio captured by a microphone array. We refer to this as active speaker detection and localization (ASDL). Our goal was to investigate the performance of spatial acoustic features extracted from the multichannel audio as the input of a convolutional recurrent neural network (CRNN), in relation to the number of channels employed and additive noise. To this end, experiments were conducted to compare the generalized cross-correlation with phase transform (GCC-PHAT), the spatial cue-augmented log-spectrogram (SALSA) features, and a recently-proposed beamforming method, evaluating their robustness to various noise intensities. The array aperture and sampling density were tested by taking subsets from the 16-microphone array. Results and tests of statistical significance demonstrate the microphones' contribution to performance on the TragicTalkers dataset, which offers opportunities to investigate audio-visual approaches in the future.