 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Talker Localization in Video for Spatial Sound Reproduction
Paper and Code
Jun 01, 2024


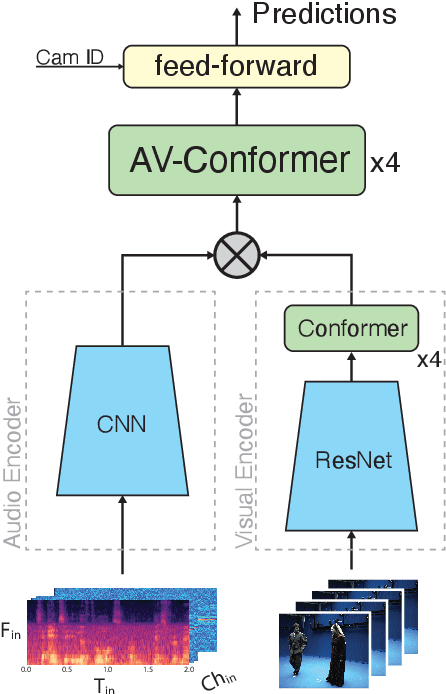
Object-based audio production requires the positional metadata to be defined for each point-source object, including the key elements in the foreground of the sound scene. In many media production use cases, both cameras and microphones are employed to make recordings, and the human voice is often a key element. In this research, we detect and locate the active speaker in the video, facilitating the automatic extraction of the positional metadata of the talker relative to the camera's reference frame. With the integration of the visual modality, this study expands upon our previous investigation focused solely on audio-based active speaker detection and localization. Our experiments compare conventional audio-visual approaches for active speaker detection that leverage monaural audio, our previous audio-only method that leverages multichannel recordings from a microphone array, and a novel audio-visual approach integrating vision and multichannel audio. We found the role of the two modalities to complement each other. Multichannel audio, overcoming the problem of visual occlusions, provides a double-digit reduction in detection error compared to audio-visual methods with single-channel audio. The combination of multichannel audio and vision further enhances spatial accuracy, leading to a four-percentage point increase in F1 score on the Tragic Talkers dataset. Future investigations will assess the robustness of the model in noisy and highly reverberant environments, as well as tackle the problem of off-screen speakers.