 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Inputs for Active Speaker Detection and Localization via Microphone Array
Paper and Code
Jul 27, 2023
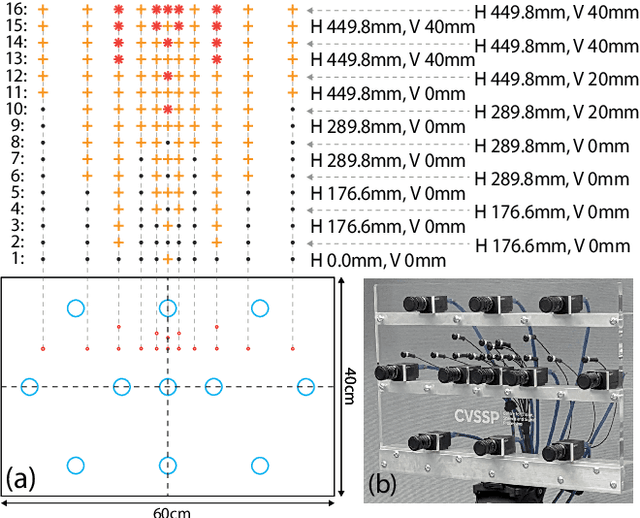

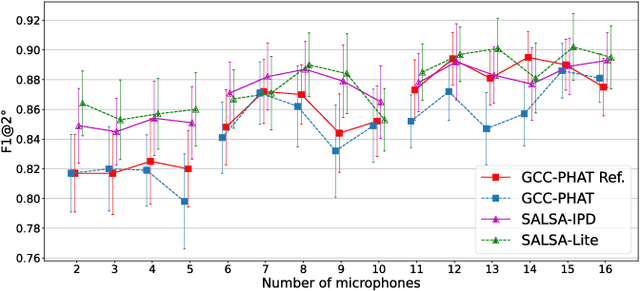
This study considers the problem of detecting and locating an active talker's horizontal position from multichannel audio captured by a microphone array. We refer to this as active speaker detection and localization (ASDL). Our goal was to investigate the performance of spatial acoustic features extracted from the multichannel audio as the input of a convolutional recurrent neural network (CRNN), in relation to the number of channels employed and additive noise. To this end, experiments were conducted to compare the generalized cross-correlation with phase transform (GCC-PHAT), the spatial cue-augmented log-spectrogram (SALSA) features, and a recently-proposed beamforming method, evaluating their robustness to various noise intensities. The array aperture and sampling density were tested by taking subsets from the 16-microphone array. Results and tests of statistical significance demonstrate the microphones' contribution to performance on the TragicTalkers dataset, which offers opportunities to investigate audio-visual approaches in the future.