 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Queried Target Sound Event Localization
Paper and Code
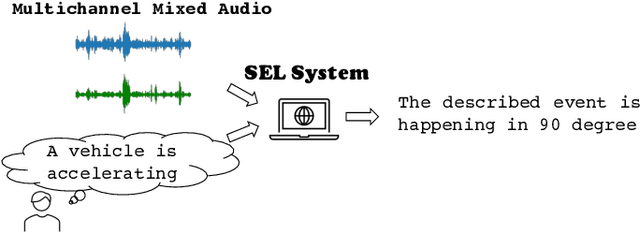
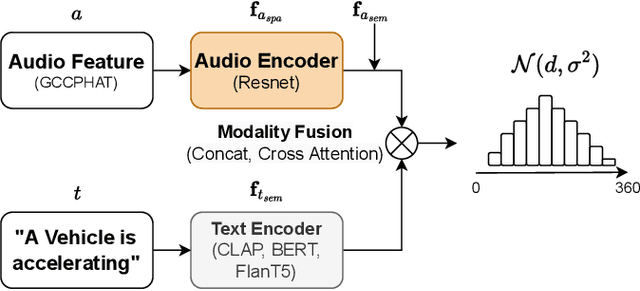
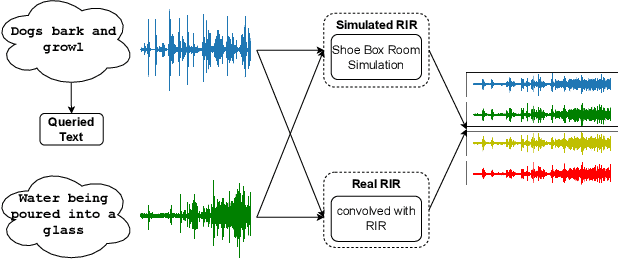
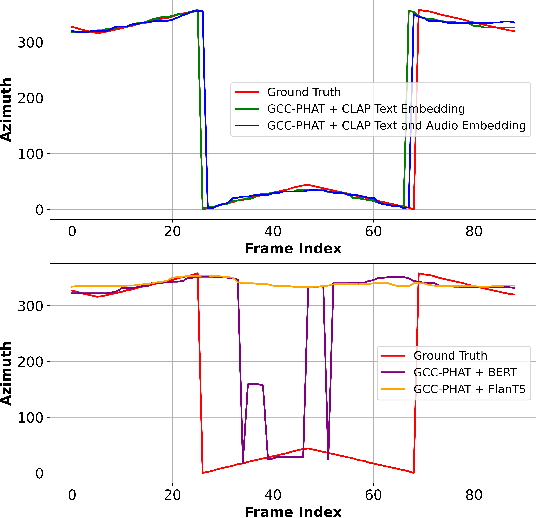
Sound event localization and detection (SELD) aims to determine the appearance of sound classes, together with their Direction of Arrival (DOA). However, current SELD systems can only predict the activities of specific classes, for example, 13 classes in DCASE challenges. In this paper, we propose text-queried target sound event localization (SEL), a new paradigm that allows the user to input the text to describe the sound event, and the SEL model can predict the location of the related sound event. The proposed task presents a more user-friendly way for human-computer interaction. We provide a benchmark study for the proposed task and perform experiments on datasets created by simulated room impulse response (RIR) and real RIR to validate the effectiveness of the proposed methods. We hope that our benchmark will inspire the interest and additional research for text-queried sound source localization.