 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSALM: Spatial Audio Language Model with Structured Embeddings for Understanding and Editing
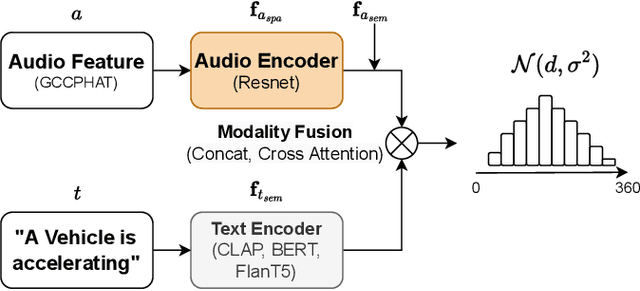
Jul 22, 2025Spatial audio understanding is essential for accurately perceiving and interpreting acoustic environments. However, existing audio-language models struggle with processing spatial audio and perceiving spatial acoustic scenes. We introduce the Spatial Audio Language Model (SALM), a novel framework that bridges spatial audio and language via multi-modal contrastive learning. SALM consists of a text encoder and a dual-branch audio encoder, decomposing spatial sound into semantic and spatial components through structured audio embeddings. Key features of SALM include seamless alignment of spatial and text representations, separate and joint extraction of spatial and semantic information, zero-shot direction classification and robust support for spatial audio editing. Experimental results demonstrate that SALM effectively captures and aligns cross-modal representations. Furthermore, it supports advanced editing capabilities, such as altering directional audio using text-based embeddings.
PSELDNets: Pre-trained Neural Networks on Large-scale Synthetic Datasets for Sound Event Localization and Detection
Nov 10, 2024



Sound event localization and detection (SELD) has seen substantial advancements through learning-based methods. These systems, typically trained from scratch on specific datasets, have shown considerable generalization capabilities. Recently, deep neural networks trained on large-scale datasets have achieved remarkable success in the sound event classification (SEC) field, prompting an open question of whether these advancements can be extended to develop general-purpose SELD models. In this paper, leveraging the power of pre-trained SEC models, we propose pre-trained SELD networks (PSELDNets) on large-scale synthetic datasets. These synthetic datasets, generated by convolving sound events with simulated spatial room impulse responses (SRIRs), contain 1,167 hours of audio clips with an ontology of 170 sound classes. These PSELDNets are transferred to downstream SELD tasks. When we adapt PSELDNets to specific scenarios, particularly in low-resource data cases, we introduce a data-efficient fine-tuning method, AdapterBit. PSELDNets are evaluated on a synthetic-test-set using collected SRIRs from TAU Spatial Room Impulse Response Database (TAU-SRIR DB) and achieve satisfactory performance. We also conduct our experiments to validate the transferability of PSELDNets to three publicly available datasets and our own collected audio recordings. Results demonstrate that PSELDNets surpass state-of-the-art systems across all publicly available datasets. Given the need for direction-of-arrival estimation, SELD generally relies on sufficient multi-channel audio clips. However, incorporating the AdapterBit, PSELDNets show more efficient adaptability to various tasks using minimal multi-channel or even just monophonic audio clips, outperforming the traditional fine-tuning approaches.
Text-Queried Target Sound Event Localization
Jun 23, 2024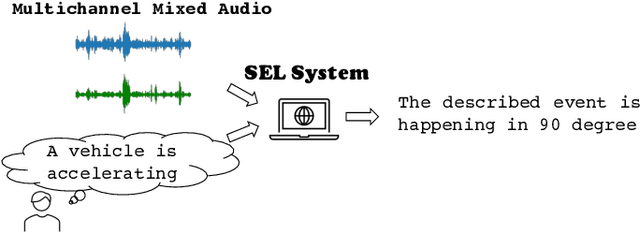
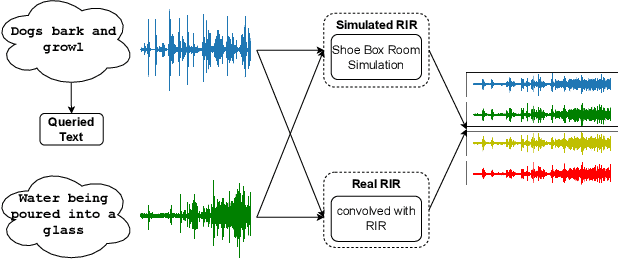
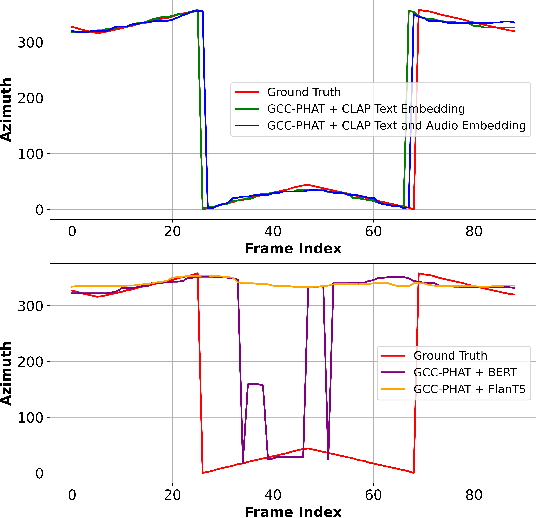
Sound event localization and detection (SELD) aims to determine the appearance of sound classes, together with their Direction of Arrival (DOA). However, current SELD systems can only predict the activities of specific classes, for example, 13 classes in DCASE challenges. In this paper, we propose text-queried target sound event localization (SEL), a new paradigm that allows the user to input the text to describe the sound event, and the SEL model can predict the location of the related sound event. The proposed task presents a more user-friendly way for human-computer interaction. We provide a benchmark study for the proposed task and perform experiments on datasets created by simulated room impulse response (RIR) and real RIR to validate the effectiveness of the proposed methods. We hope that our benchmark will inspire the interest and additional research for text-queried sound source localization.
Towards Out-of-Distribution Detection in Vocoder Recognition via Latent Feature Reconstruction
Jun 04, 2024



Advancements in synthesized speech have created a growing threat of impersonation, making it crucial to develop deepfake algorithm recognition. One significant aspect is out-of-distribution (OOD) detection, which has gained notable attention due to its important role in deepfake algorithm recognition. However, most of the current approaches for detecting OOD in deepfake algorithm recognition rely on probability-score or classified-distance, which may lead to limitations in the accuracy of the sample at the edge of the threshold. In this study, we propose a reconstruction-based detection approach that employs an autoencoder architecture to compress and reconstruct the acoustic feature extracted from a pre-trained WavLM model. Each acoustic feature belonging to a specific vocoder class is only aptly reconstructed by its corresponding decoder. When none of the decoders can satisfactorily reconstruct a feature, it is classified as an OOD sample. To enhance the distinctiveness of the reconstructed features by each decoder, we incorporate contrastive learning and an auxiliary classifier to further constrain the reconstructed feature. Experiments demonstrate that our proposed approach surpasses baseline systems by a relative margin of 10\% in the evaluation dataset. Ablation studies further validate the effectiveness of both the contrastive constraint and the auxiliary classifier within our proposed approach.
WavCraft: Audio Editing and Generation with Natural Language Prompts
Mar 15, 2024



We introduce WavCraft, a collective system that leverages large language models (LLMs) to connect diverse task-specific models for audio content creation and editing. Specifically, WavCraft describes the content of raw sound materials in natural language and prompts the LLM conditioned on audio descriptions and users' requests. WavCraft leverages the in-context learning ability of the LLM to decomposes users' instructions into several tasks and tackle each task collaboratively with audio expert modules. Through task decomposition along with a set of task-specific models, WavCraft follows the input instruction to create or edit audio content with more details and rationales, facilitating users' control. In addition, WavCraft is able to cooperate with users via dialogue interaction and even produce the audio content without explicit user commands. Experiments demonstrate that WavCraft yields a better performance than existing methods, especially when adjusting the local regions of audio clips. Moreover, WavCraft can follow complex instructions to edit and even create audio content on the top of input recordings, facilitating audio producers in a broader range of applications. Our implementation and demos are available at https://github.com/JinhuaLiang/WavCraft.
EDTC: enhance depth of text comprehension in automated audio captioning
Feb 27, 2024



Modality discrepancies have perpetually posed significant challenges within the realm of Automated Audio Captioning (AAC) and across all multi-modal domains. Facilitating models in comprehending text information plays a pivotal role in establishing a seamless connection between the two modalities of text and audio. While recent research has focused on closing the gap between these two modalities through contrastive learning, it is challenging to bridge the difference between both modalities using only simple contrastive loss. This paper introduces Enhance Depth of Text Comprehension (EDTC), which enhances the model's understanding of text information from three different perspectives. First, we propose a novel fusion module, FUSER, which aims to extract shared semantic information from different audio features through feature fusion. We then introduced TRANSLATOR, a novel alignment module designed to align audio features and text features along the tensor level. Finally, the weights are updated by adding momentum to the twin structure so that the model can learn information about both modalities at the same time. The resulting method achieves state-of-the-art performance on AudioCaps datasets and demonstrates results comparable to the state-of-the-art on Clotho datasets.
Selective-Memory Meta-Learning with Environment Representations for Sound Event Localization and Detection
Dec 27, 2023Environment shifts and conflicts present significant challenges for learning-based sound event localization and detection (SELD) methods. SELD systems, when trained in particular acoustic settings, often show restricted generalization capabilities for diverse acoustic environments. Furthermore, it is notably costly to obtain annotated samples for spatial sound events. Deploying a SELD system in a new environment requires extensive time for re-training and fine-tuning. To overcome these challenges, we propose environment-adaptive Meta-SELD, designed for efficient adaptation to new environments using minimal data. Our method specifically utilizes computationally synthesized spatial data and employs Model-Agnostic Meta-Learning (MAML) on a pre-trained, environment-independent model. The method then utilizes fast adaptation to unseen real-world environments using limited samples from the respective environments. Inspired by the Learning-to-Forget approach, we introduce the concept of selective memory as a strategy for resolving conflicts across environments. This approach involves selectively memorizing target-environment-relevant information and adapting to the new environments through the selective attenuation of model parameters. In addition, we introduce environment representations to characterize different acoustic settings, enhancing the adaptability of our attenuation approach to various environments. We evaluate our proposed method on the development set of the Sony-TAU Realistic Spatial Soundscapes 2023 (STARSS23) dataset and computationally synthesized scenes. Experimental results demonstrate the superior performance of the proposed method compared to conventional supervised learning methods, particularly in localization.
Balanced SNR-Aware Distillation for Guided Text-to-Audio Generation
Dec 25, 2023Diffusion models have demonstrated promising results in text-to-audio generation tasks. However, their practical usability is hindered by slow sampling speeds, limiting their applicability in high-throughput scenarios. To address this challenge, progressive distillation methods have been effective in producing more compact and efficient models. Nevertheless, these methods encounter issues with unbalanced weights at both high and low noise levels, potentially impacting the quality of generated samples. In this paper, we propose the adaptation of the progressive distillation method to text-to-audio generation tasks and introduce the Balanced SNR-Aware~(BSA) method, an enhanced loss-weighting mechanism for diffusion distillation. The BSA method employs a balanced approach to weight the loss for both high and low noise levels. We evaluate our proposed method on the AudioCaps dataset and report experimental results showing superior performance during the reverse diffusion process compared to previous distillation methods with the same number of sampling steps. Furthermore, the BSA method allows for a significant reduction in sampling steps from 200 to 25, with minimal performance degradation when compared to the original teacher models.
META-SELD: Meta-Learning for Fast Adaptation to the new environment in Sound Event Localization and Detection
Aug 17, 2023


For learning-based sound event localization and detection (SELD) methods, different acoustic environments in the training and test sets may result in large performance differences in the validation and evaluation stages. Different environments, such as different sizes of rooms, different reverberation times, and different background noise, may be reasons for a learning-based system to fail. On the other hand, acquiring annotated spatial sound event samples, which include onset and offset time stamps, class types of sound events, and direction-of-arrival (DOA) of sound sources is very expensive. In addition, deploying a SELD system in a new environment often poses challenges due to time-consuming training and fine-tuning processes. To address these issues, we propose Meta-SELD, which applies meta-learning methods to achieve fast adaptation to new environments. More specifically, based on Model Agnostic Meta-Learning (MAML), the proposed Meta-SELD aims to find good meta-initialized parameters to adapt to new environments with only a small number of samples and parameter updating iterations. We can then quickly adapt the meta-trained SELD model to unseen environments. Our experiments compare fine-tuning methods from pre-trained SELD models with our Meta-SELD on the Sony-TAU Realistic Spatial Soundscapes 2023 (STARSSS23) dataset. The evaluation results demonstrate the effectiveness of Meta-SELD when adapting to new environments.
WavJourney: Compositional Audio Creation with Large Language Models
Jul 26, 2023Large Language Models (LLMs) have shown great promise in integrating diverse expert models to tackle intricate language and vision tasks. Despite their significance in advancing the field of Artificial Intelligence Generated Content (AIGC), their potential in intelligent audio content creation remains unexplored. In this work, we tackle the problem of creating audio content with storylines encompassing speech, music, and sound effects, guided by text instructions. We present WavJourney, a system that leverages LLMs to connect various audio models for audio content generation. Given a text description of an auditory scene, WavJourney first prompts LLMs to generate a structured script dedicated to audio storytelling. The audio script incorporates diverse audio elements, organized based on their spatio-temporal relationships. As a conceptual representation of audio, the audio script provides an interactive and interpretable rationale for human engagement. Afterward, the audio script is fed into a script compiler, converting it into a computer program. Each line of the program calls a task-specific audio generation model or computational operation function (e.g., concatenate, mix). The computer program is then executed to obtain an explainable solution for audio generation. We demonstrate the practicality of WavJourney across diverse real-world scenarios, including science fiction, education, and radio play. The explainable and interactive design of WavJourney fosters human-machine co-creation in multi-round dialogues, enhancing creative control and adaptability in audio production. WavJourney audiolizes the human imagination, opening up new avenues for creativity in multimedia content creation.