 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoHeal: An End-to-End System for Personalized Therapeutic Music Retrieval from Fine-grained Emotions
Sep 19, 2025



Existing digital mental wellness tools often overlook the nuanced emotional states underlying everyday challenges. For example, pre-sleep anxiety affects more than 1.5 billion people worldwide, yet current approaches remain largely static and "one-size-fits-all", failing to adapt to individual needs. In this work, we present EmoHeal, an end-to-end system that delivers personalized, three-stage supportive narratives. EmoHeal detects 27 fine-grained emotions from user text with a fine-tuned XLM-RoBERTa model, mapping them to musical parameters via a knowledge graph grounded in music therapy principles (GEMS, iso-principle). EmoHeal retrieves audiovisual content using the CLAMP3 model to guide users from their current state toward a calmer one ("match-guide-target"). A within-subjects study (N=40) demonstrated significant supportive effects, with participants reporting substantial mood improvement (M=4.12, p<0.001) and high perceived emotion recognition accuracy (M=4.05, p<0.001). A strong correlation between perceived accuracy and therapeutic outcome (r=0.72, p<0.001) validates our fine-grained approach. These findings establish the viability of theory-driven, emotion-aware digital wellness tools and provides a scalable AI blueprint for operationalizing music therapy principles.
Emotion-Aware Speech Generation with Character-Specific Voices for Comics
Sep 18, 2025



This paper presents an end-to-end pipeline for generating character-specific, emotion-aware speech from comics. The proposed system takes full comic volumes as input and produces speech aligned with each character's dialogue and emotional state. An image processing module performs character detection, text recognition, and emotion intensity recognition. A large language model performs dialogue attribution and emotion analysis by integrating visual information with the evolving plot context. Speech is synthesized through a text-to-speech model with distinct voice profiles tailored to each character and emotion. This work enables automated voiceover generation for comics, offering a step toward interactive and immersive comic reading experience.
AudioMorphix: Training-free audio editing with diffusion probabilistic models
May 21, 2025



Editing sound with precision is a crucial yet underexplored challenge in audio content creation. While existing works can manipulate sounds by text instructions or audio exemplar pairs, they often struggled to modify audio content precisely while preserving fidelity to the original recording. In this work, we introduce a novel editing approach that enables localized modifications to specific time-frequency regions while keeping the remaining of the audio intact by operating on spectrograms directly. To achieve this, we propose AudioMorphix, a training-free audio editor that manipulates a target region on the spectrogram by referring to another recording. Inspired by morphing theory, we conceptualize audio mixing as a process where different sounds blend seamlessly through morphing and can be decomposed back into individual components via demorphing. Our AudioMorphix optimizes the noised latent conditioned on raw input and reference audio while rectifying the guided diffusion process through a series of energy functions. Additionally, we enhance self-attention layers with a cache mechanism to preserve detailed characteristics from the original recordings. To advance audio editing research, we devise a new evaluation benchmark, which includes a curated dataset with a variety of editing instructions. Extensive experiments demonstrate that AudioMorphix yields promising performance on various audio editing tasks, including addition, removal, time shifting and stretching, and pitch shifting, achieving high fidelity and precision. Demo and code are available at this url.
From Aesthetics to Human Preferences: Comparative Perspectives of Evaluating Text-to-Music Systems
Apr 30, 2025Evaluating generative models remains a fundamental challenge, particularly when the goal is to reflect human preferences. In this paper, we use music generation as a case study to investigate the gap between automatic evaluation metrics and human preferences. We conduct comparative experiments across five state-of-the-art music generation approaches, assessing both perceptual quality and distributional similarity to human-composed music. Specifically, we evaluate synthesis music from various perceptual dimensions and examine reference-based metrics such as Mauve Audio Divergence (MAD) and Kernel Audio Distance (KAD). Our findings reveal significant inconsistencies across the different metrics, highlighting the limitation of the current evaluation practice. To support further research, we release a benchmark dataset comprising samples from multiple models. This study provides a broader perspective on the alignment of human preference in generative modeling, advocating for more human-centered evaluation strategies across domains.
Hierarchical Symbolic Pop Music Generation with Graph Neural Networks
Sep 12, 2024



Music is inherently made up of complex structures, and representing them as graphs helps to capture multiple levels of relationships. While music generation has been explored using various deep generation techniques, research on graph-related music generation is sparse. Earlier graph-based music generation worked only on generating melodies, and recent works to generate polyphonic music do not account for longer-term structure. In this paper, we explore a multi-graph approach to represent both the rhythmic patterns and phrase structure of Chinese pop music. Consequently, we propose a two-step approach that aims to generate polyphonic music with coherent rhythm and long-term structure. We train two Variational Auto-Encoder networks - one on a MIDI dataset to generate 4-bar phrases, and another on song structure labels to generate full song structure. Our work shows that the models are able to learn most of the structural nuances in the training dataset, including chord and pitch frequency distributions, and phrase attributes.
Bridging Paintings and Music -- Exploring Emotion based Music Generation through Paintings
Sep 12, 2024Rapid advancements in artificial intelligence have significantly enhanced generative tasks involving music and images, employing both unimodal and multimodal approaches. This research develops a model capable of generating music that resonates with the emotions depicted in visual arts, integrating emotion labeling, image captioning, and language models to transform visual inputs into musical compositions. Addressing the scarcity of aligned art and music data, we curated the Emotion Painting Music Dataset, pairing paintings with corresponding music for effective training and evaluation. Our dual-stage framework converts images to text descriptions of emotional content and then transforms these descriptions into music, facilitating efficient learning with minimal data. Performance is evaluated using metrics such as Fr\'echet Audio Distance (FAD), Total Harmonic Distortion (THD), Inception Score (IS), and KL divergence, with audio-emotion text similarity confirmed by the pre-trained CLAP model to demonstrate high alignment between generated music and text. This synthesis tool bridges visual art and music, enhancing accessibility for the visually impaired and opening avenues in educational and therapeutic applications by providing enriched multi-sensory experiences.
From Audio Encoders to Piano Judges: Benchmarking Performance Understanding for Solo Piano
Jul 05, 2024



Our study investigates an approach for understanding musical performances through the lens of audio encoding models, focusing on the domain of solo Western classical piano music. Compared to composition-level attribute understanding such as key or genre, we identify a knowledge gap in performance-level music understanding, and address three critical tasks: expertise ranking, difficulty estimation, and piano technique detection, introducing a comprehensive Pianism-Labelling Dataset (PLD) for this purpose. We leverage pre-trained audio encoders, specifically Jukebox, Audio-MAE, MERT, and DAC, demonstrating varied capabilities in tackling downstream tasks, to explore whether domain-specific fine-tuning enhances capability in capturing performance nuances. Our best approach achieved 93.6\% accuracy in expertise ranking, 33.7\% in difficulty estimation, and 46.7\% in technique detection, with Audio-MAE as the overall most effective encoder. Finally, we conducted a case study on Chopin Piano Competition data using trained models for expertise ranking, which highlights the challenge of accurately assessing top-tier performances.
DExter: Learning and Controlling Performance Expression with Diffusion Models
Jun 21, 2024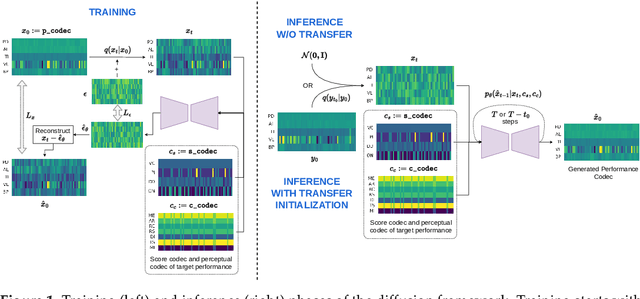
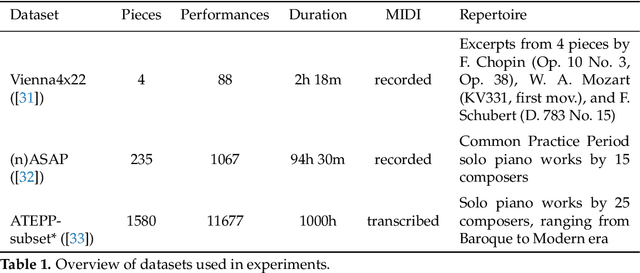
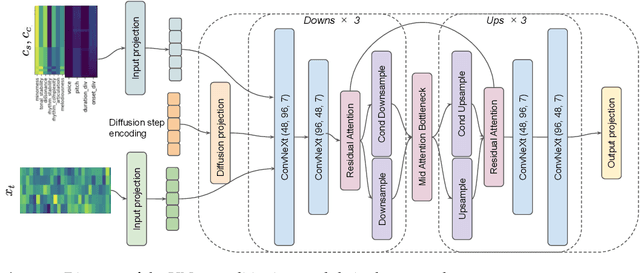
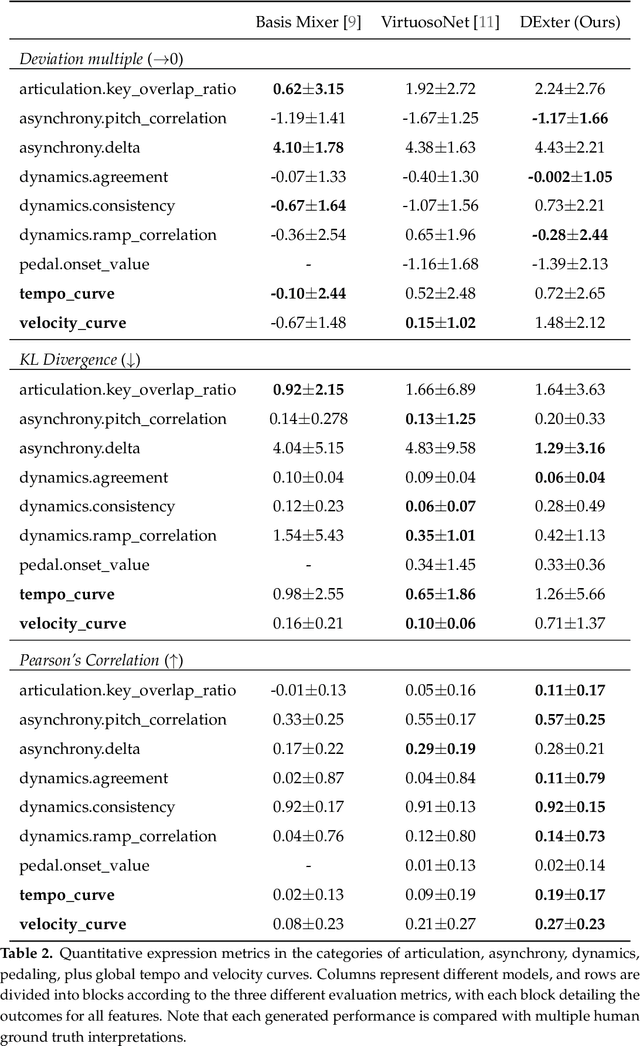
In the pursuit of developing expressive music performance models using artificial intelligence, this paper introduces DExter, a new approach leveraging diffusion probabilistic models to render Western classical piano performances. In this approach, performance parameters are represented in a continuous expression space and a diffusion model is trained to predict these continuous parameters while being conditioned on the musical score. Furthermore, DExter also enables the generation of interpretations (expressive variations of a performance) guided by perceptually meaningful features by conditioning jointly on score and perceptual feature representations. Consequently, we find that our model is useful for learning expressive performance, generating perceptually steered performances, and transferring performance styles. We assess the model through quantitative and qualitative analyses, focusing on specific performance metrics regarding dimensions like asynchrony and articulation, as well as through listening tests comparing generated performances with different human interpretations. Results show that DExter is able to capture the time-varying correlation of the expressive parameters, and compares well to existing rendering models in subjectively evaluated ratings. The perceptual-feature-conditioned generation and transferring capabilities of DExter are verified by a proxy model predicting perceptual characteristics of differently steered performances.
Mind the Domain Gap: a Systematic Analysis on Bioacoustic Sound Event Detection
Mar 27, 2024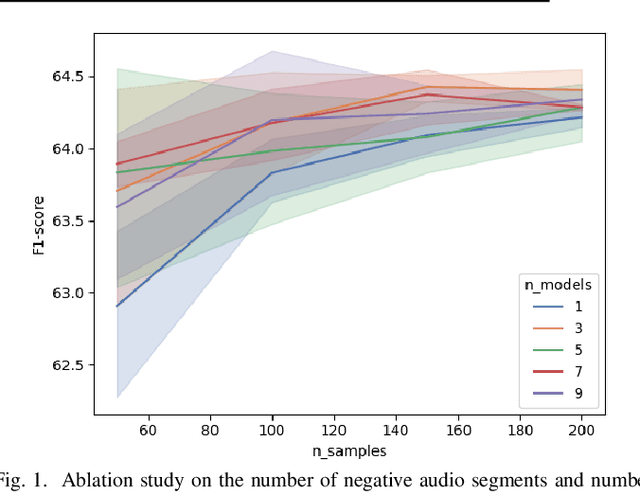
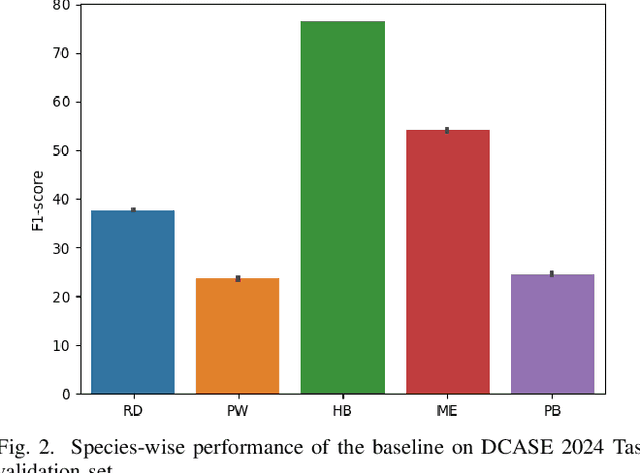
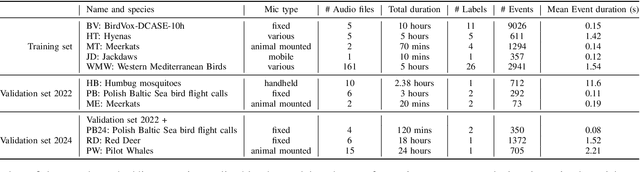

Detecting the presence of animal vocalisations in nature is essential to study animal populations and their behaviors. A recent development in the field is the introduction of the task known as few-shot bioacoustic sound event detection, which aims to train a versatile animal sound detector using only a small set of audio samples. Previous efforts in this area have utilized different architectures and data augmentation techniques to enhance model performance. However, these approaches have not fully bridged the domain gap between source and target distributions, limiting their applicability in real-world scenarios. In this work, we introduce an new dataset designed to augment the diversity and breadth of classes available for few-shot bioacoustic event detection, building on the foundations of our previous datasets. To establish a robust baseline system tailored for the DCASE 2024 Task 5 challenge, we delve into an array of acoustic features and adopt negative hard sampling as our primary domain adaptation strategy. This approach, chosen in alignment with the challenge's guidelines that necessitate the independent treatment of each audio file, sidesteps the use of transductive learning to ensure compliance while aiming to enhance the system's adaptability to domain shifts. Our experiments show that the proposed baseline system achieves a better performance compared with the vanilla prototypical network. The findings also confirm the effectiveness of each domain adaptation method by ablating different components within the networks. This highlights the potential to improve few-shot bioacoustic sound event detection by further reducing the impact of domain shift.
WavCraft: Audio Editing and Generation with Natural Language Prompts
Mar 15, 2024



We introduce WavCraft, a collective system that leverages large language models (LLMs) to connect diverse task-specific models for audio content creation and editing. Specifically, WavCraft describes the content of raw sound materials in natural language and prompts the LLM conditioned on audio descriptions and users' requests. WavCraft leverages the in-context learning ability of the LLM to decomposes users' instructions into several tasks and tackle each task collaboratively with audio expert modules. Through task decomposition along with a set of task-specific models, WavCraft follows the input instruction to create or edit audio content with more details and rationales, facilitating users' control. In addition, WavCraft is able to cooperate with users via dialogue interaction and even produce the audio content without explicit user commands. Experiments demonstrate that WavCraft yields a better performance than existing methods, especially when adjusting the local regions of audio clips. Moreover, WavCraft can follow complex instructions to edit and even create audio content on the top of input recordings, facilitating audio producers in a broader range of applications. Our implementation and demos are available at https://github.com/JinhuaLiang/WavCraft.