 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioDCASE 2026 Challenge Baseline for Cross-Domain Mosquito Species Classification
Mar 20, 2026Mosquito-borne diseases affect more than one billion people each year and cause close to one million deaths. Traditional surveillance methods rely on traps and manual identification that are slow, labor-intensive, and difficult to scale. Audio-based mosquito monitoring offers a non-destructive, lower-cost, and more scalable complement to trap-based surveillance, but reliable species classification remains difficult under real-world recording conditions. Mosquito flight tones are narrow-band, often low in signal-to-noise ratio, and easily masked by background noise, and recordings for several epidemiologically relevant species remain limited, creating pronounced class imbalance. Variation across devices, environments, and collection protocols further increases the difficulty of robust classification. Such variation can cause models to rely on domain-specific recording artefacts rather than species-relevant acoustic cues, which makes transfer to new acquisition settings difficult. The BioDCASE 2026 Cross-Domain Mosquito Species Classification (CD-MSC) challenge is designed around this deployment problem by evaluating performance on both seen and unseen domains. This paper presents the official baseline system and evaluation pipeline as a simple, fully reproducible reference for the CD-MSC challenge task. The baseline uses log-mel features and a multitemporal resolution convolutional neural network (MTRCNN) with species and auxiliary domain outputs, together with complete training and test scripts. The baseline system performs strongly on seen domains but degrades markedly on unseen domains, showing that cross-domain generalisation, rather than within-domain recognition, is the central challenge for practical mosquito species classification from multi-source bioacoustic recordings.
Summary of The Inaugural Music Source Restoration Challenge
Jan 07, 2026Music Source Restoration (MSR) aims to recover original, unprocessed instrument stems from professionally mixed and degraded audio, requiring the reversal of both production effects and real-world degradations. We present the inaugural MSR Challenge, which features objective evaluation on studio-produced mixtures using Multi-Mel-SNR, Zimtohrli, and FAD-CLAP, alongside subjective evaluation on real-world degraded recordings. Five teams participated in the challenge. The winning system achieved 4.46 dB Multi-Mel-SNR and 3.47 MOS-Overall, corresponding to relative improvements of 91% and 18% over the second-place system, respectively. Per-stem analysis reveals substantial variation in restoration difficulty across instruments, with bass averaging 4.59 dB across all teams, while percussion averages only 0.29 dB. The dataset, evaluation protocols, and baselines are available at https://msrchallenge.com/.
Region-Specific Audio Tagging for Spatial Sound
Sep 11, 2025Audio tagging aims to label sound events appearing in an audio recording. In this paper, we propose region-specific audio tagging, a new task which labels sound events in a given region for spatial audio recorded by a microphone array. The region can be specified as an angular space or a distance from the microphone. We first study the performance of different combinations of spectral, spatial, and position features. Then we extend state-of-the-art audio tagging systems such as pre-trained audio neural networks (PANNs) and audio spectrogram transformer (AST) to the proposed region-specific audio tagging task. Experimental results on both the simulated and the real datasets show the feasibility of the proposed task and the effectiveness of the proposed method. Further experiments show that incorporating the directional features is beneficial for omnidirectional tagging.
Towards Reliable Objective Evaluation Metrics for Generative Singing Voice Separation Models
Jul 15, 2025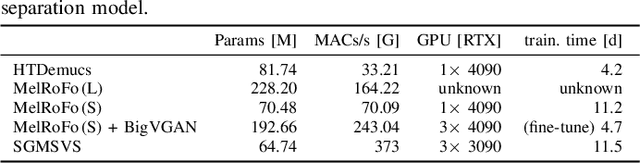
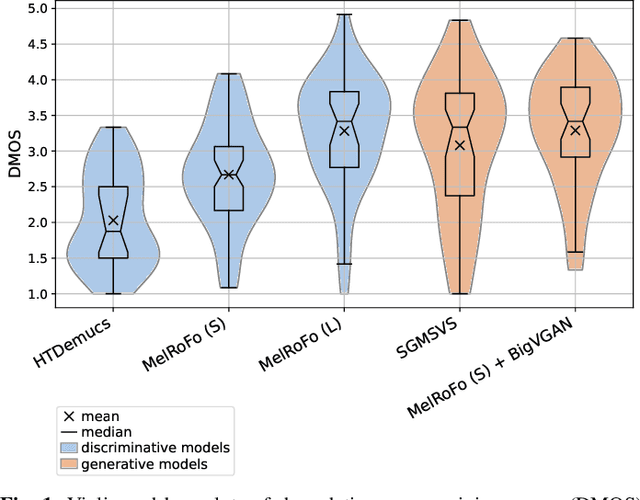
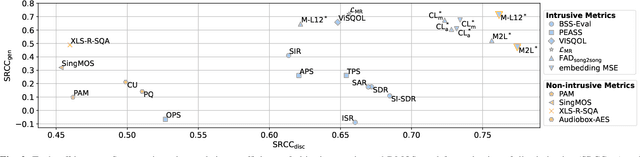
Traditional Blind Source Separation Evaluation (BSS-Eval) metrics were originally designed to evaluate linear audio source separation models based on methods such as time-frequency masking. However, recent generative models may introduce nonlinear relationships between the separated and reference signals, limiting the reliability of these metrics for objective evaluation. To address this issue, we conduct a Degradation Category Rating listening test and analyze correlations between the obtained degradation mean opinion scores (DMOS) and a set of objective audio quality metrics for the task of singing voice separation. We evaluate three state-of-the-art discriminative models and two new competitive generative models. For both discriminative and generative models, intrusive embedding-based metrics show higher correlations with DMOS than conventional intrusive metrics such as BSS-Eval. For discriminative models, the highest correlation is achieved by the MSE computed on Music2Latent embeddings. When it comes to the evaluation of generative models, the strongest correlations are evident for the multi-resolution STFT loss and the MSE calculated on MERT-L12 embeddings, with the latter also providing the most balanced correlation across both model types. Our results highlight the limitations of BSS-Eval metrics for evaluating generative singing voice separation models and emphasize the need for careful selection and validation of alternative evaluation metrics for the task of singing voice separation.
Music Source Restoration
May 27, 2025We introduce Music Source Restoration (MSR), a novel task addressing the gap between idealized source separation and real-world music production. Current Music Source Separation (MSS) approaches assume mixtures are simple sums of sources, ignoring signal degradations employed during music production like equalization, compression, and reverb. MSR models mixtures as degraded sums of individually degraded sources, with the goal of recovering original, undegraded signals. Due to the lack of data for MSR, we present RawStems, a dataset annotation of 578 songs with unprocessed source signals organized into 8 primary and 17 secondary instrument groups, totaling 354.13 hours. To the best of our knowledge, RawStems is the first dataset that contains unprocessed music stems with hierarchical categories. We consider spectral filtering, dynamic range compression, harmonic distortion, reverb and lossy codec as possible degradations, and establish U-Former as a baseline method, demonstrating the feasibility of MSR on our dataset. We release the RawStems dataset annotations, degradation simulation pipeline, training code and pre-trained models to be publicly available.
Exploring the User Experience of AI-Assisted Sound Searching Systems for Creative Workflows
Apr 22, 2025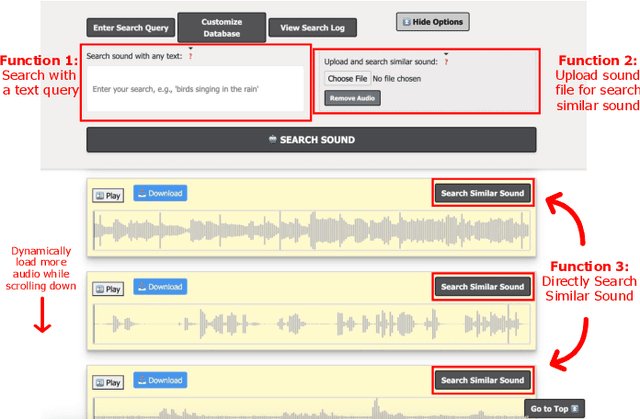
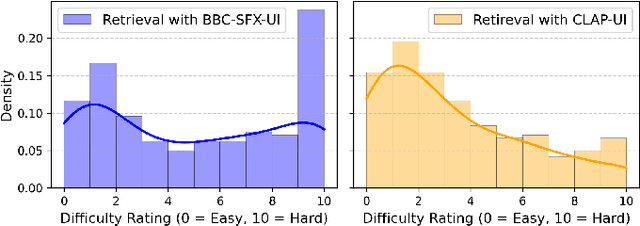
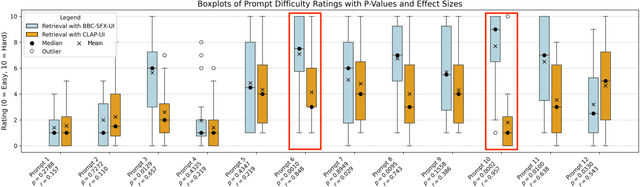
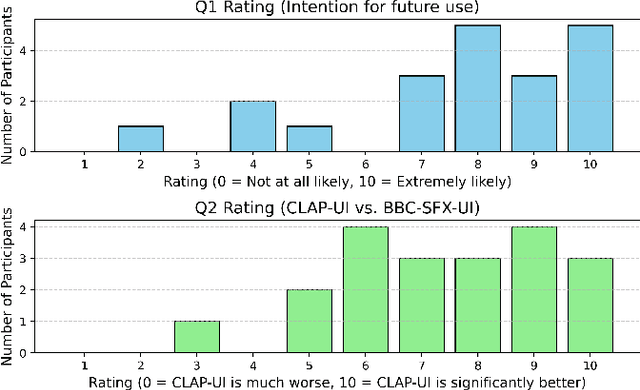
Locating the right sound effect efficiently is an important yet challenging topic for audio production. Most current sound-searching systems rely on pre-annotated audio labels created by humans, which can be time-consuming to produce and prone to inaccuracies, limiting the efficiency of audio production. Following the recent advancement of contrastive language-audio pre-training (CLAP) models, we explore an alternative CLAP-based sound-searching system (CLAP-UI) that does not rely on human annotations. To evaluate the effectiveness of CLAP-UI, we conducted comparative experiments with a widely used sound effect searching platform, the BBC Sound Effect Library. Our study evaluates user performance, cognitive load, and satisfaction through ecologically valid tasks based on professional sound-searching workflows. Our result shows that CLAP-UI demonstrated significantly enhanced productivity and reduced frustration while maintaining comparable cognitive demands. We also qualitatively analyzed the participants' feedback, which offered valuable perspectives on the design of future AI-assisted sound search systems.
AudioSetCaps: An Enriched Audio-Caption Dataset using Automated Generation Pipeline with Large Audio and Language Models
Nov 28, 2024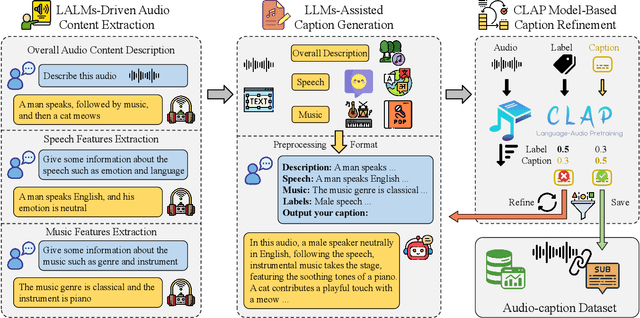
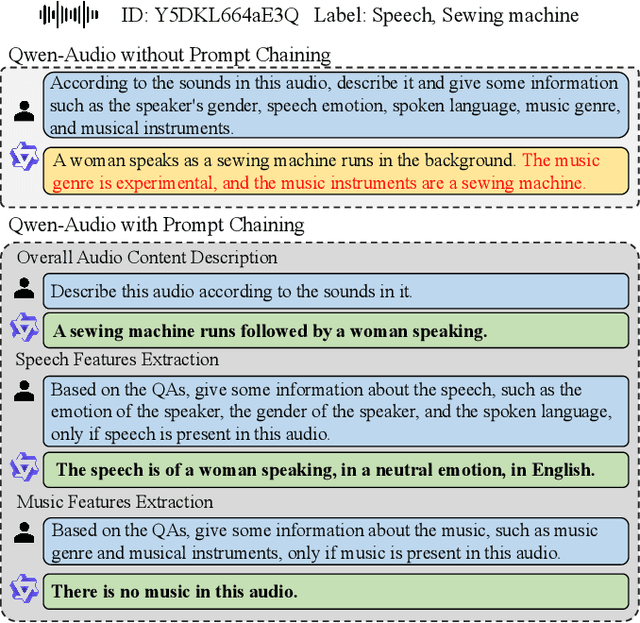
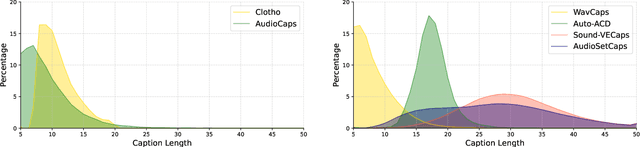

With the emergence of audio-language models, constructing large-scale paired audio-language datasets has become essential yet challenging for model development, primarily due to the time-intensive and labour-heavy demands involved. While large language models (LLMs) have improved the efficiency of synthetic audio caption generation, current approaches struggle to effectively extract and incorporate detailed audio information. In this paper, we propose an automated pipeline that integrates audio-language models for fine-grained content extraction, LLMs for synthetic caption generation, and a contrastive language-audio pretraining (CLAP) model-based refinement process to improve the quality of captions. Specifically, we employ prompt chaining techniques in the content extraction stage to obtain accurate and fine-grained audio information, while we use the refinement process to mitigate potential hallucinations in the generated captions. Leveraging the AudioSet dataset and the proposed approach, we create AudioSetCaps, a dataset comprising 1.9 million audio-caption pairs, the largest audio-caption dataset at the time of writing. The models trained with AudioSetCaps achieve state-of-the-art performance on audio-text retrieval with R@1 scores of 46.3% for text-to-audio and 59.7% for audio-to-text retrieval and automated audio captioning with the CIDEr score of 84.8. As our approach has shown promising results with AudioSetCaps, we create another dataset containing 4.1 million synthetic audio-language pairs based on the Youtube-8M and VGGSound datasets. To facilitate research in audio-language learning, we have made our pipeline, datasets with 6 million audio-language pairs, and pre-trained models publicly available at https://github.com/JishengBai/AudioSetCaps.
PSELDNets: Pre-trained Neural Networks on Large-scale Synthetic Datasets for Sound Event Localization and Detection
Nov 10, 2024



Sound event localization and detection (SELD) has seen substantial advancements through learning-based methods. These systems, typically trained from scratch on specific datasets, have shown considerable generalization capabilities. Recently, deep neural networks trained on large-scale datasets have achieved remarkable success in the sound event classification (SEC) field, prompting an open question of whether these advancements can be extended to develop general-purpose SELD models. In this paper, leveraging the power of pre-trained SEC models, we propose pre-trained SELD networks (PSELDNets) on large-scale synthetic datasets. These synthetic datasets, generated by convolving sound events with simulated spatial room impulse responses (SRIRs), contain 1,167 hours of audio clips with an ontology of 170 sound classes. These PSELDNets are transferred to downstream SELD tasks. When we adapt PSELDNets to specific scenarios, particularly in low-resource data cases, we introduce a data-efficient fine-tuning method, AdapterBit. PSELDNets are evaluated on a synthetic-test-set using collected SRIRs from TAU Spatial Room Impulse Response Database (TAU-SRIR DB) and achieve satisfactory performance. We also conduct our experiments to validate the transferability of PSELDNets to three publicly available datasets and our own collected audio recordings. Results demonstrate that PSELDNets surpass state-of-the-art systems across all publicly available datasets. Given the need for direction-of-arrival estimation, SELD generally relies on sufficient multi-channel audio clips. However, incorporating the AdapterBit, PSELDNets show more efficient adaptability to various tasks using minimal multi-channel or even just monophonic audio clips, outperforming the traditional fine-tuning approaches.
A decade of DCASE: Achievements, practices, evaluations and future challenges
Oct 07, 2024This paper introduces briefly the history and growth of the Detection and Classification of Acoustic Scenes and Events (DCASE) challenge, workshop, research area and research community. Created in 2013 as a data evaluation challenge, DCASE has become a major research topic in the Audio and Acoustic Signal Processing area. Its success comes from a combination of factors: the challenge offers a large variety of tasks that are renewed each year; and the workshop offers a channel for dissemination of related work, engaging a young and dynamic community. At the same time, DCASE faces its own challenges, growing and expanding to different areas. One of the core principles of DCASE is open science and reproducibility: publicly available datasets, baseline systems, technical reports and workshop publications. While the DCASE challenge and workshop are independent of IEEE SPS, the challenge receives annual endorsement from the AASP TC, and the DCASE community contributes significantly to the ICASSP flagship conference and the success of SPS in many of its activities.
The Sounds of Home: A Speech-Removed Residential Audio Dataset for Sound Event Detection
Sep 17, 2024



This paper presents a residential audio dataset to support sound event detection research for smart home applications aimed at promoting wellbeing for older adults. The dataset is constructed by deploying audio recording systems in the homes of 8 participants aged 55-80 years for a 7-day period. Acoustic characteristics are documented through detailed floor plans and construction material information to enable replication of the recording environments for AI model deployment. A novel automated speech removal pipeline is developed, using pre-trained audio neural networks to detect and remove segments containing spoken voice, while preserving segments containing other sound events. The resulting dataset consists of privacy-compliant audio recordings that accurately capture the soundscapes and activities of daily living within residential spaces. The paper details the dataset creation methodology, the speech removal pipeline utilizing cascaded model architectures, and an analysis of the vocal label distribution to validate the speech removal process. This dataset enables the development and benchmarking of sound event detection models tailored specifically for in-home applications.