 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Noval Monte Carlo Gradient Method Based on Meta-learning for Effective Step-size Selection in Active Noise Control
Feb 28, 2026Active noise control (ANC) is an effective approach to noise suppression, and the filtered-reference least mean square (FxLMS) algorithm is a widely adopted method in ANC systems, owing to its computational efficiency and stable performance. However, its convergence speed and noise reduction performance are highly dependent on the step size parameter. Common step-size algorithms-such as normalized and variable step-size variants-require additional computational resources and exhibit limited adaptability under varying environmental conditions. To address this challenge, a novel Monte Carlo gradient meta-learning (MCGM) approach is proposed herein to determine an appropriate step size, into which a forgetting factor is incorporated to mitigate the impact of initial zero effect. Compared to other algorithms, the proposed method imposes no additional computational burden on FxLMS operations. Numerical simulations involving real-world acoustic paths and noise signals further confirm its effectiveness and robustness.
Dynamic Fusion Multimodal Network for SpeechWellness Detection
Aug 25, 2025Suicide is one of the leading causes of death among adolescents. Previous suicide risk prediction studies have primarily focused on either textual or acoustic information in isolation, the integration of multimodal signals, such as speech and text, offers a more comprehensive understanding of an individual's mental state. Motivated by this, and in the context of the 1st SpeechWellness detection challenge, we explore a lightweight multi-branch multimodal system based on a dynamic fusion mechanism for speechwellness detection. To address the limitation of prior approaches that rely on time-domain waveforms for acoustic analysis, our system incorporates both time-domain and time-frequency (TF) domain acoustic features, as well as semantic representations. In addition, we introduce a dynamic fusion block to adaptively integrate information from different modalities. Specifically, it applies learnable weights to each modality during the fusion process, enabling the model to adjust the contribution of each modality. To enhance computational efficiency, we design a lightweight structure by simplifying the original baseline model. Experimental results demonstrate that the proposed system exhibits superior performance compared to the challenge baseline, achieving a 78% reduction in model parameters and a 5% improvement in accuracy.
EnvSDD: Benchmarking Environmental Sound Deepfake Detection
May 25, 2025Audio generation systems now create very realistic soundscapes that can enhance media production, but also pose potential risks. Several studies have examined deepfakes in speech or singing voice. However, environmental sounds have different characteristics, which may make methods for detecting speech and singing deepfakes less effective for real-world sounds. In addition, existing datasets for environmental sound deepfake detection are limited in scale and audio types. To address this gap, we introduce EnvSDD, the first large-scale curated dataset designed for this task, consisting of 45.25 hours of real and 316.74 hours of fake audio. The test set includes diverse conditions to evaluate the generalizability, such as unseen generation models and unseen datasets. We also propose an audio deepfake detection system, based on a pre-trained audio foundation model. Results on EnvSDD show that our proposed system outperforms the state-of-the-art systems from speech and singing domains.
Audio-Language Models for Audio-Centric Tasks: A survey
Jan 25, 2025



Audio-Language Models (ALMs), which are trained on audio-text data, focus on the processing, understanding, and reasoning of sounds. Unlike traditional supervised learning approaches learning from predefined labels, ALMs utilize natural language as a supervision signal, which is more suitable for describing complex real-world audio recordings. ALMs demonstrate strong zero-shot capabilities and can be flexibly adapted to diverse downstream tasks. These strengths not only enhance the accuracy and generalization of audio processing tasks but also promote the development of models that more closely resemble human auditory perception and comprehension. Recent advances in ALMs have positioned them at the forefront of computer audition research, inspiring a surge of efforts to advance ALM technologies. Despite rapid progress in the field of ALMs, there is still a notable lack of systematic surveys that comprehensively organize and analyze developments. In this paper, we present a comprehensive review of ALMs with a focus on general audio tasks, aiming to fill this gap by providing a structured and holistic overview of ALMs. Specifically, we cover: (1) the background of computer audition and audio-language models; (2) the foundational aspects of ALMs, including prevalent network architectures, training objectives, and evaluation methods; (3) foundational pre-training and audio-language pre-training approaches; (4) task-specific fine-tuning, multi-task tuning and agent systems for downstream applications; (5) datasets and benchmarks; and (6) current challenges and future directions. Our review provides a clear technical roadmap for researchers to understand the development and future trends of existing technologies, offering valuable references for implementation in real-world scenarios.
AudioSetCaps: An Enriched Audio-Caption Dataset using Automated Generation Pipeline with Large Audio and Language Models
Nov 28, 2024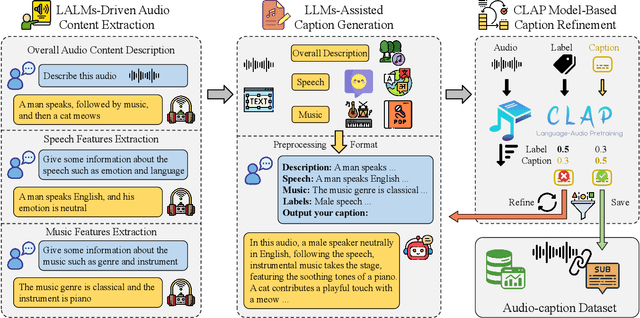
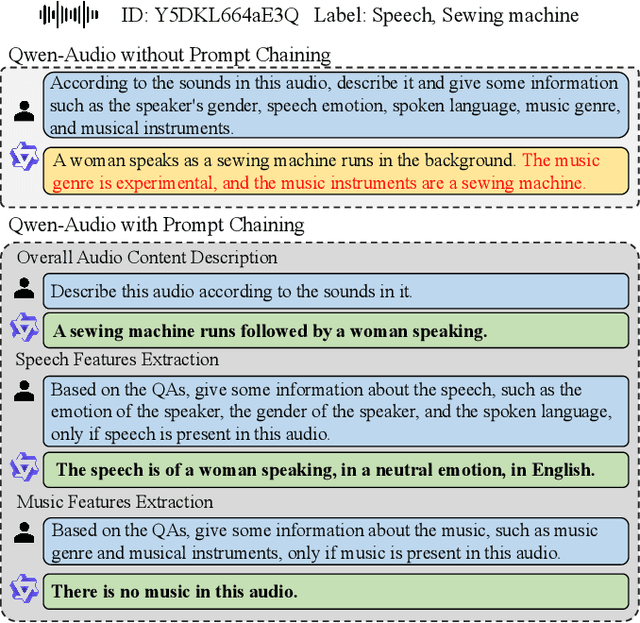

With the emergence of audio-language models, constructing large-scale paired audio-language datasets has become essential yet challenging for model development, primarily due to the time-intensive and labour-heavy demands involved. While large language models (LLMs) have improved the efficiency of synthetic audio caption generation, current approaches struggle to effectively extract and incorporate detailed audio information. In this paper, we propose an automated pipeline that integrates audio-language models for fine-grained content extraction, LLMs for synthetic caption generation, and a contrastive language-audio pretraining (CLAP) model-based refinement process to improve the quality of captions. Specifically, we employ prompt chaining techniques in the content extraction stage to obtain accurate and fine-grained audio information, while we use the refinement process to mitigate potential hallucinations in the generated captions. Leveraging the AudioSet dataset and the proposed approach, we create AudioSetCaps, a dataset comprising 1.9 million audio-caption pairs, the largest audio-caption dataset at the time of writing. The models trained with AudioSetCaps achieve state-of-the-art performance on audio-text retrieval with R@1 scores of 46.3% for text-to-audio and 59.7% for audio-to-text retrieval and automated audio captioning with the CIDEr score of 84.8. As our approach has shown promising results with AudioSetCaps, we create another dataset containing 4.1 million synthetic audio-language pairs based on the Youtube-8M and VGGSound datasets. To facilitate research in audio-language learning, we have made our pipeline, datasets with 6 million audio-language pairs, and pre-trained models publicly available at https://github.com/JishengBai/AudioSetCaps.
Leveraging LLM and Text-Queried Separation for Noise-Robust Sound Event Detection
Nov 02, 2024Sound Event Detection (SED) is challenging in noisy environments where overlapping sounds obscure target events. Language-queried audio source separation (LASS) aims to isolate the target sound events from a noisy clip. However, this approach can fail when the exact target sound is unknown, particularly in noisy test sets, leading to reduced performance. To address this issue, we leverage the capabilities of large language models (LLMs) to analyze and summarize acoustic data. By using LLMs to identify and select specific noise types, we implement a noise augmentation method for noise-robust fine-tuning. The fine-tuned model is applied to predict clip-wise event predictions as text queries for the LASS model. Our studies demonstrate that the proposed method improves SED performance in noisy environments. This work represents an early application of LLMs in noise-robust SED and suggests a promising direction for handling overlapping events in SED. Codes and pretrained models are available at https://github.com/apple-yinhan/Noise-robust-SED.
Data Efficient Acoustic Scene Classification using Teacher-Informed Confusing Class Instruction
Sep 18, 2024



In this technical report, we describe the SNTL-NTU team's submission for Task 1 Data-Efficient Low-Complexity Acoustic Scene Classification of the detection and classification of acoustic scenes and events (DCASE) 2024 challenge. Three systems are introduced to tackle training splits of different sizes. For small training splits, we explored reducing the complexity of the provided baseline model by reducing the number of base channels. We introduce data augmentation in the form of mixup to increase the diversity of training samples. For the larger training splits, we use FocusNet to provide confusing class information to an ensemble of multiple Patchout faSt Spectrogram Transformer (PaSST) models and baseline models trained on the original sampling rate of 44.1 kHz. We use Knowledge Distillation to distill the ensemble model to the baseline student model. Training the systems on the TAU Urban Acoustic Scene 2022 Mobile development dataset yielded the highest average testing accuracy of (62.21, 59.82, 56.81, 53.03, 47.97)% on split (100, 50, 25, 10, 5)% respectively over the three systems.
Real-Time Sound Event Localization and Detection: Deployment Challenges on Edge Devices
Sep 18, 2024Sound event localization and detection (SELD) is critical for various real-world applications, including smart monitoring and Internet of Things (IoT) systems. Although deep neural networks (DNNs) represent the state-of-the-art approach for SELD, their significant computational complexity and model sizes present challenges for deployment on resource-constrained edge devices, especially under real-time conditions. Despite the growing need for real-time SELD, research in this area remains limited. In this paper, we investigate the unique challenges of deploying SELD systems for real-world, real-time applications by performing extensive experiments on a commercially available Raspberry Pi 3 edge device. Our findings reveal two critical, often overlooked considerations: the high computational cost of feature extraction and the performance degradation associated with low-latency, real-time inference. This paper provides valuable insights and considerations for future work toward developing more efficient and robust real-time SELD systems
Squeeze-and-Excite ResNet-Conformers for Sound Event Localization, Detection, and Distance Estimation for DCASE 2024 Challenge
Jul 12, 2024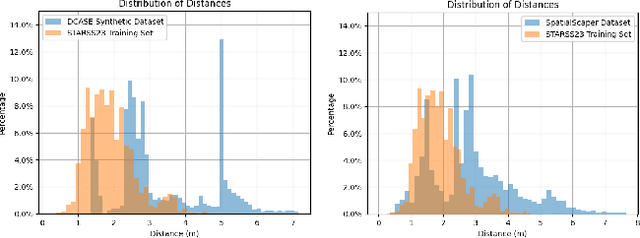
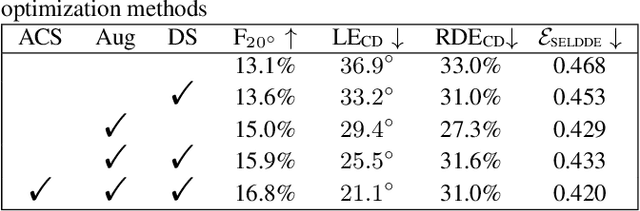
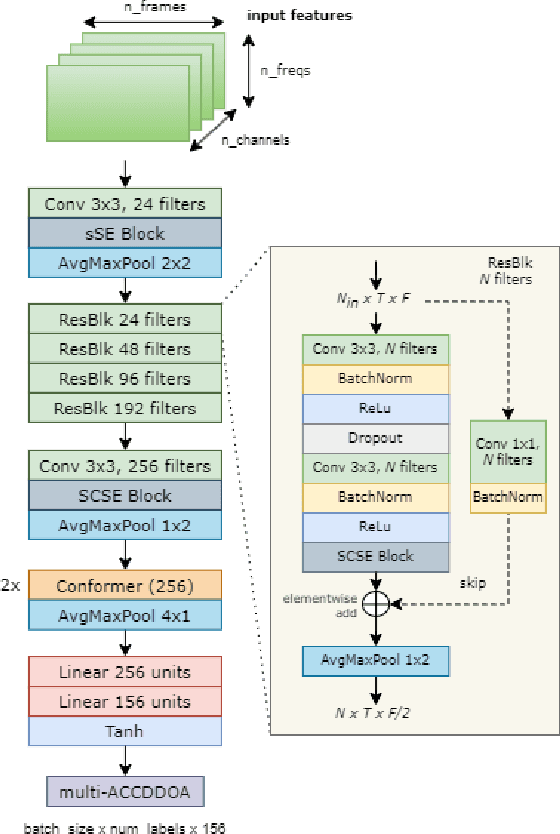
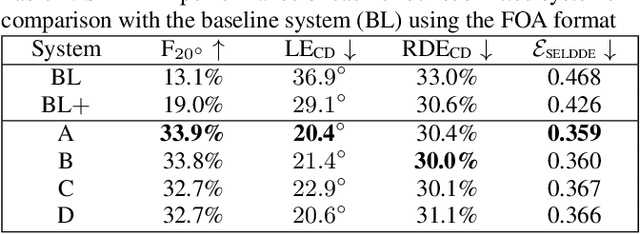
This technical report details our systems submitted for Task 3 of the DCASE 2024 Challenge: Audio and Audiovisual Sound Event Localization and Detection (SELD) with Source Distance Estimation (SDE). We address only the audio-only SELD with SDE (SELDDE) task in this report. We propose to improve the existing ResNet-Conformer architectures with Squeeze-and-Excitation blocks in order to introduce additional forms of channel- and spatial-wise attention. In order to improve SELD performance, we also utilize the Spatial Cue-Augmented Log-Spectrogram (SALSA) features over the commonly used log-mel spectra features for polyphonic SELD. We complement the existing Sony-TAu Realistic Spatial Soundscapes 2023 (STARSS23) dataset with the audio channel swapping technique and synthesize additional data using the SpatialScaper generator. We also perform distance scaling in order to prevent large distance errors from contributing more towards the loss function. Finally, we evaluate our approach on the evaluation subset of the STARSS23 dataset.
Mixstyle based Domain Generalization for Sound Event Detection with Heterogeneous Training Data
Jul 04, 2024This work explores domain generalization (DG) for sound event detection (SED), advancing adaptability towards real-world scenarios. Our approach employs a mean-teacher framework with domain generalization to integrate heterogeneous training data, while preserving the SED model performance across the datasets. Specifically, we first apply mixstyle to the frequency dimension to adapt the mel-spectrograms from different domains. Next, we use the adaptive residual normalization method to generalize features across multiple domains by applying instance normalization in the frequency dimension. Lastly, we use the sound event bounding boxes method for post-processing. Our approach integrates features from bidirectional encoder representations from audio transformers and a convolutional recurrent neural network. We evaluate the proposed approach on DCASE 2024 Challenge Task 4 dataset, measuring polyphonic SED score (PSDS) on the DESED dataset and macro-average pAUC on the MAESTRO dataset. The results indicate that the proposed DG-based method improves both PSDS and macro-average pAUC compared to the challenge baseline.