 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAGENTA: Magnitude and Geometry-ENhanced Training Approach for Robust Long-Tailed Sound Event Localization and Detection
Sep 19, 2025Deep learning-based Sound Event Localization and Detection (SELD) systems degrade significantly on real-world, long-tailed datasets. Standard regression losses bias learning toward frequent classes, causing rare events to be systematically under-recognized. To address this challenge, we introduce MAGENTA (Magnitude And Geometry-ENhanced Training Approach), a unified loss function that counteracts this bias within a physically interpretable vector space. MAGENTA geometrically decomposes the regression error into radial and angular components, enabling targeted, rarity-aware penalties and strengthened directional modeling. Empirically, MAGENTA substantially improves SELD performance on imbalanced real-world data, providing a principled foundation for a new class of geometry-aware SELD objectives. Code is available at: https://github.com/itsjunwei/MAGENTA_ICASSP
Enhancing Situational Awareness in Wearable Audio Devices Using a Lightweight Sound Event Localization and Detection System
Sep 18, 2025Wearable audio devices with active noise control (ANC) enhance listening comfort but often at the expense of situational awareness. However, this auditory isolation may mask crucial environmental cues, posing significant safety risks. To address this, we propose an environmental intelligence framework that combines Acoustic Scene Classification (ASC) with Sound Event Localization and Detection (SELD). Our system first employs a lightweight ASC model to infer the current environment. The scene prediction then dynamically conditions a SELD network, tuning its sensitivity to detect and localize sounds that are most salient to the current context. On simulated headphone data, the proposed ASC-conditioned SELD system demonstrates improved spatial intelligence over a conventional baseline. This work represents a crucial step towards creating intelligent hearables that can deliver crucial environmental information, fostering a safer and more context-aware listening experience.
Improving Stereo 3D Sound Event Localization and Detection: Perceptual Features, Stereo-specific Data Augmentation, and Distance Normalization
Jul 01, 2025This technical report presents our submission to Task 3 of the DCASE 2025 Challenge: Stereo Sound Event Localization and Detection (SELD) in Regular Video Content. We address the audio-only task in this report and introduce several key contributions. First, we design perceptually-motivated input features that improve event detection, sound source localization, and distance estimation. Second, we adapt augmentation strategies specifically for the intricacies of stereo audio, including channel swapping and time-frequency masking. We also incorporate the recently proposed FilterAugment technique that has yet to be explored for SELD work. Lastly, we apply a distance normalization approach during training to stabilize regression targets. Experiments on the stereo STARSS23 dataset demonstrate consistent performance gains across all SELD metrics. Code to replicate our work is available in this repository: https://github.com/itsjunwei/NTU_SNTL_Task3
Real-Time Sound Event Localization and Detection: Deployment Challenges on Edge Devices
Sep 18, 2024Sound event localization and detection (SELD) is critical for various real-world applications, including smart monitoring and Internet of Things (IoT) systems. Although deep neural networks (DNNs) represent the state-of-the-art approach for SELD, their significant computational complexity and model sizes present challenges for deployment on resource-constrained edge devices, especially under real-time conditions. Despite the growing need for real-time SELD, research in this area remains limited. In this paper, we investigate the unique challenges of deploying SELD systems for real-world, real-time applications by performing extensive experiments on a commercially available Raspberry Pi 3 edge device. Our findings reveal two critical, often overlooked considerations: the high computational cost of feature extraction and the performance degradation associated with low-latency, real-time inference. This paper provides valuable insights and considerations for future work toward developing more efficient and robust real-time SELD systems
Data Efficient Acoustic Scene Classification using Teacher-Informed Confusing Class Instruction
Sep 18, 2024



In this technical report, we describe the SNTL-NTU team's submission for Task 1 Data-Efficient Low-Complexity Acoustic Scene Classification of the detection and classification of acoustic scenes and events (DCASE) 2024 challenge. Three systems are introduced to tackle training splits of different sizes. For small training splits, we explored reducing the complexity of the provided baseline model by reducing the number of base channels. We introduce data augmentation in the form of mixup to increase the diversity of training samples. For the larger training splits, we use FocusNet to provide confusing class information to an ensemble of multiple Patchout faSt Spectrogram Transformer (PaSST) models and baseline models trained on the original sampling rate of 44.1 kHz. We use Knowledge Distillation to distill the ensemble model to the baseline student model. Training the systems on the TAU Urban Acoustic Scene 2022 Mobile development dataset yielded the highest average testing accuracy of (62.21, 59.82, 56.81, 53.03, 47.97)% on split (100, 50, 25, 10, 5)% respectively over the three systems.
Squeeze-and-Excite ResNet-Conformers for Sound Event Localization, Detection, and Distance Estimation for DCASE 2024 Challenge
Jul 12, 2024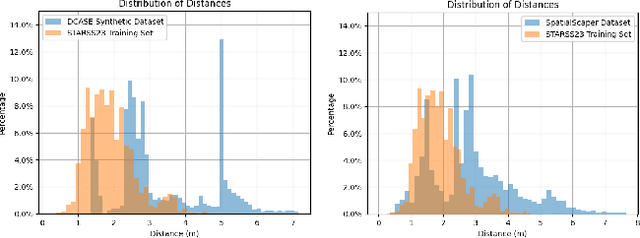
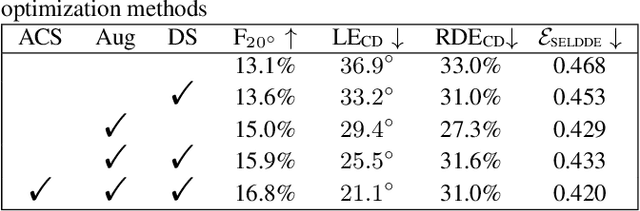
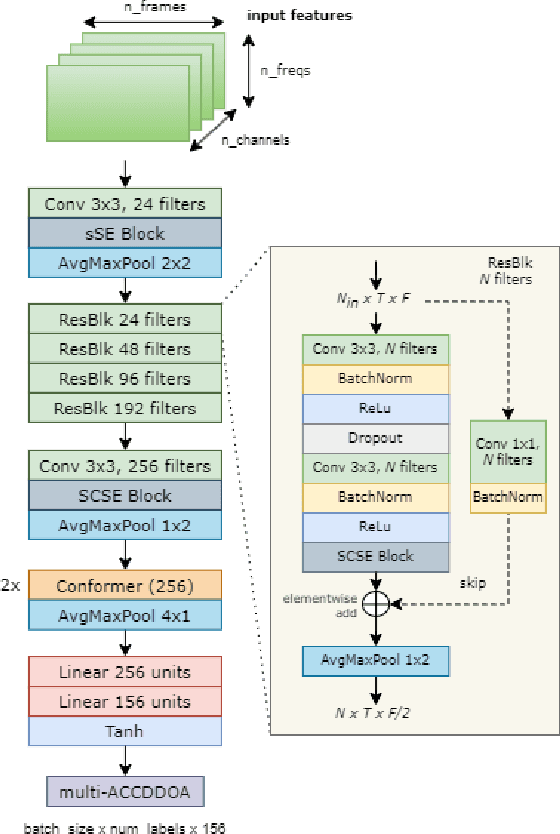
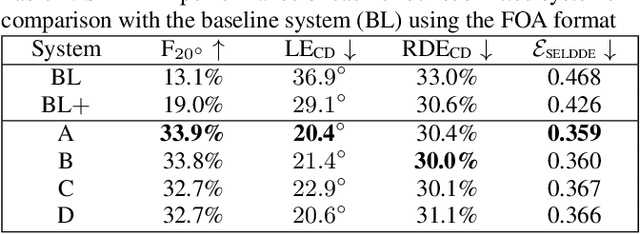
This technical report details our systems submitted for Task 3 of the DCASE 2024 Challenge: Audio and Audiovisual Sound Event Localization and Detection (SELD) with Source Distance Estimation (SDE). We address only the audio-only SELD with SDE (SELDDE) task in this report. We propose to improve the existing ResNet-Conformer architectures with Squeeze-and-Excitation blocks in order to introduce additional forms of channel- and spatial-wise attention. In order to improve SELD performance, we also utilize the Spatial Cue-Augmented Log-Spectrogram (SALSA) features over the commonly used log-mel spectra features for polyphonic SELD. We complement the existing Sony-TAu Realistic Spatial Soundscapes 2023 (STARSS23) dataset with the audio channel swapping technique and synthesize additional data using the SpatialScaper generator. We also perform distance scaling in order to prevent large distance errors from contributing more towards the loss function. Finally, we evaluate our approach on the evaluation subset of the STARSS23 dataset.
Implementing Continuous HRTF Measurement in Near-Field
Mar 15, 2023
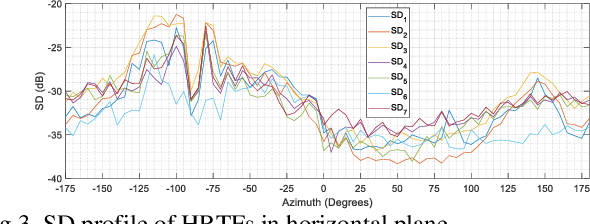


Head-related transfer function (HRTF) is an essential component to create an immersive listening experience over headphones for virtual reality (VR) and augmented reality (AR) applications. Metaverse combines VR and AR to create immersive digital experiences, and users are very likely to interact with virtual objects in the near-field (NF). The HRTFs of such objects are highly individualized and dependent on directions and distances. Hence, a significant number of HRTF measurements at different distances in the NF would be needed. Using conventional static stop-and-go HRTF measurement methods to acquire these measurements would be time-consuming and tedious for human listeners. In this paper, we propose a continuous measurement system targeted for the NF, and efficiently capturing HRTFs in the horizontal plane within 45 secs. Comparative experiments are performed on head and torso similar (HATS) and human listeners to evaluate system consistency and robustness.
A Strongly-Labelled Polyphonic Dataset of Urban Sounds with Spatiotemporal Context
Nov 11, 2021
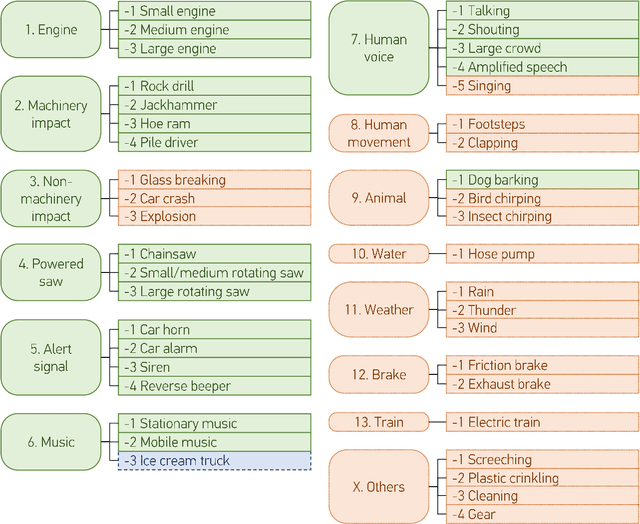
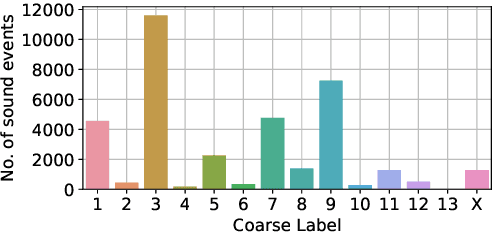
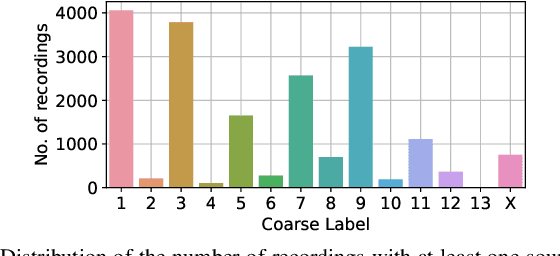
This paper introduces SINGA:PURA, a strongly labelled polyphonic urban sound dataset with spatiotemporal context. The data were collected via several recording units deployed across Singapore as a part of a wireless acoustic sensor network. These recordings were made as part of a project to identify and mitigate noise sources in Singapore, but also possess a wider applicability to sound event detection, classification, and localization. This paper introduces an accompanying hierarchical label taxonomy, which has been designed to be compatible with other existing datasets for urban sound tagging while also able to capture sound events unique to the Singaporean context. This paper details the data collection, annotation, and processing methodologies for the creation of the dataset. We further perform exploratory data analysis and include the performance of a baseline model on the dataset as a benchmark.