 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Urban Sound Information for Residential Areas in Smart Cities Using an End-to-End IoT System
Aug 11, 2024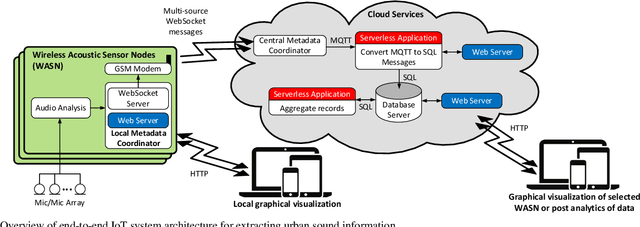



With rapid urbanization comes the increase of community, construction, and transportation noise in residential areas. The conventional approach of solely relying on sound pressure level (SPL) information to decide on the noise environment and to plan out noise control and mitigation strategies is inadequate. This paper presents an end-to-end IoT system that extracts real-time urban sound metadata using edge devices, providing information on the sound type, location and duration, rate of occurrence, loudness, and azimuth of a dominant noise in nine residential areas. The collected metadata on environmental sound is transmitted to and aggregated in a cloud-based platform to produce detailed descriptive analytics and visualization. Our approach to integrating different building blocks, namely, hardware, software, cloud technologies, and signal processing algorithms to form our real-time IoT system is outlined. We demonstrate how some of the sound metadata extracted by our system are used to provide insights into the noise in residential areas. A scalable workflow to collect and prepare audio recordings from nine residential areas to construct our urban sound dataset for training and evaluating a location-agnostic model is discussed. Some practical challenges of managing and maintaining a sensor network deployed at numerous locations are also addressed.
* 13 pages, 15 figures, journal
Automating Urban Soundscape Enhancements with AI: In-situ Assessment of Quality and Restorativeness in Traffic-Exposed Residential Areas
Jul 08, 2024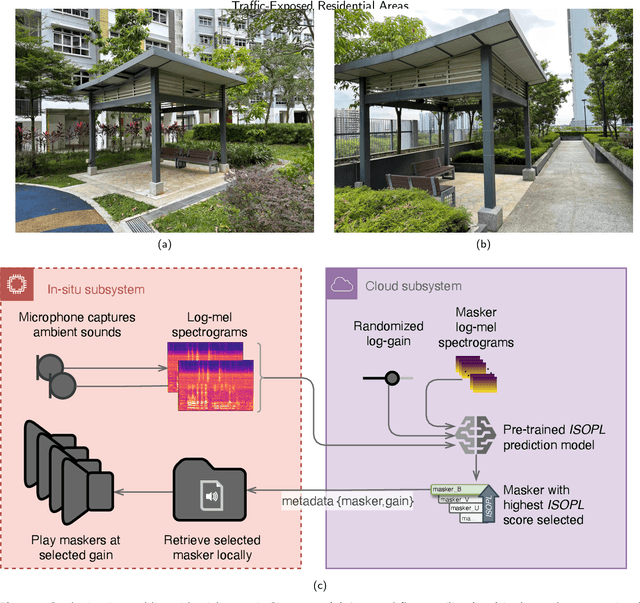

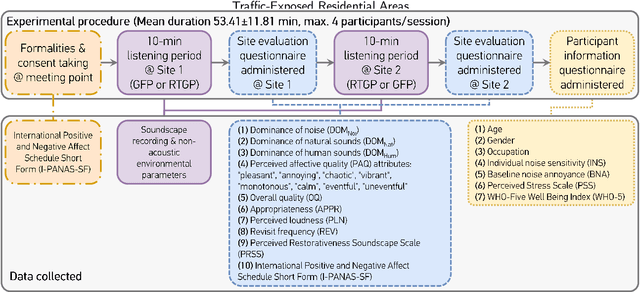

Formalized in ISO 12913, the "soundscape" approach is a paradigmatic shift towards perception-based urban sound management, aiming to alleviate the substantial socioeconomic costs of noise pollution to advance the United Nations Sustainable Development Goals. Focusing on traffic-exposed outdoor residential sites, we implemented an automatic masker selection system (AMSS) utilizing natural sounds to mask (or augment) traffic soundscapes. We employed a pre-trained AI model to automatically select the optimal masker and adjust its playback level, adapting to changes over time in the ambient environment to maximize "Pleasantness", a perceptual dimension of soundscape quality in ISO 12913. Our validation study involving ($N=68$) residents revealed a significant 14.6 % enhancement in "Pleasantness" after intervention, correlating with increased restorativeness and positive affect. Perceptual enhancements at the traffic-exposed site matched those at a quieter control site with 6 dB(A) lower $L_\text{A,eq}$ and road traffic noise dominance, affirming the efficacy of AMSS as a soundscape intervention, while streamlining the labour-intensive assessment of "Pleasantness" with probabilistic AI prediction.
Preliminary investigation of the short-term in situ performance of an automatic masker selection system
Aug 15, 2023
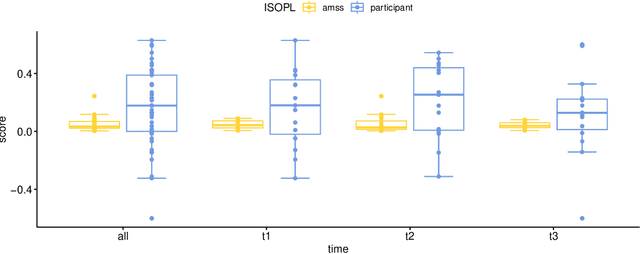
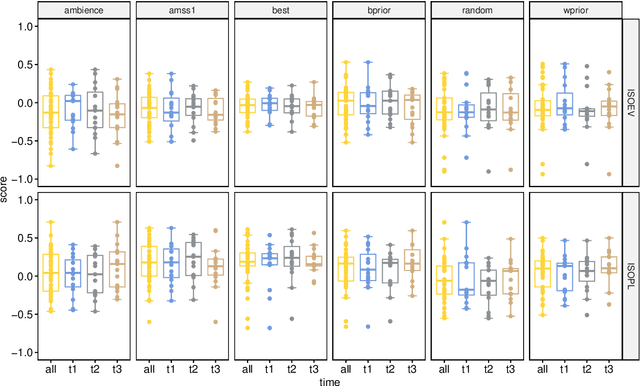

Soundscape augmentation or "masking" introduces wanted sounds into the acoustic environment to improve acoustic comfort. Usually, the masker selection and playback strategies are either arbitrary or based on simple rules (e.g. -3 dBA), which may lead to sub-optimal increment or even reduction in acoustic comfort for dynamic acoustic environments. To reduce ambiguity in the selection of maskers, an automatic masker selection system (AMSS) was recently developed. The AMSS uses a deep-learning model trained on a large-scale dataset of subjective responses to maximize the derived ISO pleasantness (ISO 12913-2). Hence, this study investigates the short-term in situ performance of the AMSS implemented in a gazebo in an urban park. Firstly, the predicted ISO pleasantness from the AMSS is evaluated in comparison to the in situ subjective evaluation scores. Secondly, the effect of various masker selection schemes on the perceived affective quality and appropriateness would be evaluated. In total, each participant evaluated 6 conditions: (1) ambient environment with no maskers; (2) AMSS; (3) bird and (4) water masker from prior art; (5) random selection from same pool of maskers used to train the AMSS; and (6) selection of best-performing maskers based on the analysis of the dataset used to train the AMSS.
Anti-noise window: Subjective perception of active noise reduction and effect of informational masking
Jul 08, 2023



Reviving natural ventilation (NV) for urban sustainability presents challenges for indoor acoustic comfort. Active control and interference-based noise mitigation strategies, such as the use of loudspeakers, offer potential solutions to achieve acoustic comfort while maintaining NV. However, these approaches are not commonly integrated or evaluated from a perceptual standpoint. This study examines the perceptual and objective aspects of an active-noise-control (ANC)-based "anti-noise" window (ANW) and its integration with informational masking (IM) in a model bedroom. Forty participants assessed the ANW in a three-way interaction involving noise types (traffic, train, and aircraft), maskers (bird, water), and ANC (on, off). The evaluation focused on perceived annoyance (PAY; ISO/TS 15666), perceived affective quality (ISO/TS 12913-2), loudness (PLN), and included an open-ended qualitative assessment. Despite minimal objective reduction in decibel-based indicators and a slight increase in psychoacoustic sharpness, the ANW alone demonstrated significant reductions in PAY and PLN, as well as an improvement in ISO pleasantness across all noise types. The addition of maskers generally enhanced overall acoustic comfort, although water masking led to increased PLN. Furthermore, the combination of ANC with maskers showed interaction effects, with both maskers significantly reducing PAY compared to ANC alone.
* Accepted manuscript submitted to Sustainable Cities and Society
Autonomous Soundscape Augmentation with Multimodal Fusion of Visual and Participant-linked Inputs
Mar 15, 2023

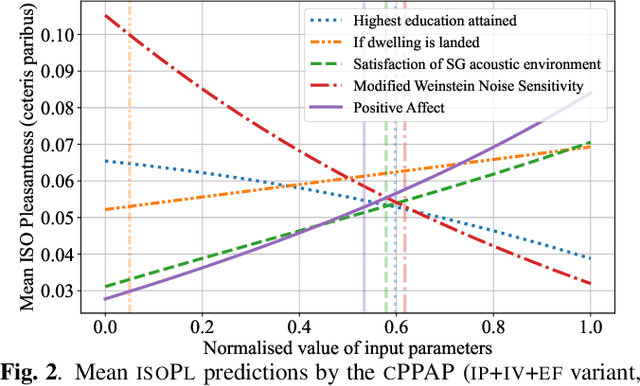
Autonomous soundscape augmentation systems typically use trained models to pick optimal maskers to effect a desired perceptual change. While acoustic information is paramount to such systems, contextual information, including participant demographics and the visual environment, also influences acoustic perception. Hence, we propose modular modifications to an existing attention-based deep neural network, to allow early, mid-level, and late feature fusion of participant-linked, visual, and acoustic features. Ablation studies on module configurations and corresponding fusion methods using the ARAUS dataset show that contextual features improve the model performance in a statistically significant manner on the normalized ISO Pleasantness, to a mean squared error of $0.1194\pm0.0012$ for the best-performing all-modality model, against $0.1217\pm0.0009$ for the audio-only model. Soundscape augmentation systems can thereby leverage multimodal inputs for improved performance. We also investigate the impact of individual participant-linked factors using trained models to illustrate improvements in model explainability.
Assessment of a cost-effective headphone calibration procedure for soundscape evaluations
Jul 24, 2022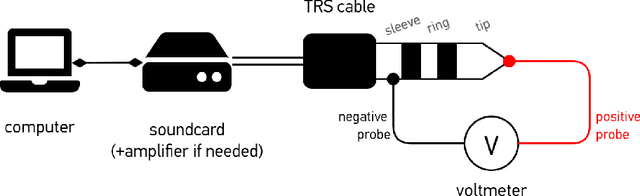

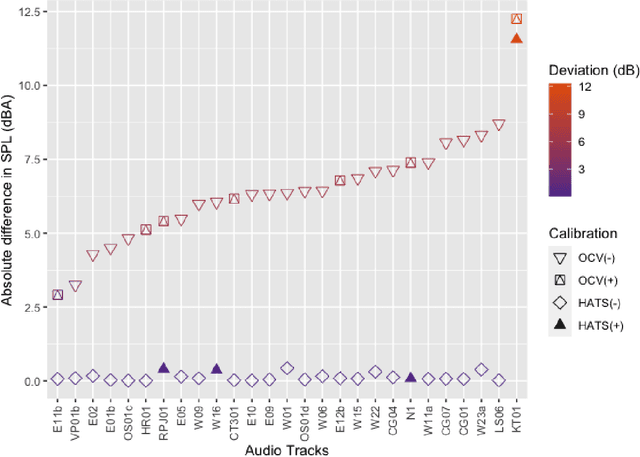
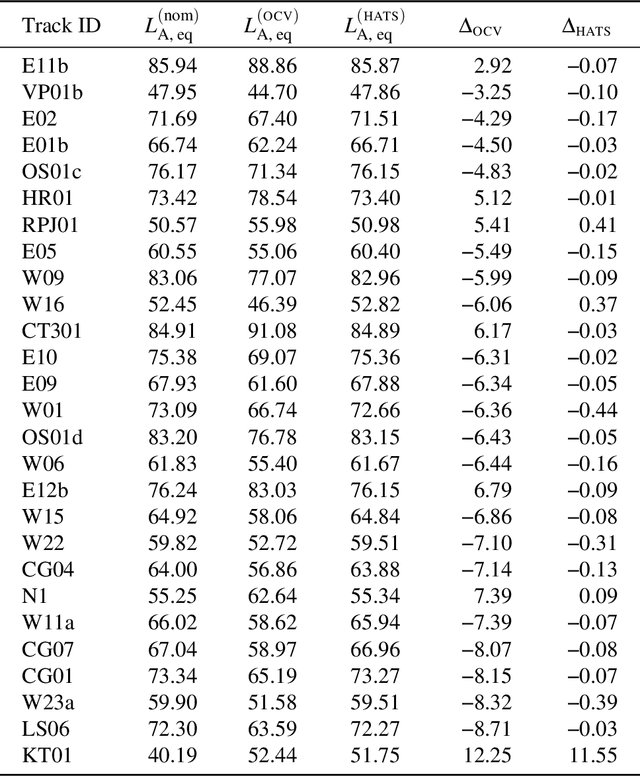
To increase the availability and adoption of the soundscape standard, a low-cost calibration procedure for reproduction of audio stimuli over headphones was proposed as part of the global ``Soundscape Attributes Translation Project'' (SATP) for validating ISO/TS~12913-2:2018 perceived affective quality (PAQ) attribute translations. A previous preliminary study revealed significant deviations from the intended equivalent continuous A-weighted sound pressure levels ($L_{\text{A,eq}}$) using the open-circuit voltage (OCV) calibration procedure. For a more holistic human-centric perspective, the OCV method is further investigated here in terms of psychoacoustic parameters, including relevant exceedance levels to account for temporal effects on the same 27 stimuli from the SATP. Moreover, a within-subjects experiment with 36 participants was conducted to examine the effects of OCV calibration on the PAQ attributes in ISO/TS~12913-2:2018. Bland-Altman analysis of the objective indicators revealed large biases in the OCV method across all weighted sound level and loudness indicators; and roughness indicators at \SI{5}{\%} and \SI{10}{\%} exceedance levels. Significant perceptual differences due to the OCV method were observed in about \SI{20}{\%} of the stimuli, which did not correspond clearly with the biased acoustic indicators. A cautioned interpretation of the objective and perceptual differences due to small and unpaired samples nevertheless provide grounds for further investigation.
Do uHear? Validation of uHear App for Preliminary Screening of Hearing Ability in Soundscape Studies
Jul 16, 2022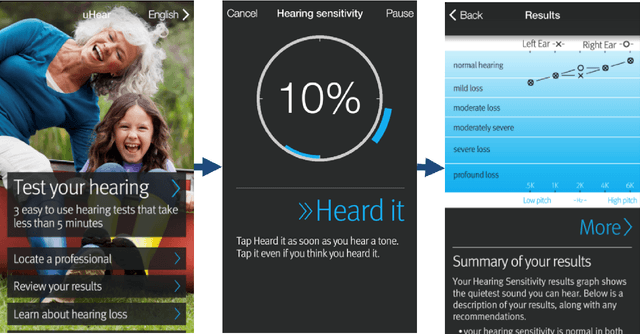

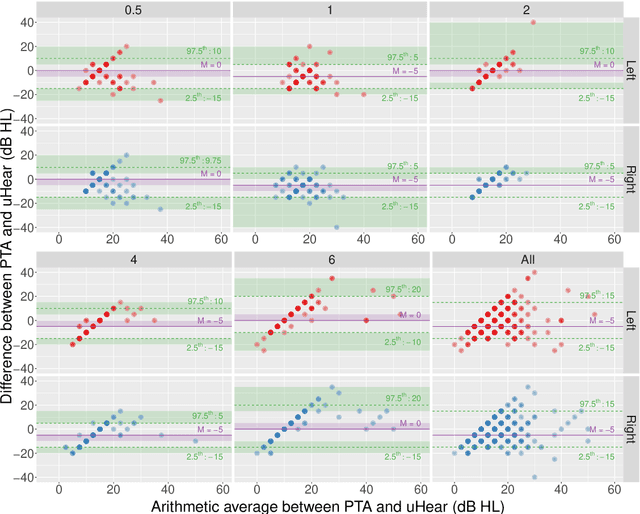
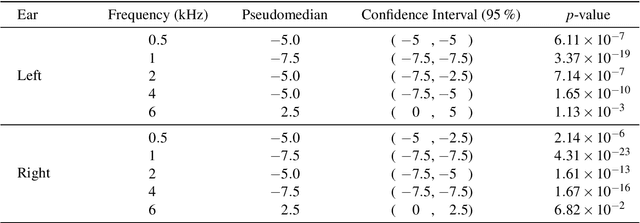
Studies involving soundscape perception often exclude participants with hearing loss to prevent impaired perception from affecting experimental results. Participants are typically screened with pure tone audiometry, the "gold standard" for identifying and quantifying hearing loss at specific frequencies, and excluded if a study-dependent threshold is not met. However, procuring professional audiometric equipment for soundscape studies may be cost-ineffective, and manually performing audiometric tests is labour-intensive. Moreover, testing requirements for soundscape studies may not require sensitivities and specificities as high as that in a medical diagnosis setting. Hence, in this study, we investigate the effectiveness of the uHear app, an iOS application, as an affordable and automatic alternative to a conventional audiometer in screening participants for hearing loss for the purpose of soundscape studies or listening tests in general. Based on audiometric comparisons with the audiometer of 163 participants, the uHear app was found to have high precision (98.04%) when using the World Health Organization (WHO) grading scheme for assessing normal hearing. Precision is further improved (98.69%) when all frequencies assessed with the uHear app is considered in the grading, which lends further support to this cost-effective, automated alternative to screen for normal hearing.
ARAUS: A Large-Scale Dataset and Baseline Models of Affective Responses to Augmented Urban Soundscapes
Jul 05, 2022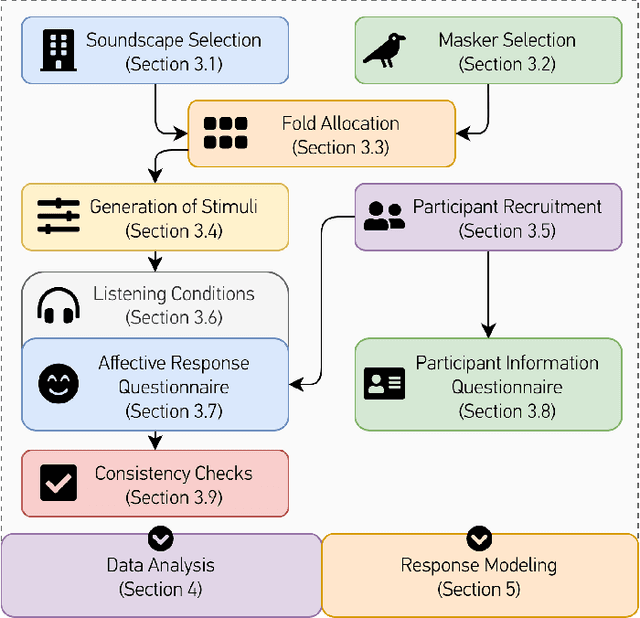
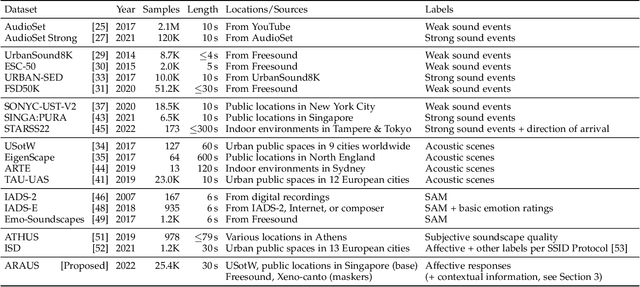
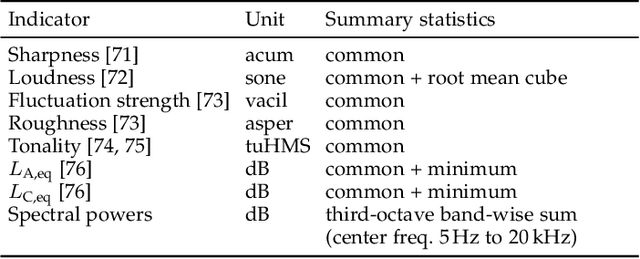
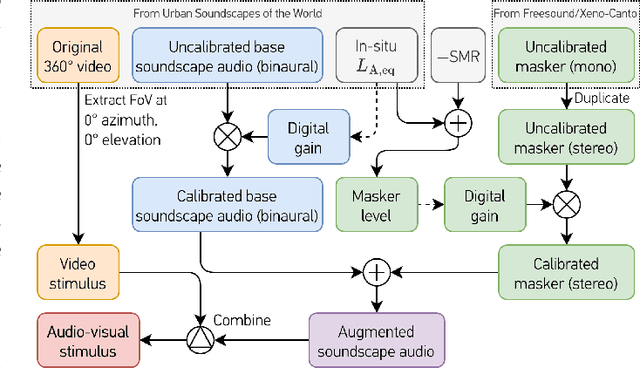
Choosing optimal maskers for existing soundscapes to effect a desired perceptual change via soundscape augmentation is non-trivial due to extensive varieties of maskers and a dearth of benchmark datasets with which to compare and develop soundscape augmentation models. To address this problem, we make publicly available the ARAUS (Affective Responses to Augmented Urban Soundscapes) dataset, which comprises a five-fold cross-validation set and independent test set totaling 25,440 unique subjective perceptual responses to augmented soundscapes presented as audio-visual stimuli. Each augmented soundscape is made by digitally adding "maskers" (bird, water, wind, traffic, construction, or silence) to urban soundscape recordings at fixed soundscape-to-masker ratios. Responses were then collected by asking participants to rate how pleasant, annoying, eventful, uneventful, vibrant, monotonous, chaotic, calm, and appropriate each augmented soundscape was, in accordance with ISO 12913-2:2018. Participants also provided relevant demographic information and completed standard psychological questionnaires. We perform exploratory and statistical analysis of the responses obtained to verify internal consistency and agreement with known results in the literature. Finally, we demonstrate the benchmarking capability of the dataset by training and comparing four baseline models for urban soundscape pleasantness: a low-parameter regression model, a high-parameter convolutional neural network, and two attention-based networks in the literature.
Singapore Soundscape Site Selection Survey (S5): Identification of Characteristic Soundscapes of Singapore via Weighted k-means Clustering
Jun 07, 2022
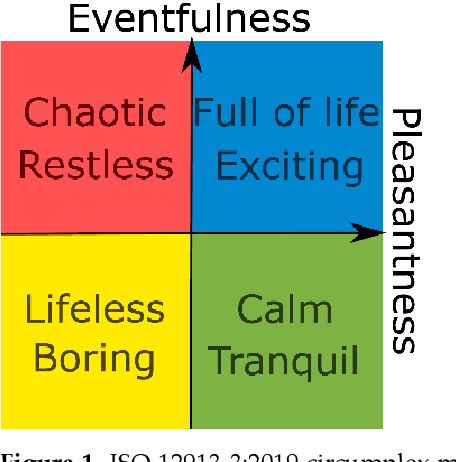
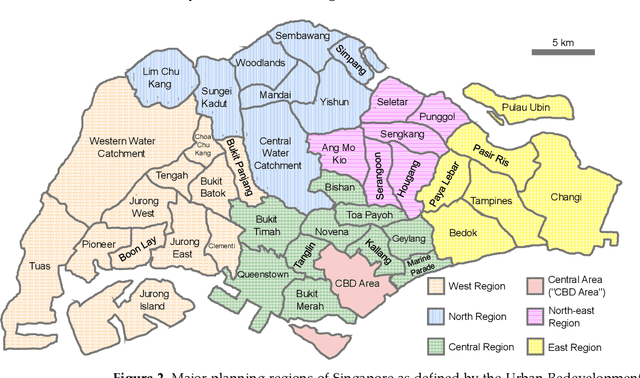

The ecological validity of soundscape studies usually rests on a choice of soundscapes that are representative of the perceptual space under investigation. For example, a soundscape pleasantness study might investigate locations with soundscapes ranging from "pleasant" to "annoying". The choice of soundscapes is typically researcher-led, but a participant-led process can reduce selection bias and improve result reliability. Hence, we propose a robust participant-led method to pinpoint characteristic soundscapes possessing arbitrary perceptual attributes. We validate our method by identifying Singaporean soundscapes spanning the perceptual quadrants generated from the "Pleasantness" and "Eventfulness" axes of the ISO 12913-2 circumplex model of soundscape perception, as perceived by local experts. From memory and experience, 67 participants first selected locations corresponding to each perceptual quadrant in each major planning region of Singapore. We then performed weighted k-means clustering on the selected locations, with weights for each location derived from previous frequencies and durations spent in each location by each participant. Weights hence acted as proxies for participant confidence. In total, 62 locations were thereby identified as suitable locations with characteristic soundscapes for further research utilizing the ISO 12913-2 perceptual quadrants. Audio-visual recordings and acoustic characterization of the soundscapes will be made in a future study.
Crossing the Linguistic Causeway: A Binational Approach for Translating Soundscape Attributes to Bahasa Melayu
Jun 07, 2022
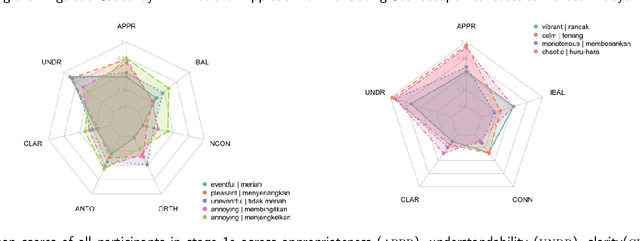
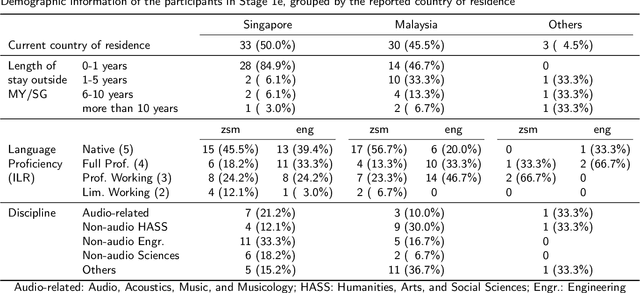

Translation of perceptual descriptors such as the perceived affective quality attributes in the soundscape standard (ISO/TS 12913-2:2018) is an inherently intricate task, especially if the target language is used in multiple countries. Despite geographical proximity and a shared language of Bahasa Melayu (Standard Malay), differences in culture and language education policies between Singapore and Malaysia could invoke peculiarities in the affective appraisal of sounds. To generate provisional translations of the eight perceived affective attributes -- eventful, vibrant, pleasant, calm, uneventful, monotonous, annoying, and chaotic -- into Bahasa Melayu that is applicable in both Singapore and Malaysia, a binational expert-led approach supplemented by a quantitative evaluation framework was adopted. A set of preliminary translation candidates were developed via a four-stage process, firstly by a qualified translator, which was then vetted by linguistics experts, followed by examination via an experiential evaluation, and finally reviewed by the core research team. A total of 66 participants were then recruited cross-nationally to quantitatively evaluate the preliminary translation candidates. Of the eight attributes, cross-national differences were observed only in the translation of annoying. For instance, "menjengkelkan" was found to be significantly less understood in Singapore than in Malaysia, as well as less understandable than "membingitkan" within Singapore. Results of the quantitative evaluation also revealed the imperfect nature of foreign language translations for perceptual descriptors, which suggests a possibility for exploring corrective measures.