 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Urban Soundscape Enhancements with AI: In-situ Assessment of Quality and Restorativeness in Traffic-Exposed Residential Areas
Jul 08, 2024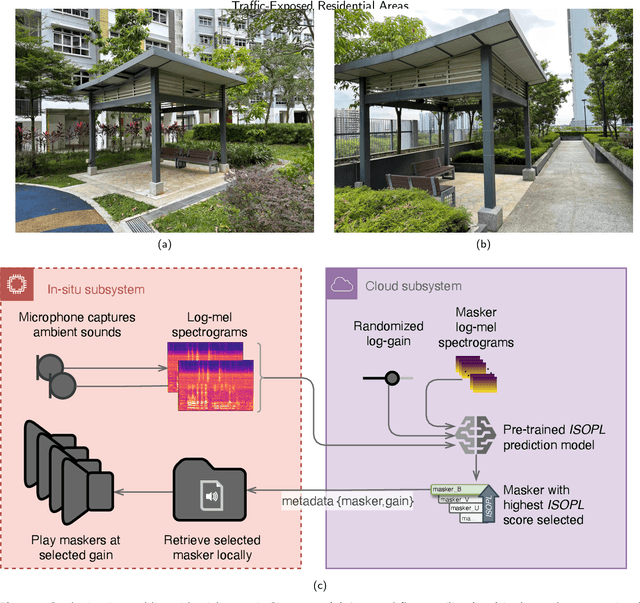


Formalized in ISO 12913, the "soundscape" approach is a paradigmatic shift towards perception-based urban sound management, aiming to alleviate the substantial socioeconomic costs of noise pollution to advance the United Nations Sustainable Development Goals. Focusing on traffic-exposed outdoor residential sites, we implemented an automatic masker selection system (AMSS) utilizing natural sounds to mask (or augment) traffic soundscapes. We employed a pre-trained AI model to automatically select the optimal masker and adjust its playback level, adapting to changes over time in the ambient environment to maximize "Pleasantness", a perceptual dimension of soundscape quality in ISO 12913. Our validation study involving ($N=68$) residents revealed a significant 14.6 % enhancement in "Pleasantness" after intervention, correlating with increased restorativeness and positive affect. Perceptual enhancements at the traffic-exposed site matched those at a quieter control site with 6 dB(A) lower $L_\text{A,eq}$ and road traffic noise dominance, affirming the efficacy of AMSS as a soundscape intervention, while streamlining the labour-intensive assessment of "Pleasantness" with probabilistic AI prediction.
Preliminary investigation of the short-term in situ performance of an automatic masker selection system
Aug 15, 2023
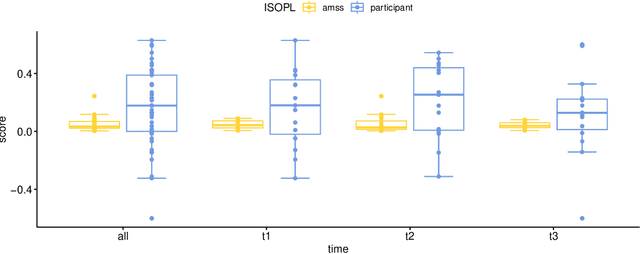
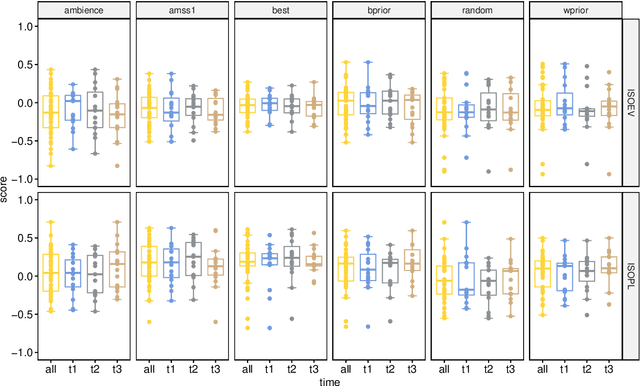

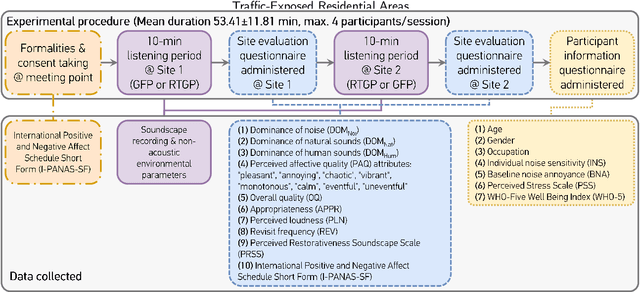
Soundscape augmentation or "masking" introduces wanted sounds into the acoustic environment to improve acoustic comfort. Usually, the masker selection and playback strategies are either arbitrary or based on simple rules (e.g. -3 dBA), which may lead to sub-optimal increment or even reduction in acoustic comfort for dynamic acoustic environments. To reduce ambiguity in the selection of maskers, an automatic masker selection system (AMSS) was recently developed. The AMSS uses a deep-learning model trained on a large-scale dataset of subjective responses to maximize the derived ISO pleasantness (ISO 12913-2). Hence, this study investigates the short-term in situ performance of the AMSS implemented in a gazebo in an urban park. Firstly, the predicted ISO pleasantness from the AMSS is evaluated in comparison to the in situ subjective evaluation scores. Secondly, the effect of various masker selection schemes on the perceived affective quality and appropriateness would be evaluated. In total, each participant evaluated 6 conditions: (1) ambient environment with no maskers; (2) AMSS; (3) bird and (4) water masker from prior art; (5) random selection from same pool of maskers used to train the AMSS; and (6) selection of best-performing maskers based on the analysis of the dataset used to train the AMSS.
Assessment of a cost-effective headphone calibration procedure for soundscape evaluations
Jul 24, 2022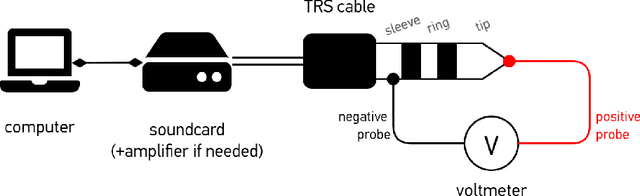

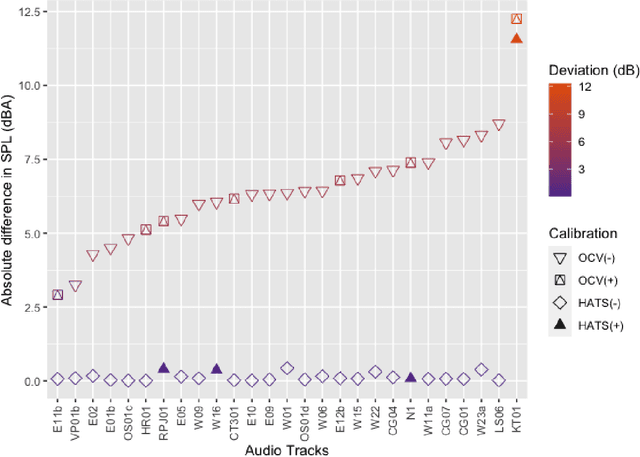
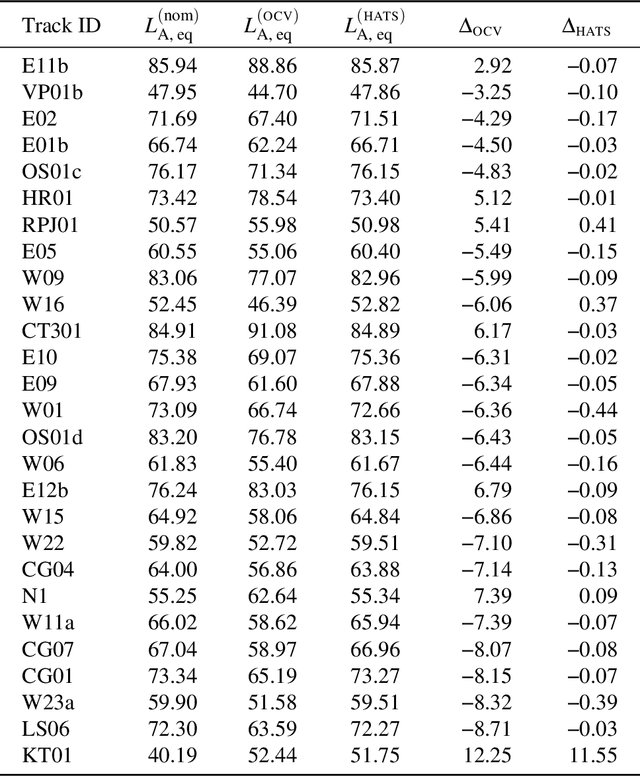
To increase the availability and adoption of the soundscape standard, a low-cost calibration procedure for reproduction of audio stimuli over headphones was proposed as part of the global ``Soundscape Attributes Translation Project'' (SATP) for validating ISO/TS~12913-2:2018 perceived affective quality (PAQ) attribute translations. A previous preliminary study revealed significant deviations from the intended equivalent continuous A-weighted sound pressure levels ($L_{\text{A,eq}}$) using the open-circuit voltage (OCV) calibration procedure. For a more holistic human-centric perspective, the OCV method is further investigated here in terms of psychoacoustic parameters, including relevant exceedance levels to account for temporal effects on the same 27 stimuli from the SATP. Moreover, a within-subjects experiment with 36 participants was conducted to examine the effects of OCV calibration on the PAQ attributes in ISO/TS~12913-2:2018. Bland-Altman analysis of the objective indicators revealed large biases in the OCV method across all weighted sound level and loudness indicators; and roughness indicators at \SI{5}{\%} and \SI{10}{\%} exceedance levels. Significant perceptual differences due to the OCV method were observed in about \SI{20}{\%} of the stimuli, which did not correspond clearly with the biased acoustic indicators. A cautioned interpretation of the objective and perceptual differences due to small and unpaired samples nevertheless provide grounds for further investigation.
Do uHear? Validation of uHear App for Preliminary Screening of Hearing Ability in Soundscape Studies
Jul 16, 2022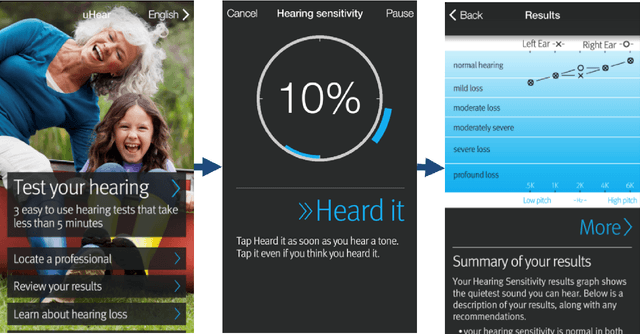

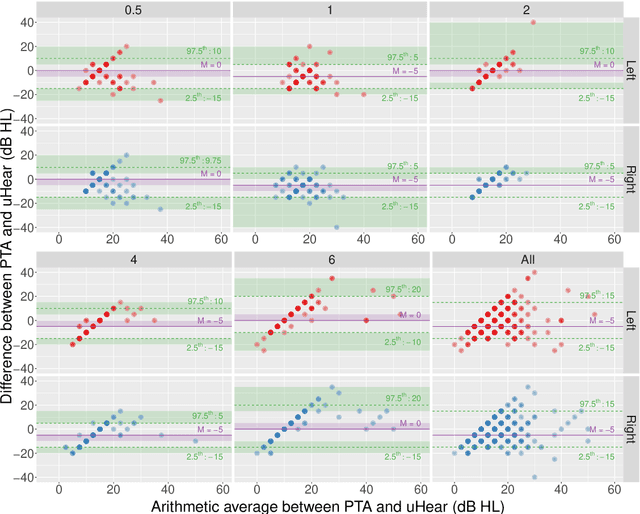
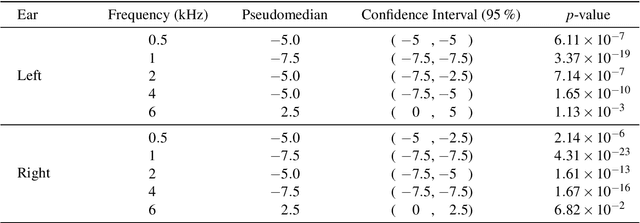
Studies involving soundscape perception often exclude participants with hearing loss to prevent impaired perception from affecting experimental results. Participants are typically screened with pure tone audiometry, the "gold standard" for identifying and quantifying hearing loss at specific frequencies, and excluded if a study-dependent threshold is not met. However, procuring professional audiometric equipment for soundscape studies may be cost-ineffective, and manually performing audiometric tests is labour-intensive. Moreover, testing requirements for soundscape studies may not require sensitivities and specificities as high as that in a medical diagnosis setting. Hence, in this study, we investigate the effectiveness of the uHear app, an iOS application, as an affordable and automatic alternative to a conventional audiometer in screening participants for hearing loss for the purpose of soundscape studies or listening tests in general. Based on audiometric comparisons with the audiometer of 163 participants, the uHear app was found to have high precision (98.04%) when using the World Health Organization (WHO) grading scheme for assessing normal hearing. Precision is further improved (98.69%) when all frequencies assessed with the uHear app is considered in the grading, which lends further support to this cost-effective, automated alternative to screen for normal hearing.
Preliminary assessment of a cost-effective headphone calibration procedure for soundscape evaluations
May 10, 2022The introduction of ISO 12913-2:2018 has provided a framework for standardized data collection and reporting procedures for soundscape practitioners. A strong emphasis was placed on the use of calibrated head and torso simulators (HATS) for binaural audio capture to obtain an accurate subjective impression and acoustic measure of the soundscape under evaluation. To auralise the binaural recordings as recorded or at set levels, the audio stimuli and the headphone setup are usually calibrated with a HATS. However, calibrated HATS are too financially prohibitive for most research teams, inevitably diminishing the availability of the soundscape standard. With the increasing availability of soundscape binaural recording datasets, and the importance of cross-cultural validation of the soundscape ISO standards, e.g.\ via the Soundscape Attributes Translation Project (SATP), it is imperative to assess the suitability of cost-effective headphone calibration methods to maximise availability without severely compromising on accuracy. Hence, this study objectively examines an open-circuit voltage (OCV) calibration method in comparison to a calibrated HATS on various soundcard and headphone combinations. Preliminary experiments found that calibration with the OCV method differed significantly from the reference binaural recordings in sound pressure levels, whereas negligible differences in levels were observed with the HATS calibration.
Deployment of an IoT System for Adaptive In-Situ Soundscape Augmentation
Apr 29, 2022
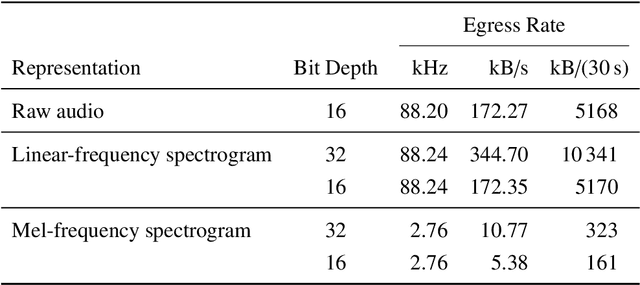

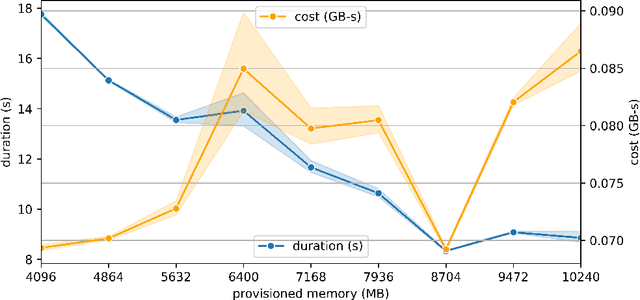
Soundscape augmentation is an emerging approach for noise mitigation by introducing additional sounds known as "maskers" to increase acoustic comfort. Traditionally, the choice of maskers is often predicated on expert guidance or post-hoc analysis which can be time-consuming and sometimes arbitrary. Moreover, this often results in a static set of maskers that are inflexible to the dynamic nature of real-world acoustic environments. Overcoming the inflexibility of traditional soundscape augmentation is twofold. First, given a snapshot of a soundscape, the system must be able to select an optimal masker without human supervision. Second, the system must also be able to react to changes in the acoustic environment with near real-time latency. In this work, we harness the combined prowess of cloud computing and the Internet of Things (IoT) to allow in-situ listening and playback using microcontrollers while delegating computationally expensive inference tasks to the cloud. In particular, a serverless cloud architecture was used for inference, ensuring near real-time latency and scalability without the need to provision computing resources. A working prototype of the system is currently being deployed in a public area experiencing high traffic noise, as well as undergoing public evaluation for future improvements.
Autonomous In-Situ Soundscape Augmentation via Joint Selection of Masker and Gain
Apr 29, 2022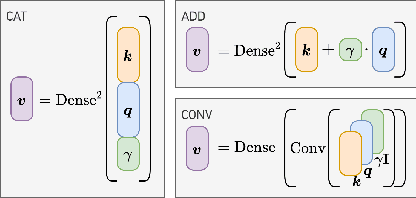
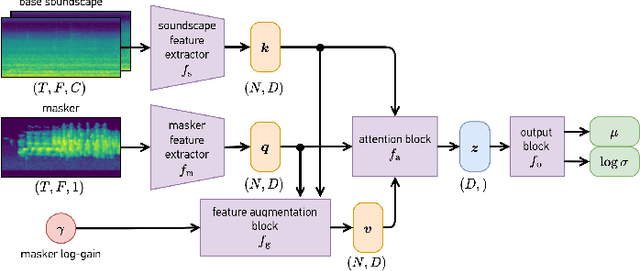
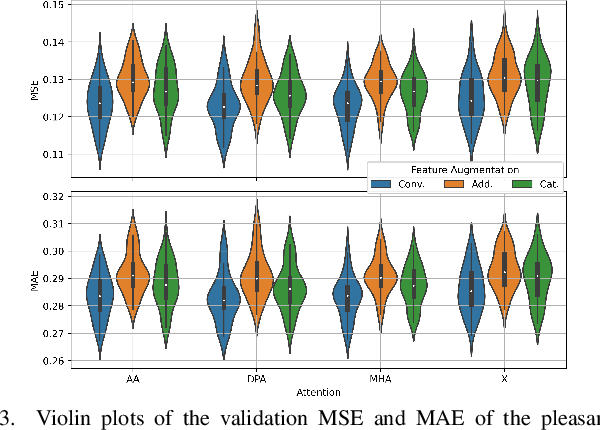
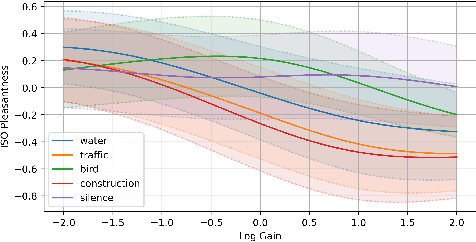
The selection of maskers and playback gain levels in a soundscape augmentation system is crucial to its effectiveness in improving the overall acoustic comfort of a given environment. Traditionally, the selection of appropriate maskers and gain levels has been informed by expert opinion, which may not representative of the target population, or by listening tests, which can be time-consuming and labour-intensive. Furthermore, the resulting static choices of masker and gain are often inflexible to the dynamic nature of real-world soundscapes. In this work, we utilized a deep learning model to perform joint selection of the optimal masker and its gain level for a given soundscape. The proposed model was designed with highly modular building blocks, allowing for an optimized inference process that can quickly search through a large number of masker and gain combinations. In addition, we introduced the use of feature-domain soundscape augmentation conditioned on the digital gain level, eliminating the computationally expensive waveform-domain mixing process during inference time, as well as the tedious pre-calibration process required for new maskers. The proposed system was validated on a large-scale dataset of subjective responses to augmented soundscapes with more than 440 participants, ensuring the ability of the model to predict combined effect of the masker and its gain level on the perceptual pleasantness level.