 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Urban Soundscape Enhancements with AI: In-situ Assessment of Quality and Restorativeness in Traffic-Exposed Residential Areas
Jul 08, 2024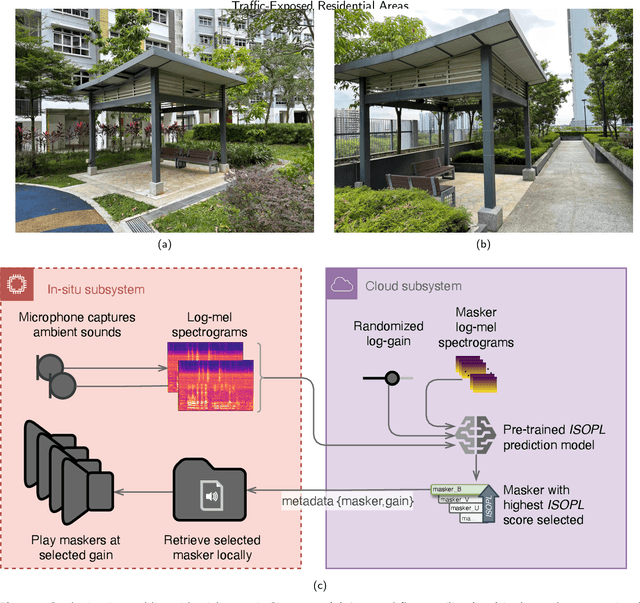


Formalized in ISO 12913, the "soundscape" approach is a paradigmatic shift towards perception-based urban sound management, aiming to alleviate the substantial socioeconomic costs of noise pollution to advance the United Nations Sustainable Development Goals. Focusing on traffic-exposed outdoor residential sites, we implemented an automatic masker selection system (AMSS) utilizing natural sounds to mask (or augment) traffic soundscapes. We employed a pre-trained AI model to automatically select the optimal masker and adjust its playback level, adapting to changes over time in the ambient environment to maximize "Pleasantness", a perceptual dimension of soundscape quality in ISO 12913. Our validation study involving ($N=68$) residents revealed a significant 14.6 % enhancement in "Pleasantness" after intervention, correlating with increased restorativeness and positive affect. Perceptual enhancements at the traffic-exposed site matched those at a quieter control site with 6 dB(A) lower $L_\text{A,eq}$ and road traffic noise dominance, affirming the efficacy of AMSS as a soundscape intervention, while streamlining the labour-intensive assessment of "Pleasantness" with probabilistic AI prediction.
Preliminary investigation of the short-term in situ performance of an automatic masker selection system
Aug 15, 2023
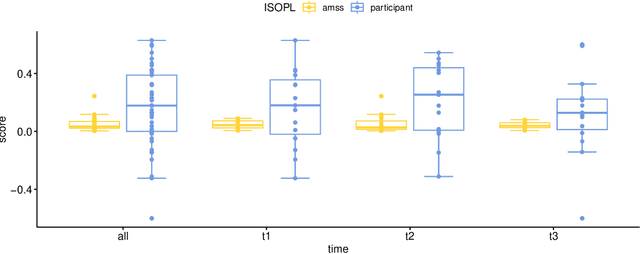
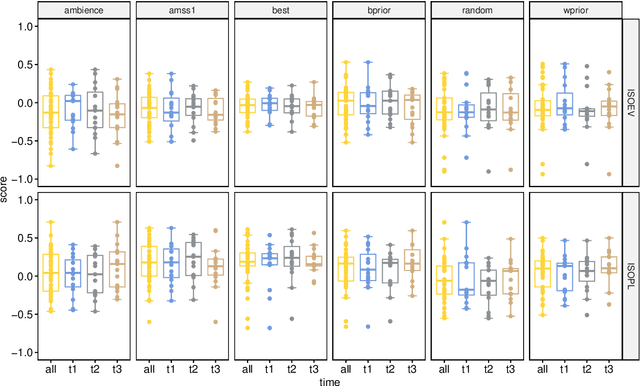

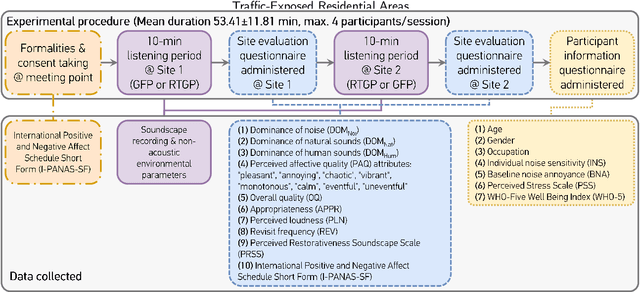
Soundscape augmentation or "masking" introduces wanted sounds into the acoustic environment to improve acoustic comfort. Usually, the masker selection and playback strategies are either arbitrary or based on simple rules (e.g. -3 dBA), which may lead to sub-optimal increment or even reduction in acoustic comfort for dynamic acoustic environments. To reduce ambiguity in the selection of maskers, an automatic masker selection system (AMSS) was recently developed. The AMSS uses a deep-learning model trained on a large-scale dataset of subjective responses to maximize the derived ISO pleasantness (ISO 12913-2). Hence, this study investigates the short-term in situ performance of the AMSS implemented in a gazebo in an urban park. Firstly, the predicted ISO pleasantness from the AMSS is evaluated in comparison to the in situ subjective evaluation scores. Secondly, the effect of various masker selection schemes on the perceived affective quality and appropriateness would be evaluated. In total, each participant evaluated 6 conditions: (1) ambient environment with no maskers; (2) AMSS; (3) bird and (4) water masker from prior art; (5) random selection from same pool of maskers used to train the AMSS; and (6) selection of best-performing maskers based on the analysis of the dataset used to train the AMSS.
Active Noise Control based on the Momentum Multichannel Normalized Filtered-x Least Mean Square Algorithm
Aug 07, 2023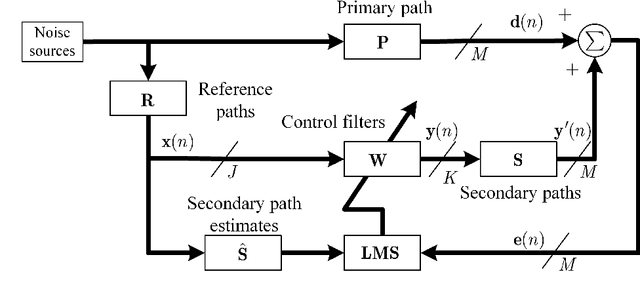
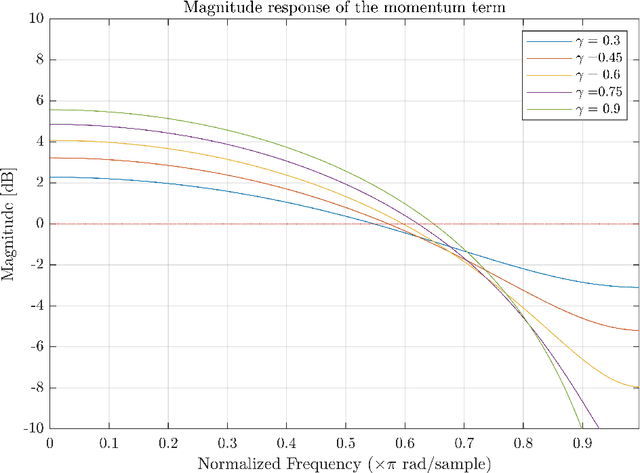

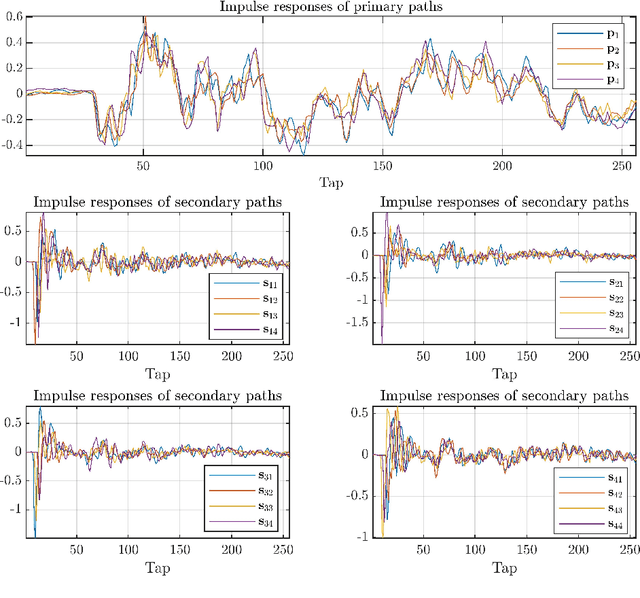
Multichannel active noise control (MCANC) is widely utilized to achieve significant noise cancellation area in the complicated acoustic field. Meanwhile, the filter-x least mean square (FxLMS) algorithm gradually becomes the benchmark solution for the implementation of MCANC due to its low computational complexity. However, its slow convergence speed more or less undermines the performance of dealing with quickly varying disturbances, such as piling noise. Furthermore, the noise power variation also deteriorates the robustness of the algorithm when it adopts the fixed step size. To solve these issues, we integrated the normalized multichannel FxLMS with the momentum method, which hence, effectively avoids the interference of the primary noise power and accelerates the convergence of the algorithm. To validate its effectiveness, we deployed this algorithm in a multichannel noise control window to control the real machine noise.
Anti-noise window: Subjective perception of active noise reduction and effect of informational masking
Jul 08, 2023



Reviving natural ventilation (NV) for urban sustainability presents challenges for indoor acoustic comfort. Active control and interference-based noise mitigation strategies, such as the use of loudspeakers, offer potential solutions to achieve acoustic comfort while maintaining NV. However, these approaches are not commonly integrated or evaluated from a perceptual standpoint. This study examines the perceptual and objective aspects of an active-noise-control (ANC)-based "anti-noise" window (ANW) and its integration with informational masking (IM) in a model bedroom. Forty participants assessed the ANW in a three-way interaction involving noise types (traffic, train, and aircraft), maskers (bird, water), and ANC (on, off). The evaluation focused on perceived annoyance (PAY; ISO/TS 15666), perceived affective quality (ISO/TS 12913-2), loudness (PLN), and included an open-ended qualitative assessment. Despite minimal objective reduction in decibel-based indicators and a slight increase in psychoacoustic sharpness, the ANW alone demonstrated significant reductions in PAY and PLN, as well as an improvement in ISO pleasantness across all noise types. The addition of maskers generally enhanced overall acoustic comfort, although water masking led to increased PLN. Furthermore, the combination of ANC with maskers showed interaction effects, with both maskers significantly reducing PAY compared to ANC alone.
* Accepted manuscript submitted to Sustainable Cities and Society
MOV-Modified-FxLMS algorithm with Variable Penalty Factor in a Practical Power Output Constrained Active Control System
Jun 15, 2023Practical Active Noise Control (ANC) systems typically require a restriction in their maximum output power, to prevent overdriving the loudspeaker and causing system instability. Recently, the minimum output variance filtered-reference least mean square (MOV-FxLMS) algorithm was shown to have optimal control under output constraint with an analytically formulated penalty factor, but it needs offline knowledge of disturbance power and secondary path gain. The constant penalty factor in MOV-FxLMS is also susceptible to variations in disturbance power that could cause output power constraint violations. This paper presents a new variable penalty factor that utilizes the estimated disturbance in the established Modified-FxLMS (MFxLMS) algorithm, resulting in a computationally efficient MOV-MFxLMS algorithm that can adapt to changes in disturbance levels in real-time. Numerical simulation with real noise and plant response showed that the variable penalty factor always manages to meet its maximum power output constraint despite sudden changes in disturbance power, whereas the fixed penalty factor has suffered from a constraint mismatch.
Active Noise Control in The New Century: The Role and Prospect of Signal Processing
Jun 02, 2023

Since Paul Leug's 1933 patent application for a system for the active control of sound, the field of active noise control (ANC) has not flourished until the advent of digital signal processors forty years ago. Early theoretical advancements in digital signal processing and processors laid the groundwork for the phenomenal growth of the field, particularly over the past quarter-century. The widespread commercial success of ANC in aircraft cabins, automobile cabins, and headsets demonstrates the immeasurable public health and economic benefits of ANC. This article continues where Elliott and Nelson's 1993 Signal Processing Magazine article and Elliott's 1997 50th anniversary commentary~\cite{kahrs1997past} on ANC left off, tracing the technical developments and applications in ANC spurred by the seminal texts of Nelson and Elliott (1991), Kuo and Morgan (1996), Hansen and Snyder (1996), and Elliott (2001) since the turn of the century. This article focuses on technical developments pertaining to real-world implementations, such as improving algorithmic convergence, reducing system latency, and extending control to non-stationary and/or broadband noise, as well as the commercial transition challenges from analog to digital ANC systems. Finally, open issues and the future of ANC in the era of artificial intelligence are discussed.
Real-time modelling of observation filter in the Remote Microphone Technique for an Active Noise Control application
Mar 21, 2023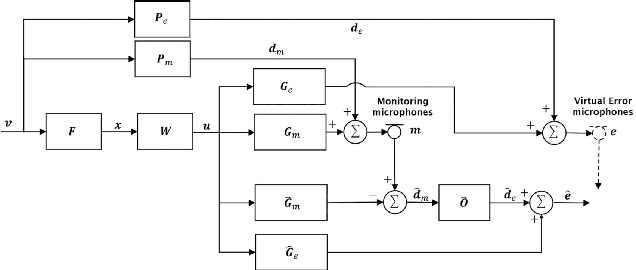
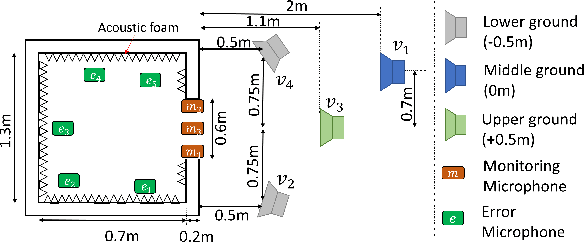
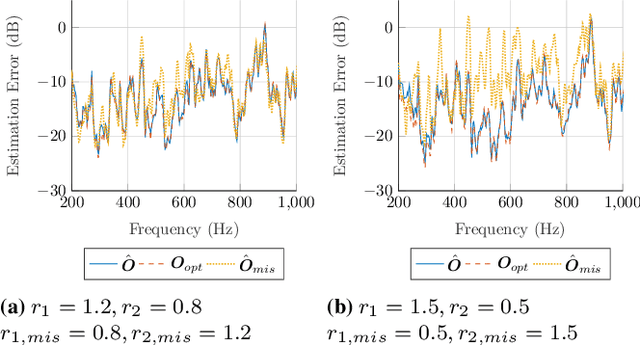
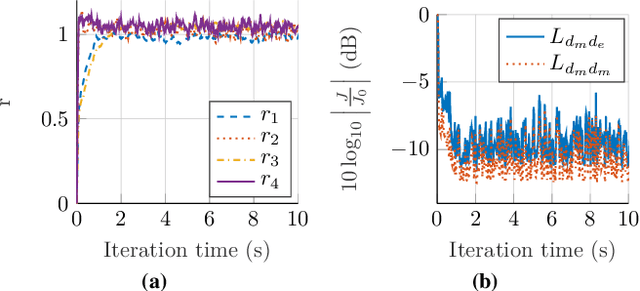
The remote microphone technique (RMT) is often used in active noise control (ANC) applications to overcome design constraints in microphone placements by estimating the acoustic pressure at inconvenient locations using a pre-calibrated observation filter (OF), albeit limited to stationary primary acoustic fields. While the OF estimation in varying primary fields can be significantly improved through the recently proposed source decomposition technique, it requires knowledge of the relative source strengths between incoherent primary noise sources. This paper proposes a method for combining the RMT with a new source-localization technique to estimate the source ratio parameter. Unlike traditional source-localization techniques, the proposed method is capable of being implemented in a real-time RMT application. Simulations with measured responses from an open-aperture ANC application showed a good estimation of the source ratio parameter, which allows the observation filter to be modelled in real-time.
Autonomous Soundscape Augmentation with Multimodal Fusion of Visual and Participant-linked Inputs
Mar 15, 2023

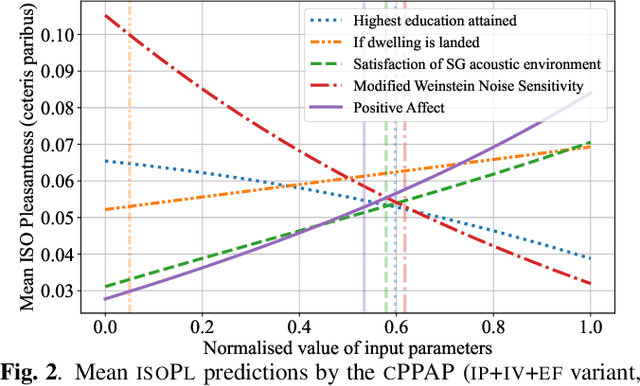
Autonomous soundscape augmentation systems typically use trained models to pick optimal maskers to effect a desired perceptual change. While acoustic information is paramount to such systems, contextual information, including participant demographics and the visual environment, also influences acoustic perception. Hence, we propose modular modifications to an existing attention-based deep neural network, to allow early, mid-level, and late feature fusion of participant-linked, visual, and acoustic features. Ablation studies on module configurations and corresponding fusion methods using the ARAUS dataset show that contextual features improve the model performance in a statistically significant manner on the normalized ISO Pleasantness, to a mean squared error of $0.1194\pm0.0012$ for the best-performing all-modality model, against $0.1217\pm0.0009$ for the audio-only model. Soundscape augmentation systems can thereby leverage multimodal inputs for improved performance. We also investigate the impact of individual participant-linked factors using trained models to illustrate improvements in model explainability.
Assessment of a cost-effective headphone calibration procedure for soundscape evaluations
Jul 24, 2022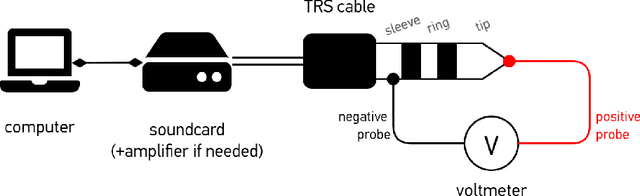

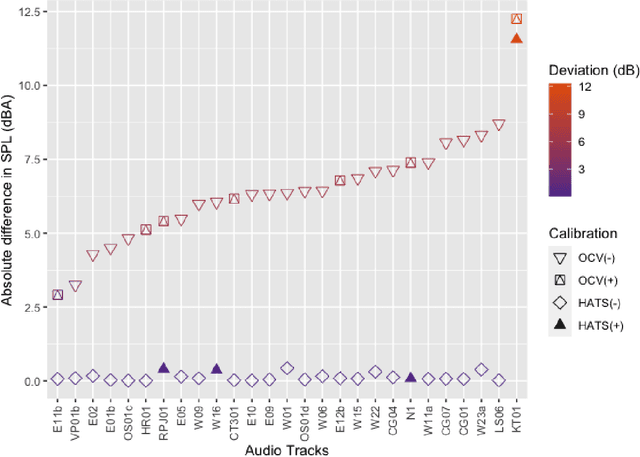
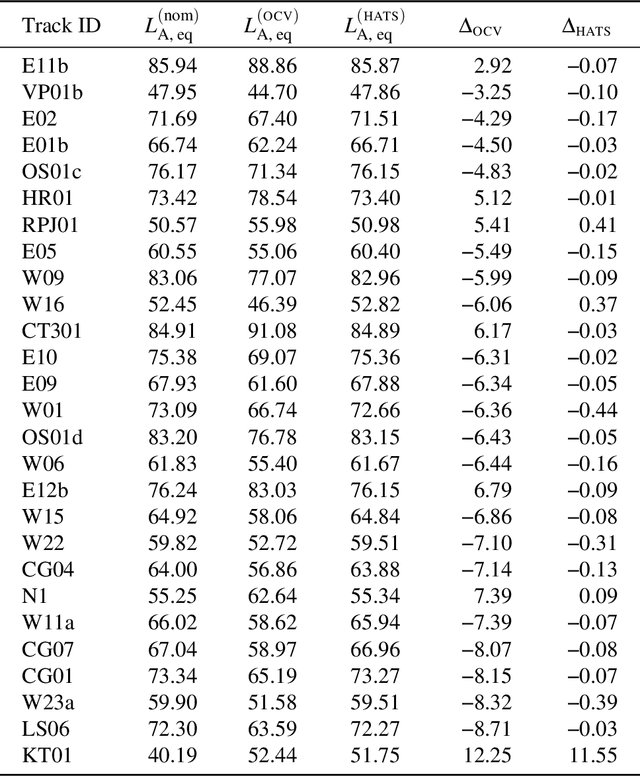
To increase the availability and adoption of the soundscape standard, a low-cost calibration procedure for reproduction of audio stimuli over headphones was proposed as part of the global ``Soundscape Attributes Translation Project'' (SATP) for validating ISO/TS~12913-2:2018 perceived affective quality (PAQ) attribute translations. A previous preliminary study revealed significant deviations from the intended equivalent continuous A-weighted sound pressure levels ($L_{\text{A,eq}}$) using the open-circuit voltage (OCV) calibration procedure. For a more holistic human-centric perspective, the OCV method is further investigated here in terms of psychoacoustic parameters, including relevant exceedance levels to account for temporal effects on the same 27 stimuli from the SATP. Moreover, a within-subjects experiment with 36 participants was conducted to examine the effects of OCV calibration on the PAQ attributes in ISO/TS~12913-2:2018. Bland-Altman analysis of the objective indicators revealed large biases in the OCV method across all weighted sound level and loudness indicators; and roughness indicators at \SI{5}{\%} and \SI{10}{\%} exceedance levels. Significant perceptual differences due to the OCV method were observed in about \SI{20}{\%} of the stimuli, which did not correspond clearly with the biased acoustic indicators. A cautioned interpretation of the objective and perceptual differences due to small and unpaired samples nevertheless provide grounds for further investigation.
Do uHear? Validation of uHear App for Preliminary Screening of Hearing Ability in Soundscape Studies
Jul 16, 2022

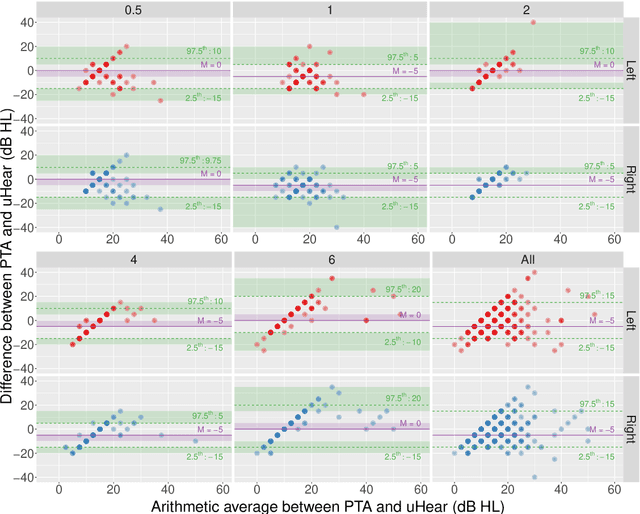
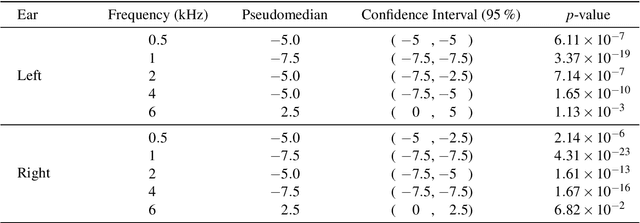
Studies involving soundscape perception often exclude participants with hearing loss to prevent impaired perception from affecting experimental results. Participants are typically screened with pure tone audiometry, the "gold standard" for identifying and quantifying hearing loss at specific frequencies, and excluded if a study-dependent threshold is not met. However, procuring professional audiometric equipment for soundscape studies may be cost-ineffective, and manually performing audiometric tests is labour-intensive. Moreover, testing requirements for soundscape studies may not require sensitivities and specificities as high as that in a medical diagnosis setting. Hence, in this study, we investigate the effectiveness of the uHear app, an iOS application, as an affordable and automatic alternative to a conventional audiometer in screening participants for hearing loss for the purpose of soundscape studies or listening tests in general. Based on audiometric comparisons with the audiometer of 163 participants, the uHear app was found to have high precision (98.04%) when using the World Health Organization (WHO) grading scheme for assessing normal hearing. Precision is further improved (98.69%) when all frequencies assessed with the uHear app is considered in the grading, which lends further support to this cost-effective, automated alternative to screen for normal hearing.