 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Fusion Multimodal Network for SpeechWellness Detection
Aug 25, 2025Suicide is one of the leading causes of death among adolescents. Previous suicide risk prediction studies have primarily focused on either textual or acoustic information in isolation, the integration of multimodal signals, such as speech and text, offers a more comprehensive understanding of an individual's mental state. Motivated by this, and in the context of the 1st SpeechWellness detection challenge, we explore a lightweight multi-branch multimodal system based on a dynamic fusion mechanism for speechwellness detection. To address the limitation of prior approaches that rely on time-domain waveforms for acoustic analysis, our system incorporates both time-domain and time-frequency (TF) domain acoustic features, as well as semantic representations. In addition, we introduce a dynamic fusion block to adaptively integrate information from different modalities. Specifically, it applies learnable weights to each modality during the fusion process, enabling the model to adjust the contribution of each modality. To enhance computational efficiency, we design a lightweight structure by simplifying the original baseline model. Experimental results demonstrate that the proposed system exhibits superior performance compared to the challenge baseline, achieving a 78% reduction in model parameters and a 5% improvement in accuracy.
Noise-Robust Sound Event Detection and Counting via Language-Queried Sound Separation
Aug 10, 2025Most sound event detection (SED) systems perform well on clean datasets but degrade significantly in noisy environments. Language-queried audio source separation (LASS) models show promise for robust SED by separating target events; existing methods require elaborate multi-stage training and lack explicit guidance for target events. To address these challenges, we introduce event appearance detection (EAD), a counting-based approach that counts event occurrences at both the clip and frame levels. Based on EAD, we propose a co-training-based multi-task learning framework for EAD and SED to enhance SED's performance in noisy environments. First, SED struggles to learn the same patterns as EAD. Then, a task-based constraint is designed to improve prediction consistency between SED and EAD. This framework provides more reliable clip-level predictions for LASS models and strengthens timestamp detection capability. Experiments on DESED and WildDESED datasets demonstrate better performance compared to existing methods, with advantages becoming more pronounced at higher noise levels.
SpeakerLM: End-to-End Versatile Speaker Diarization and Recognition with Multimodal Large Language Models
Aug 08, 2025The Speaker Diarization and Recognition (SDR) task aims to predict "who spoke when and what" within an audio clip, which is a crucial task in various real-world multi-speaker scenarios such as meeting transcription and dialogue systems. Existing SDR systems typically adopt a cascaded framework, combining multiple modules such as speaker diarization (SD) and automatic speech recognition (ASR). The cascaded systems suffer from several limitations, such as error propagation, difficulty in handling overlapping speech, and lack of joint optimization for exploring the synergy between SD and ASR tasks. To address these limitations, we introduce SpeakerLM, a unified multimodal large language model for SDR that jointly performs SD and ASR in an end-to-end manner. Moreover, to facilitate diverse real-world scenarios, we incorporate a flexible speaker registration mechanism into SpeakerLM, enabling SDR under different speaker registration settings. SpeakerLM is progressively developed with a multi-stage training strategy on large-scale real data. Extensive experiments show that SpeakerLM demonstrates strong data scaling capability and generalizability, outperforming state-of-the-art cascaded baselines on both in-domain and out-of-domain public SDR benchmarks. Furthermore, experimental results show that the proposed speaker registration mechanism effectively ensures robust SDR performance of SpeakerLM across diverse speaker registration conditions and varying numbers of registered speakers.
EnvSDD: Benchmarking Environmental Sound Deepfake Detection
May 25, 2025Audio generation systems now create very realistic soundscapes that can enhance media production, but also pose potential risks. Several studies have examined deepfakes in speech or singing voice. However, environmental sounds have different characteristics, which may make methods for detecting speech and singing deepfakes less effective for real-world sounds. In addition, existing datasets for environmental sound deepfake detection are limited in scale and audio types. To address this gap, we introduce EnvSDD, the first large-scale curated dataset designed for this task, consisting of 45.25 hours of real and 316.74 hours of fake audio. The test set includes diverse conditions to evaluate the generalizability, such as unseen generation models and unseen datasets. We also propose an audio deepfake detection system, based on a pre-trained audio foundation model. Results on EnvSDD show that our proposed system outperforms the state-of-the-art systems from speech and singing domains.
Pushing the Frontiers of Self-Distillation Prototypes Network with Dimension Regularization and Score Normalization
May 20, 2025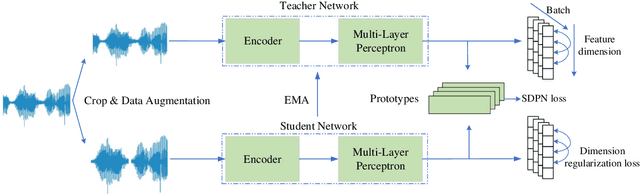
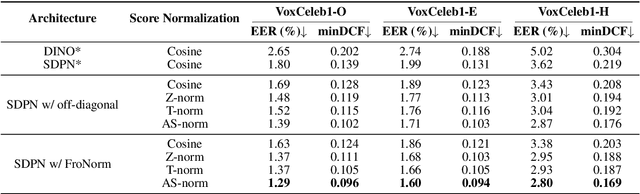

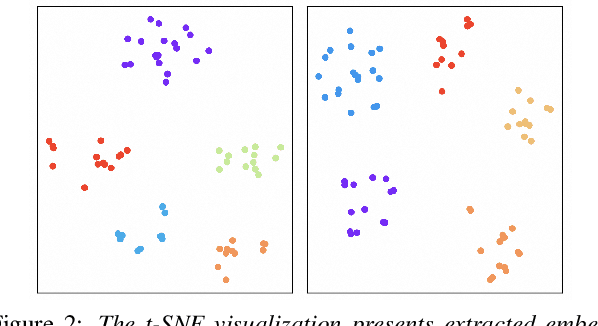
Developing robust speaker verification (SV) systems without speaker labels has been a longstanding challenge. Earlier research has highlighted a considerable performance gap between self-supervised and fully supervised approaches. In this paper, we enhance the non-contrastive self-supervised framework, Self-Distillation Prototypes Network (SDPN), by introducing dimension regularization that explicitly addresses the collapse problem through the application of regularization terms to speaker embeddings. Moreover, we integrate score normalization techniques from fully supervised SV to further bridge the gap toward supervised verification performance. SDPN with dimension regularization and score normalization sets a new state-of-the-art on the VoxCeleb1 speaker verification evaluation benchmark, achieving Equal Error Rate 1.29%, 1.60%, and 2.80% for trial VoxCeleb1-{O,E,H} respectively. These results demonstrate relative improvements of 28.3%, 19.6%, and 22.6% over the current best self-supervised methods, thereby advancing the frontiers of SV technology.
Leveraging LLM and Text-Queried Separation for Noise-Robust Sound Event Detection
Nov 02, 2024Sound Event Detection (SED) is challenging in noisy environments where overlapping sounds obscure target events. Language-queried audio source separation (LASS) aims to isolate the target sound events from a noisy clip. However, this approach can fail when the exact target sound is unknown, particularly in noisy test sets, leading to reduced performance. To address this issue, we leverage the capabilities of large language models (LLMs) to analyze and summarize acoustic data. By using LLMs to identify and select specific noise types, we implement a noise augmentation method for noise-robust fine-tuning. The fine-tuned model is applied to predict clip-wise event predictions as text queries for the LASS model. Our studies demonstrate that the proposed method improves SED performance in noisy environments. This work represents an early application of LLMs in noise-robust SED and suggests a promising direction for handling overlapping events in SED. Codes and pretrained models are available at https://github.com/apple-yinhan/Noise-robust-SED.
Multimodal Clickbait Detection by De-confounding Biases Using Causal Representation Inference
Oct 10, 2024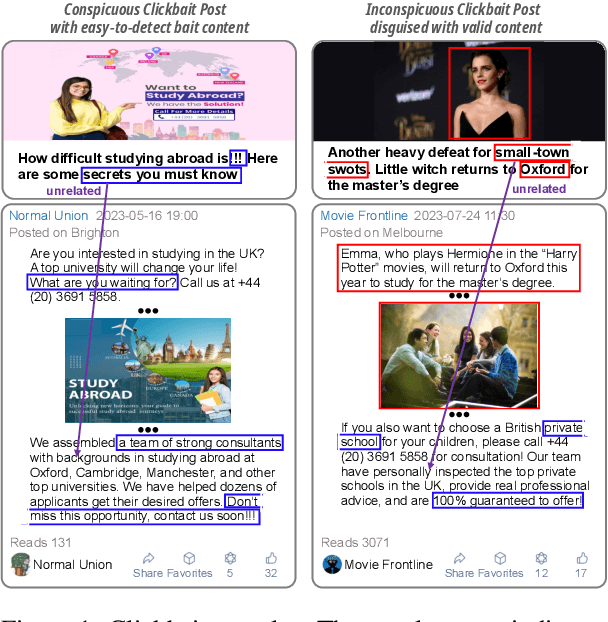
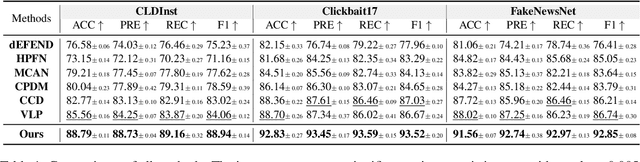
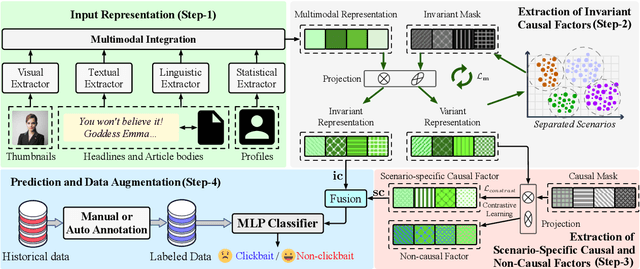

This paper focuses on detecting clickbait posts on the Web. These posts often use eye-catching disinformation in mixed modalities to mislead users to click for profit. That affects the user experience and thus would be blocked by content provider. To escape detection, malicious creators use tricks to add some irrelevant non-bait content into bait posts, dressing them up as legal to fool the detector. This content often has biased relations with non-bait labels, yet traditional detectors tend to make predictions based on simple co-occurrence rather than grasping inherent factors that lead to malicious behavior. This spurious bias would easily cause misjudgments. To address this problem, we propose a new debiased method based on causal inference. We first employ a set of features in multiple modalities to characterize the posts. Considering these features are often mixed up with unknown biases, we then disentangle three kinds of latent factors from them, including the invariant factor that indicates intrinsic bait intention; the causal factor which reflects deceptive patterns in a certain scenario, and non-causal noise. By eliminating the noise that causes bias, we can use invariant and causal factors to build a robust model with good generalization ability. Experiments on three popular datasets show the effectiveness of our approach.
Mixstyle based Domain Generalization for Sound Event Detection with Heterogeneous Training Data
Jul 04, 2024This work explores domain generalization (DG) for sound event detection (SED), advancing adaptability towards real-world scenarios. Our approach employs a mean-teacher framework with domain generalization to integrate heterogeneous training data, while preserving the SED model performance across the datasets. Specifically, we first apply mixstyle to the frequency dimension to adapt the mel-spectrograms from different domains. Next, we use the adaptive residual normalization method to generalize features across multiple domains by applying instance normalization in the frequency dimension. Lastly, we use the sound event bounding boxes method for post-processing. Our approach integrates features from bidirectional encoder representations from audio transformers and a convolutional recurrent neural network. We evaluate the proposed approach on DCASE 2024 Challenge Task 4 dataset, measuring polyphonic SED score (PSDS) on the DESED dataset and macro-average pAUC on the MAESTRO dataset. The results indicate that the proposed DG-based method improves both PSDS and macro-average pAUC compared to the challenge baseline.
FMSG-JLESS Submission for DCASE 2024 Task4 on Sound Event Detection with Heterogeneous Training Dataset and Potentially Missing Labels
Jun 29, 2024

This report presents the systems developed and submitted by Fortemedia Singapore (FMSG) and Joint Laboratory of Environmental Sound Sensing (JLESS) for DCASE 2024 Task 4. The task focuses on recognizing event classes and their time boundaries, given that multiple events can be present and may overlap in an audio recording. The novelty this year is a dataset with two sources, making it challenging to achieve good performance without knowing the source of the audio clips during evaluation. To address this, we propose a sound event detection method using domain generalization. Our approach integrates features from bidirectional encoder representations from audio transformers and a convolutional recurrent neural network. We focus on three main strategies to improve our method. First, we apply mixstyle to the frequency dimension to adapt the mel-spectrograms from different domains. Second, we consider training loss of our model specific to each datasets for their corresponding classes. This independent learning framework helps the model extract domain-specific features effectively. Lastly, we use the sound event bounding boxes method for post-processing. Our proposed method shows superior macro-average pAUC and polyphonic SED score performance on the DCASE 2024 Challenge Task 4 validation dataset and public evaluation dataset.
Description on IEEE ICME 2024 Grand Challenge: Semi-supervised Acoustic Scene Classification under Domain Shift
Feb 05, 2024
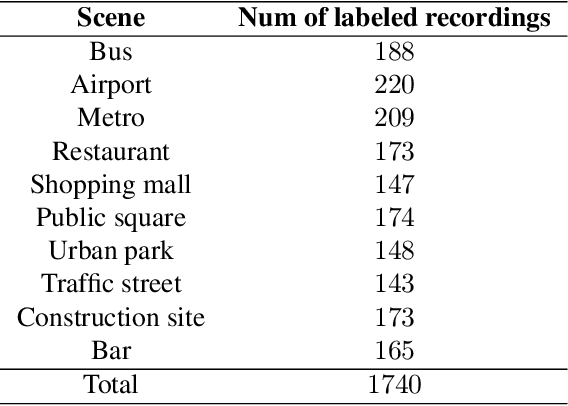

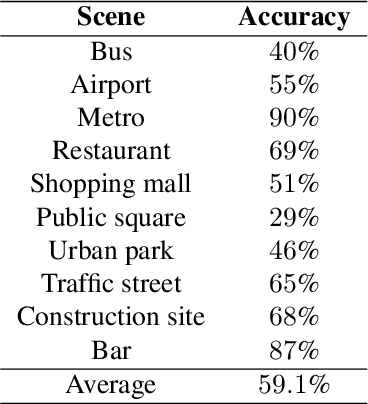
Acoustic scene classification (ASC) is a crucial research problem in computational auditory scene analysis, and it aims to recognize the unique acoustic characteristics of an environment. One of the challenges of the ASC task is domain shift caused by a distribution gap between training and testing data. Since 2018, ASC challenges have focused on the generalization of ASC models across different recording devices. Although this task in recent years has achieved substantial progress in device generalization, the challenge of domain shift between different regions, involving characteristics such as time, space, culture, and language, remains insufficiently explored at present. In addition, considering the abundance of unlabeled acoustic scene data in the real world, it is important to study the possible ways to utilize these unlabelled data. Therefore, we introduce the task Semi-supervised Acoustic Scene Classification under Domain Shift in the ICME 2024 Grand Challenge. We encourage participants to innovate with semi-supervised learning techniques, aiming to develop more robust ASC models under domain shift.