 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Driver's Perceived Risk: a Model Based on Semi-Supervised Learning Strategy
Apr 17, 2025Drivers' perception of risk determines their acceptance, trust, and use of the Automated Driving Systems (ADSs). However, perceived risk is subjective and difficult to evaluate using existing methods. To address this issue, a driver's subjective perceived risk (DSPR) model is proposed, regarding perceived risk as a dynamically triggered mechanism with anisotropy and attenuation. 20 participants are recruited for a driver-in-the-loop experiment to report their real-time subjective risk ratings (SRRs) when experiencing various automatic driving scenarios. A convolutional neural network and bidirectional long short-term memory network with temporal pattern attention (CNN-Bi-LSTM-TPA) is embedded into a semi-supervised learning strategy to predict SRRs, aiming to reduce data noise caused by subjective randomness of participants. The results illustrate that DSPR achieves the highest prediction accuracy of 87.91% in predicting SRRs, compared to three state-of-the-art risk models. The semi-supervised strategy improves accuracy by 20.12%. Besides, CNN-Bi-LSTM-TPA network presents the highest accuracy among four different LSTM structures. This study offers an effective method for assessing driver's perceived risk, providing support for the safety enhancement of ADS and driver's trust improvement.
Description on IEEE ICME 2024 Grand Challenge: Semi-supervised Acoustic Scene Classification under Domain Shift
Feb 05, 2024
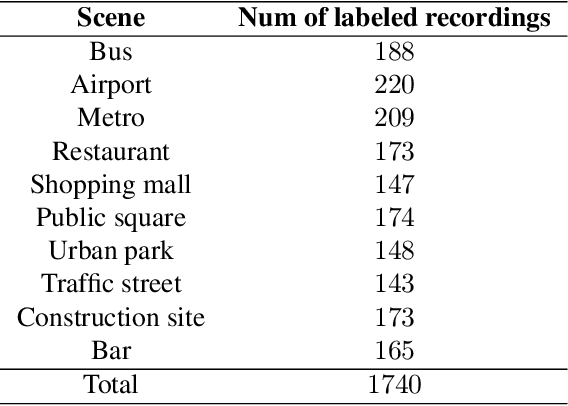

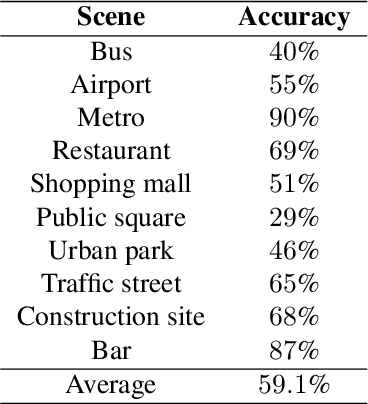
Acoustic scene classification (ASC) is a crucial research problem in computational auditory scene analysis, and it aims to recognize the unique acoustic characteristics of an environment. One of the challenges of the ASC task is domain shift caused by a distribution gap between training and testing data. Since 2018, ASC challenges have focused on the generalization of ASC models across different recording devices. Although this task in recent years has achieved substantial progress in device generalization, the challenge of domain shift between different regions, involving characteristics such as time, space, culture, and language, remains insufficiently explored at present. In addition, considering the abundance of unlabeled acoustic scene data in the real world, it is important to study the possible ways to utilize these unlabelled data. Therefore, we introduce the task Semi-supervised Acoustic Scene Classification under Domain Shift in the ICME 2024 Grand Challenge. We encourage participants to innovate with semi-supervised learning techniques, aiming to develop more robust ASC models under domain shift.
Dynamic Kernel Convolution Network with Scene-dedicate Training for Sound Event Localization and Detection
Jul 17, 2023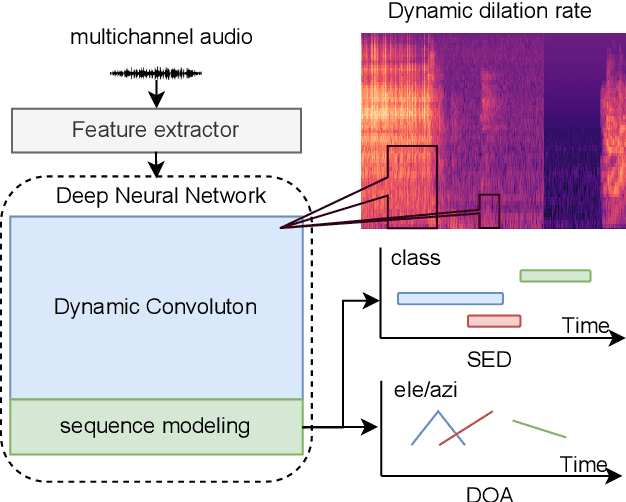
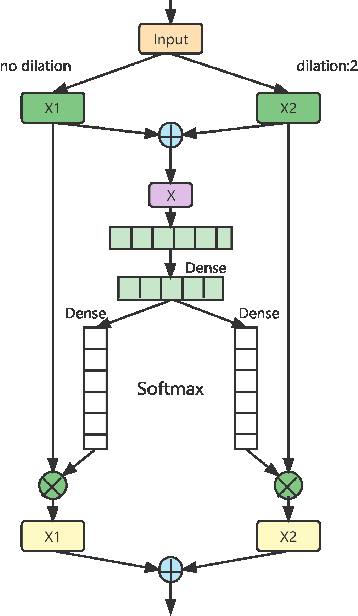
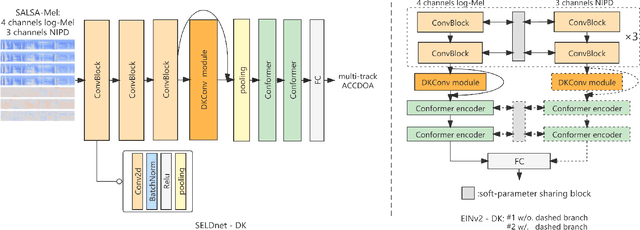
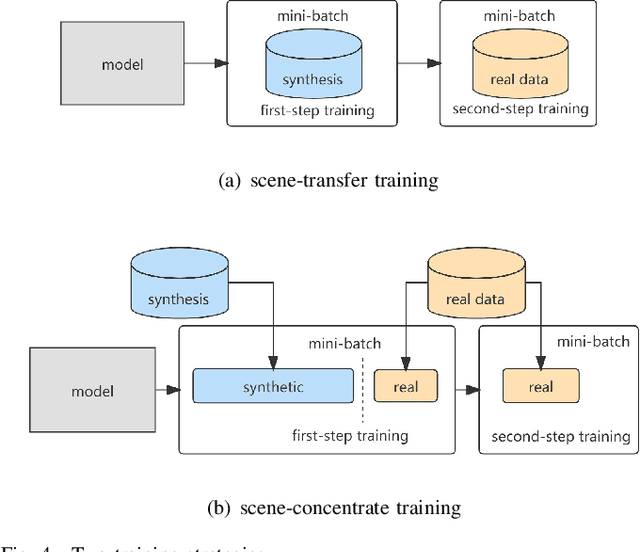
DNN-based methods have shown high performance in sound event localization and detection(SELD). While in real spatial sound scenes, reverberation and the imbalanced presence of various sound events increase the complexity of the SELD task. In this paper, we propose an effective SELD system in real spatial scenes.In our approach, a dynamic kernel convolution module is introduced after the convolution blocks to adaptively model the channel-wise features with different receptive fields. Secondly, we incorporate the SELDnet and EINv2 framework into the proposed SELD system with multi-track ACCDOA. Moreover, two scene-dedicated strategies are introduced into the training stage to improve the generalization of the system in realistic spatial sound scenes. Finally, we apply data augmentation methods to extend the dataset using channel rotation, spatial data synthesis. Four joint metrics are used to evaluate the performance of the SELD system on the Sony-TAu Realistic Spatial Soundscapes 2022 dataset.Experimental results show that the proposed systems outperform the fixed-kernel convolution SELD systems. In addition, the proposed system achieved an SELD score of 0.348 in the DCASE SELD task and surpassed the SOTA methods.
Two-stage Autoencoder Neural Network for 3D Speech Enhancement
Jun 08, 20233D speech enhancement has attracted much attention in recent years with the development of augmented reality technology. Traditional denoising convolutional autoencoders have limitations in extracting dynamic voice information. In this paper, we propose a two-stage autoencoder neural network for 3D speech enhancement. We incorporate a dual-path recurrent neural network block into the convolutional autoencoder to iteratively apply time-domain and frequency-domain modeling in an alternate fashion. And an attention mechanism for fusing the high-dimension features is proposed. We also introduce a loss function to simultaneously optimize the network in the time-frequency and time domains. Experimental results show that our system outperforms the state-of-the-art systems on the dataset of ICASSP L3DAS23 challenge.