 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Fusion Multimodal Network for SpeechWellness Detection
Aug 25, 2025Suicide is one of the leading causes of death among adolescents. Previous suicide risk prediction studies have primarily focused on either textual or acoustic information in isolation, the integration of multimodal signals, such as speech and text, offers a more comprehensive understanding of an individual's mental state. Motivated by this, and in the context of the 1st SpeechWellness detection challenge, we explore a lightweight multi-branch multimodal system based on a dynamic fusion mechanism for speechwellness detection. To address the limitation of prior approaches that rely on time-domain waveforms for acoustic analysis, our system incorporates both time-domain and time-frequency (TF) domain acoustic features, as well as semantic representations. In addition, we introduce a dynamic fusion block to adaptively integrate information from different modalities. Specifically, it applies learnable weights to each modality during the fusion process, enabling the model to adjust the contribution of each modality. To enhance computational efficiency, we design a lightweight structure by simplifying the original baseline model. Experimental results demonstrate that the proposed system exhibits superior performance compared to the challenge baseline, achieving a 78% reduction in model parameters and a 5% improvement in accuracy.
AudioSetCaps: An Enriched Audio-Caption Dataset using Automated Generation Pipeline with Large Audio and Language Models
Nov 28, 2024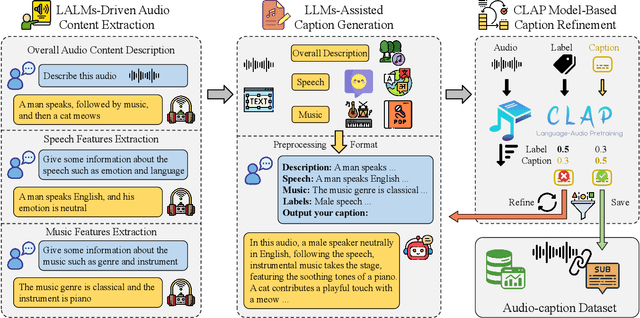
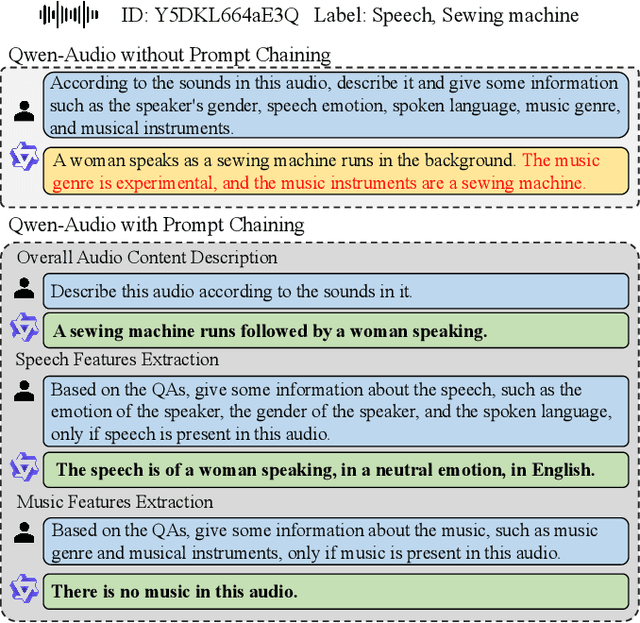
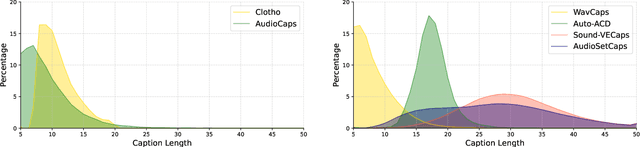

With the emergence of audio-language models, constructing large-scale paired audio-language datasets has become essential yet challenging for model development, primarily due to the time-intensive and labour-heavy demands involved. While large language models (LLMs) have improved the efficiency of synthetic audio caption generation, current approaches struggle to effectively extract and incorporate detailed audio information. In this paper, we propose an automated pipeline that integrates audio-language models for fine-grained content extraction, LLMs for synthetic caption generation, and a contrastive language-audio pretraining (CLAP) model-based refinement process to improve the quality of captions. Specifically, we employ prompt chaining techniques in the content extraction stage to obtain accurate and fine-grained audio information, while we use the refinement process to mitigate potential hallucinations in the generated captions. Leveraging the AudioSet dataset and the proposed approach, we create AudioSetCaps, a dataset comprising 1.9 million audio-caption pairs, the largest audio-caption dataset at the time of writing. The models trained with AudioSetCaps achieve state-of-the-art performance on audio-text retrieval with R@1 scores of 46.3% for text-to-audio and 59.7% for audio-to-text retrieval and automated audio captioning with the CIDEr score of 84.8. As our approach has shown promising results with AudioSetCaps, we create another dataset containing 4.1 million synthetic audio-language pairs based on the Youtube-8M and VGGSound datasets. To facilitate research in audio-language learning, we have made our pipeline, datasets with 6 million audio-language pairs, and pre-trained models publicly available at https://github.com/JishengBai/AudioSetCaps.
Sound event localization and classification using WASN in Outdoor Environment
Mar 29, 2024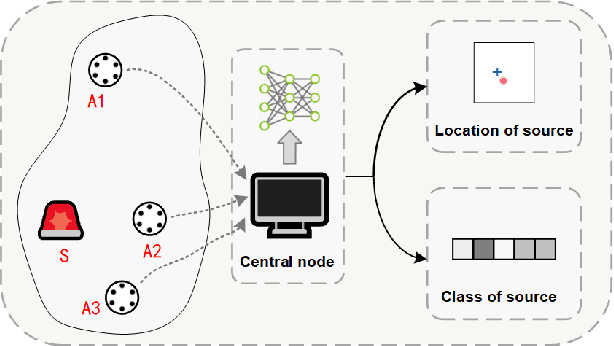
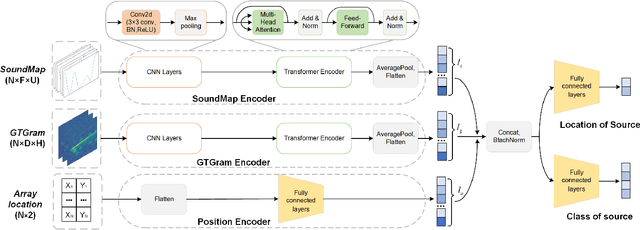
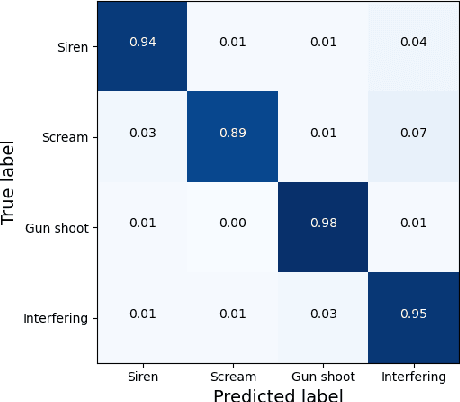
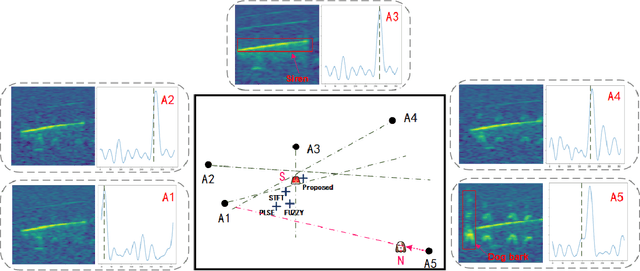
Deep learning-based sound event localization and classification is an emerging research area within wireless acoustic sensor networks. However, current methods for sound event localization and classification typically rely on a single microphone array, making them susceptible to signal attenuation and environmental noise, which limits their monitoring range. Moreover, methods using multiple microphone arrays often focus solely on source localization, neglecting the aspect of sound event classification. In this paper, we propose a deep learning-based method that employs multiple features and attention mechanisms to estimate the location and class of sound source. We introduce a Soundmap feature to capture spatial information across multiple frequency bands. We also use the Gammatone filter to generate acoustic features more suitable for outdoor environments. Furthermore, we integrate attention mechanisms to learn channel-wise relationships and temporal dependencies within the acoustic features. To evaluate our proposed method, we conduct experiments using simulated datasets with different levels of noise and size of monitoring areas, as well as different arrays and source positions. The experimental results demonstrate the superiority of our proposed method over state-of-the-art methods in both sound event classification and sound source localization tasks. And we provide further analysis to explain the reasons for the observed errors.
Description on IEEE ICME 2024 Grand Challenge: Semi-supervised Acoustic Scene Classification under Domain Shift
Feb 05, 2024
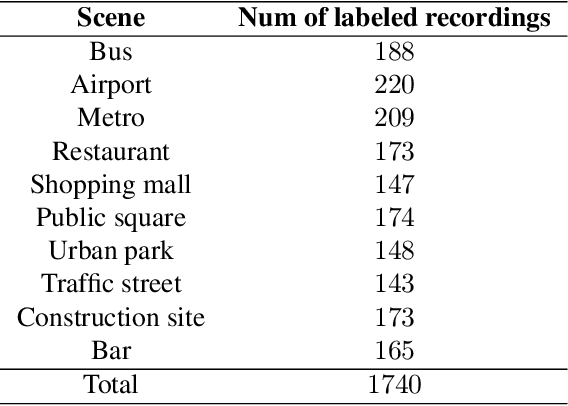

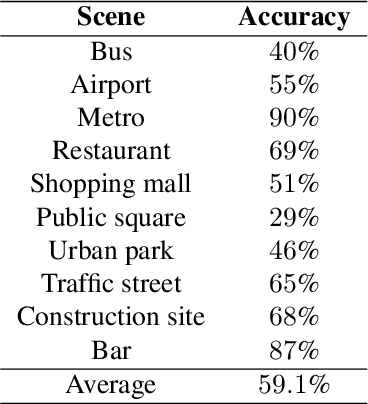
Acoustic scene classification (ASC) is a crucial research problem in computational auditory scene analysis, and it aims to recognize the unique acoustic characteristics of an environment. One of the challenges of the ASC task is domain shift caused by a distribution gap between training and testing data. Since 2018, ASC challenges have focused on the generalization of ASC models across different recording devices. Although this task in recent years has achieved substantial progress in device generalization, the challenge of domain shift between different regions, involving characteristics such as time, space, culture, and language, remains insufficiently explored at present. In addition, considering the abundance of unlabeled acoustic scene data in the real world, it is important to study the possible ways to utilize these unlabelled data. Therefore, we introduce the task Semi-supervised Acoustic Scene Classification under Domain Shift in the ICME 2024 Grand Challenge. We encourage participants to innovate with semi-supervised learning techniques, aiming to develop more robust ASC models under domain shift.
Sub-band and Full-band Interactive U-Net with DPRNN for Demixing Cross-talk Stereo Music
Jan 11, 2024


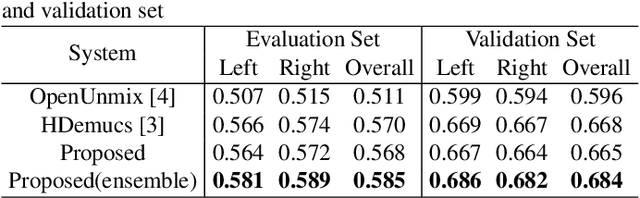
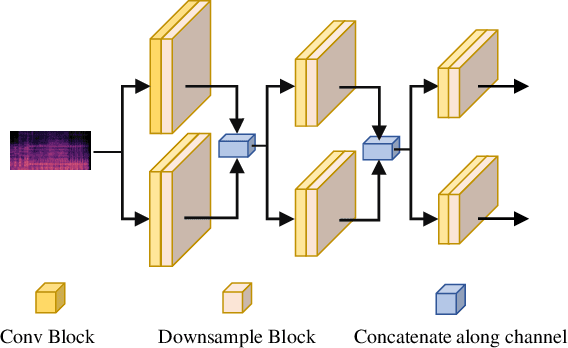
This paper presents a detailed description of our proposed methods for the ICASSP 2024 Cadenza Challenge. Experimental results show that the proposed system can achieve better performance than official baselines.
Interactive Dual-Conformer with Scene-Inspired Mask for Soft Sound Event Detection
Dec 07, 2023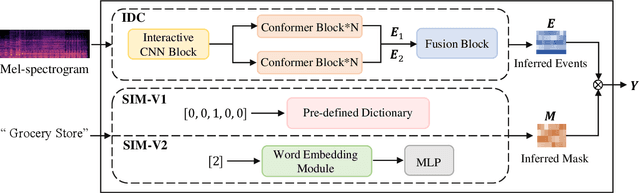
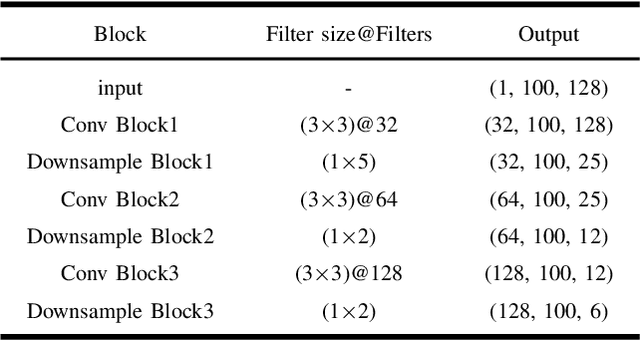
Traditional binary hard labels for sound event detection (SED) lack details about the complexity and variability of sound event distributions. Recently, a novel annotation workflow is proposed to generate fine-grained non-binary soft labels, resulting in a new real-life dataset named MAESTRO Real for SED. In this paper, we first propose an interactive dual-conformer (IDC) module, in which a cross-interaction mechanism is applied to effectively exploit the information from soft labels. In addition, a novel scene-inspired mask (SIM) based on soft labels is incorporated for more precise SED predictions. The SIM is initially generated through a statistical approach, referred as SIM-V1. However, the fixed artificial mask may mismatch the SED model, resulting in limited effectiveness. Therefore, we further propose SIM-V2, which employs a word embedding model for adaptive SIM estimation. Experimental results show that the proposed IDC module can effectively utilize the information from soft labels, and the integration of SIM-V1 can further improve the accuracy. In addition, the impact of different word embedding dimensions on SIM-V2 is explored, and the results show that the appropriate dimension can enable SIM-V2 achieve superior performance than SIM-V1. In DCASE 2023 Challenge Task4B, the proposed system achieved the top ranking performance on the evaluation dataset of MAESTRO Real.
AudioLog: LLMs-Powered Long Audio Logging with Acoustic Scenes and Events Joint Estimation
Nov 21, 2023Previous studies in automated audio captioning have faced difficulties in accurately capturing the complete temporal details of acoustic scenes and events within long audio sequences. This paper presents AudioLog, a large language models (LLMs)-powered audio logging system with multi-task learning of acoustic tasks. Specifically, we propose a joint training network, achieved by fine-tuning a large audio model based on the pre-trained hierarchical token-semantic audio Transformer. We then leverage LLMs to craft audio logs that summarize textual descriptions of the acoustic environment. Experiments show that the proposed system attains exceptional performance in acoustic scene classification and sound event detection, surpassing existing methods in the field. Further analyses demonstrate AudioLog's power in effectively summarizing long audio sequences.
Dynamic Kernel Convolution Network with Scene-dedicate Training for Sound Event Localization and Detection
Jul 17, 2023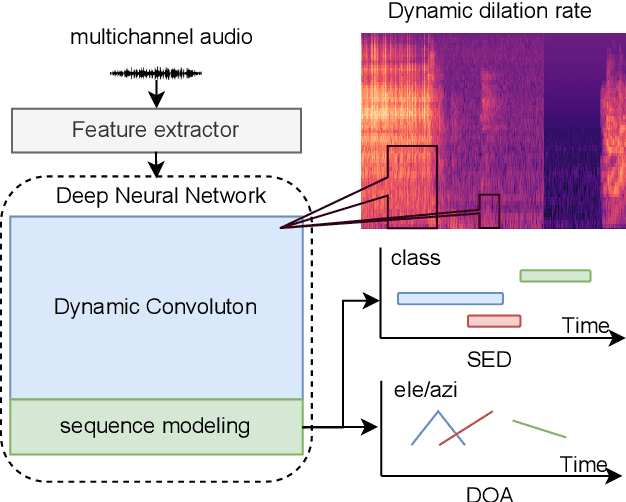
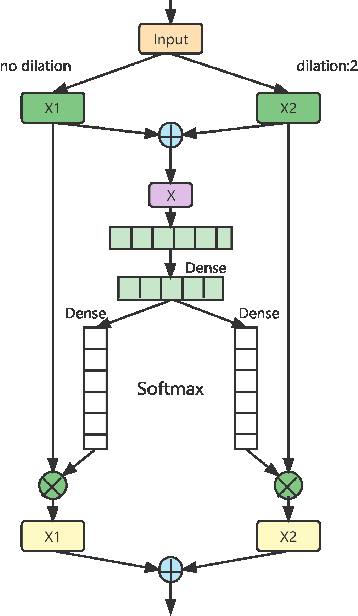
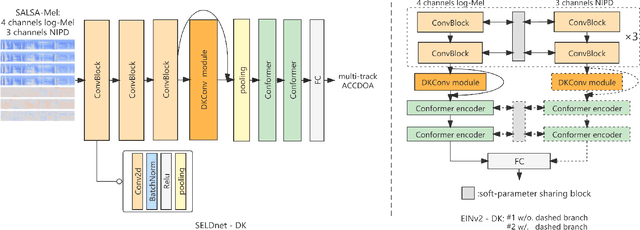
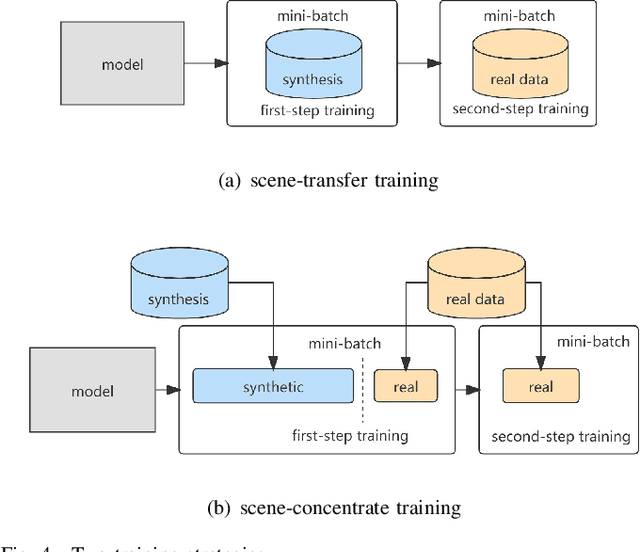
DNN-based methods have shown high performance in sound event localization and detection(SELD). While in real spatial sound scenes, reverberation and the imbalanced presence of various sound events increase the complexity of the SELD task. In this paper, we propose an effective SELD system in real spatial scenes.In our approach, a dynamic kernel convolution module is introduced after the convolution blocks to adaptively model the channel-wise features with different receptive fields. Secondly, we incorporate the SELDnet and EINv2 framework into the proposed SELD system with multi-track ACCDOA. Moreover, two scene-dedicated strategies are introduced into the training stage to improve the generalization of the system in realistic spatial sound scenes. Finally, we apply data augmentation methods to extend the dataset using channel rotation, spatial data synthesis. Four joint metrics are used to evaluate the performance of the SELD system on the Sony-TAu Realistic Spatial Soundscapes 2022 dataset.Experimental results show that the proposed systems outperform the fixed-kernel convolution SELD systems. In addition, the proposed system achieved an SELD score of 0.348 in the DCASE SELD task and surpassed the SOTA methods.
Two-stage Autoencoder Neural Network for 3D Speech Enhancement
Jun 08, 20233D speech enhancement has attracted much attention in recent years with the development of augmented reality technology. Traditional denoising convolutional autoencoders have limitations in extracting dynamic voice information. In this paper, we propose a two-stage autoencoder neural network for 3D speech enhancement. We incorporate a dual-path recurrent neural network block into the convolutional autoencoder to iteratively apply time-domain and frequency-domain modeling in an alternate fashion. And an attention mechanism for fusing the high-dimension features is proposed. We also introduce a loss function to simultaneously optimize the network in the time-frequency and time domains. Experimental results show that our system outperforms the state-of-the-art systems on the dataset of ICASSP L3DAS23 challenge.
SSDPT: Self-Supervised Dual-Path Transformer for Anomalous Sound Detection in Machine Condition Monitoring
Aug 06, 2022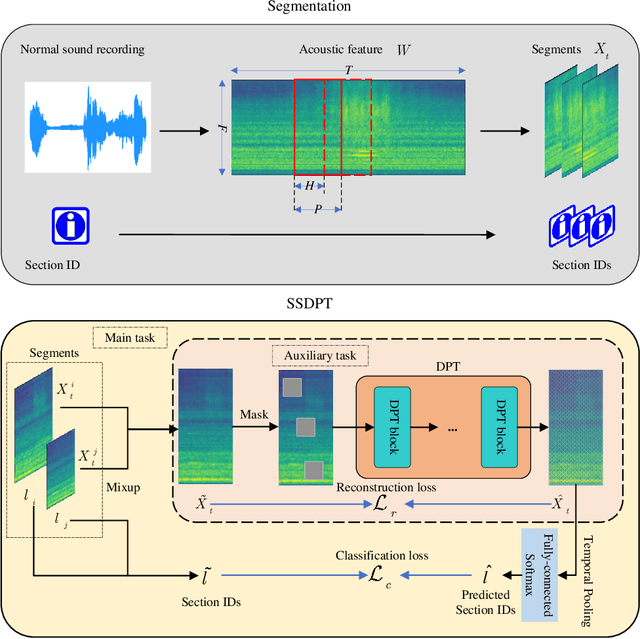
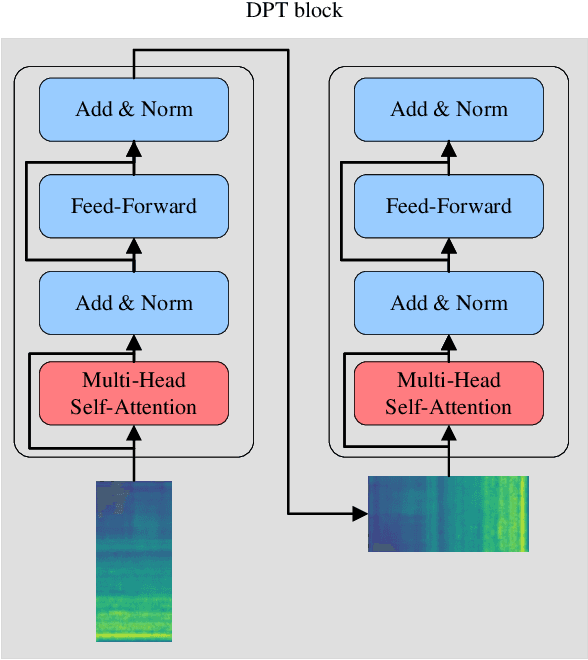

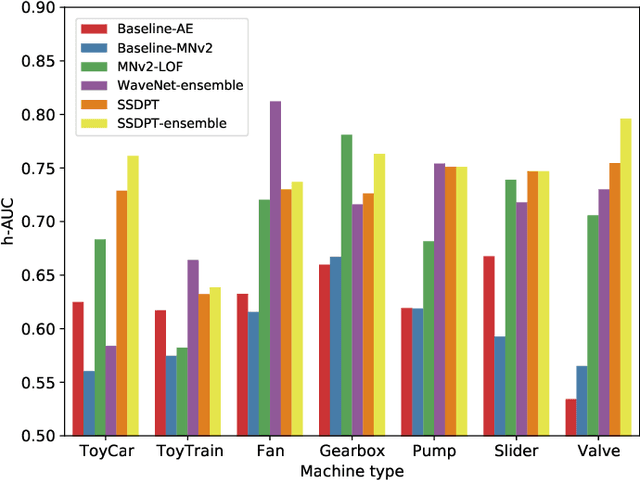
Anomalous sound detection for machine condition monitoring has great potential in the development of Industry 4.0. However, these anomalous sounds of machines are usually unavailable in normal conditions. Therefore, the models employed have to learn acoustic representations with normal sounds for training, and detect anomalous sounds while testing. In this article, we propose a self-supervised dual-path Transformer (SSDPT) network to detect anomalous sounds in machine monitoring. The SSDPT network splits the acoustic features into segments and employs several DPT blocks for time and frequency modeling. DPT blocks use attention modules to alternately model the interactive information about the frequency and temporal components of the segmented acoustic features. To address the problem of lack of anomalous sound, we adopt a self-supervised learning approach to train the network with normal sound. Specifically, this approach randomly masks and reconstructs the acoustic features, and jointly classifies machine identity information to improve the performance of anomalous sound detection. We evaluated our method on the DCASE2021 task2 dataset. The experimental results show that the SSDPT network achieves a significant increase in the harmonic mean AUC score, in comparison to present state-of-the-art methods of anomalous sound detection.