 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSDPT: Self-Supervised Dual-Path Transformer for Anomalous Sound Detection in Machine Condition Monitoring
Aug 06, 2022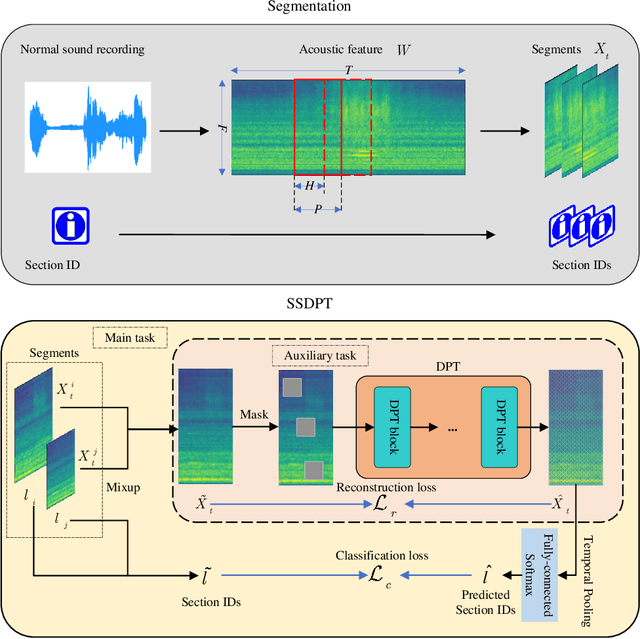
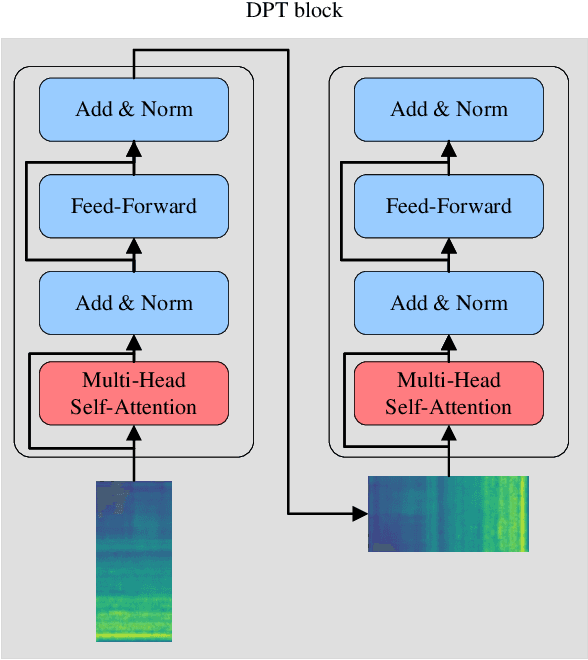

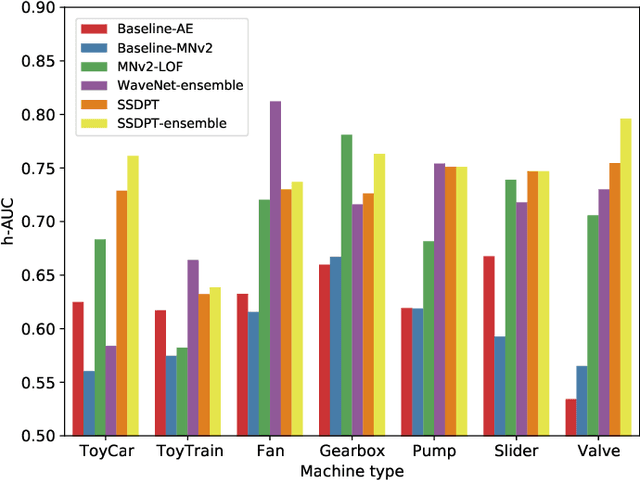
Anomalous sound detection for machine condition monitoring has great potential in the development of Industry 4.0. However, these anomalous sounds of machines are usually unavailable in normal conditions. Therefore, the models employed have to learn acoustic representations with normal sounds for training, and detect anomalous sounds while testing. In this article, we propose a self-supervised dual-path Transformer (SSDPT) network to detect anomalous sounds in machine monitoring. The SSDPT network splits the acoustic features into segments and employs several DPT blocks for time and frequency modeling. DPT blocks use attention modules to alternately model the interactive information about the frequency and temporal components of the segmented acoustic features. To address the problem of lack of anomalous sound, we adopt a self-supervised learning approach to train the network with normal sound. Specifically, this approach randomly masks and reconstructs the acoustic features, and jointly classifies machine identity information to improve the performance of anomalous sound detection. We evaluated our method on the DCASE2021 task2 dataset. The experimental results show that the SSDPT network achieves a significant increase in the harmonic mean AUC score, in comparison to present state-of-the-art methods of anomalous sound detection.
A Squeeze-and-Excitation and Transformer based Cross-task System for Environmental Sound Recognition
Mar 16, 2022



Environmental sound recognition (ESR) is an emerging research topic in audio pattern recognition. Many tasks are presented to resort to computational systems for ESR in real-life applications. However, current systems are usually designed for individual tasks, and are not robust and applicable to other tasks. Cross-task systems, which promote unified knowledge modeling across various tasks, have not been thoroughly investigated. In this paper, we propose a cross-task system for three different tasks of ESR: acoustic scene classification, urban sound tagging, and anomalous sound detection. An architecture named SE-Trans is presented that uses attention mechanism-based Squeeze-and-Excitation and Transformer encoder modules to learn channel-wise relationship and temporal dependencies of the acoustic features. FMix is employed as the data augmentation method that improves the performance of ESR. Evaluations for the three tasks are conducted on the recent databases of DCASE challenges. The experimental results show that the proposed cross-task system achieves state-of-the-art performance on all tasks. Further analysis demonstrates that the proposed cross-task system can effectively utilize acoustic knowledge across different ESR tasks.