 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Kernel Convolution Network with Scene-dedicate Training for Sound Event Localization and Detection
Paper and Code
Jul 17, 2023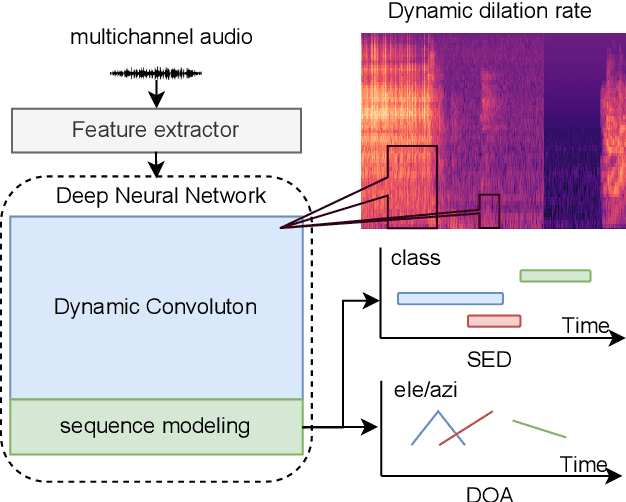
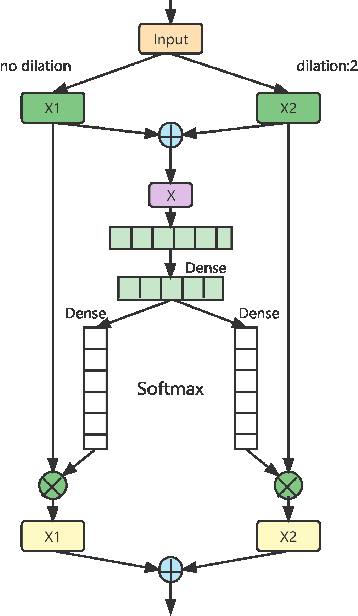
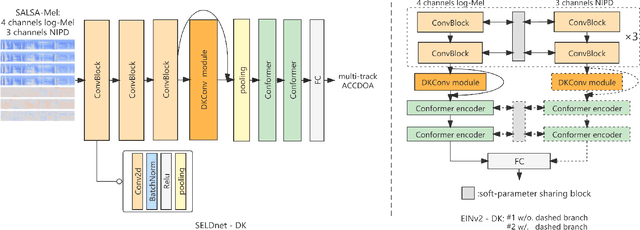
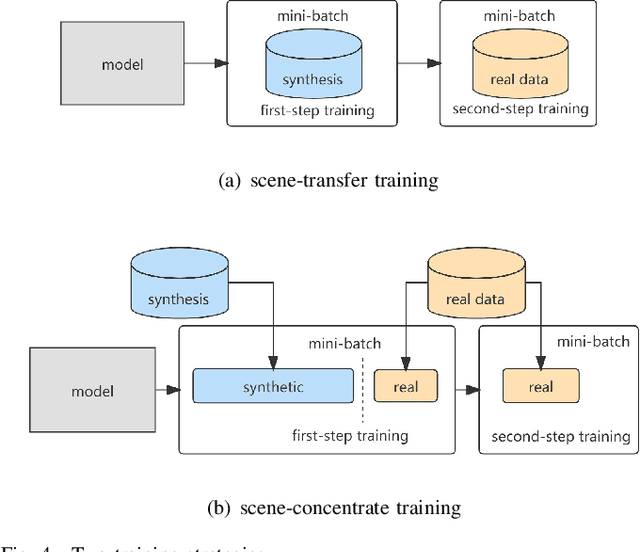
DNN-based methods have shown high performance in sound event localization and detection(SELD). While in real spatial sound scenes, reverberation and the imbalanced presence of various sound events increase the complexity of the SELD task. In this paper, we propose an effective SELD system in real spatial scenes.In our approach, a dynamic kernel convolution module is introduced after the convolution blocks to adaptively model the channel-wise features with different receptive fields. Secondly, we incorporate the SELDnet and EINv2 framework into the proposed SELD system with multi-track ACCDOA. Moreover, two scene-dedicated strategies are introduced into the training stage to improve the generalization of the system in realistic spatial sound scenes. Finally, we apply data augmentation methods to extend the dataset using channel rotation, spatial data synthesis. Four joint metrics are used to evaluate the performance of the SELD system on the Sony-TAu Realistic Spatial Soundscapes 2022 dataset.Experimental results show that the proposed systems outperform the fixed-kernel convolution SELD systems. In addition, the proposed system achieved an SELD score of 0.348 in the DCASE SELD task and surpassed the SOTA methods.