 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Clickbait Detection by De-confounding Biases Using Causal Representation Inference
Oct 10, 2024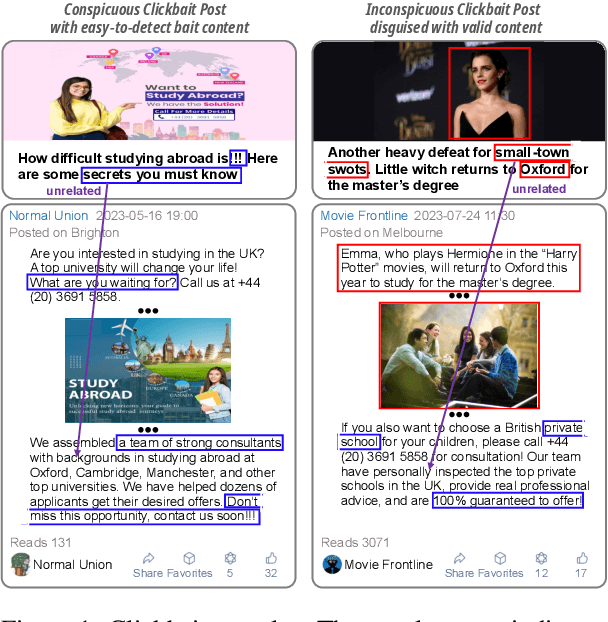
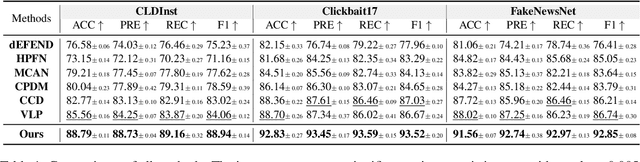
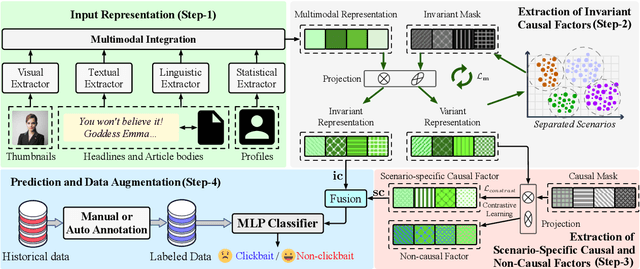

This paper focuses on detecting clickbait posts on the Web. These posts often use eye-catching disinformation in mixed modalities to mislead users to click for profit. That affects the user experience and thus would be blocked by content provider. To escape detection, malicious creators use tricks to add some irrelevant non-bait content into bait posts, dressing them up as legal to fool the detector. This content often has biased relations with non-bait labels, yet traditional detectors tend to make predictions based on simple co-occurrence rather than grasping inherent factors that lead to malicious behavior. This spurious bias would easily cause misjudgments. To address this problem, we propose a new debiased method based on causal inference. We first employ a set of features in multiple modalities to characterize the posts. Considering these features are often mixed up with unknown biases, we then disentangle three kinds of latent factors from them, including the invariant factor that indicates intrinsic bait intention; the causal factor which reflects deceptive patterns in a certain scenario, and non-causal noise. By eliminating the noise that causes bias, we can use invariant and causal factors to build a robust model with good generalization ability. Experiments on three popular datasets show the effectiveness of our approach.
Improve Transformer Pre-Training with Decoupled Directional Relative Position Encoding and Representation Differentiations
Oct 09, 2022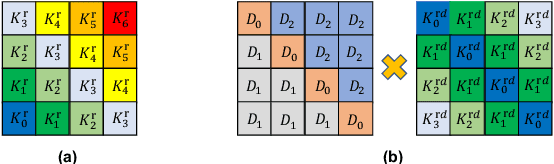
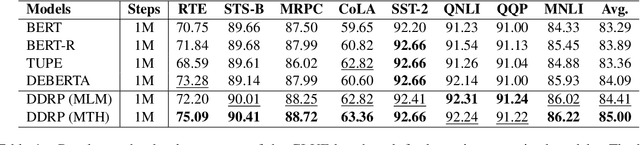
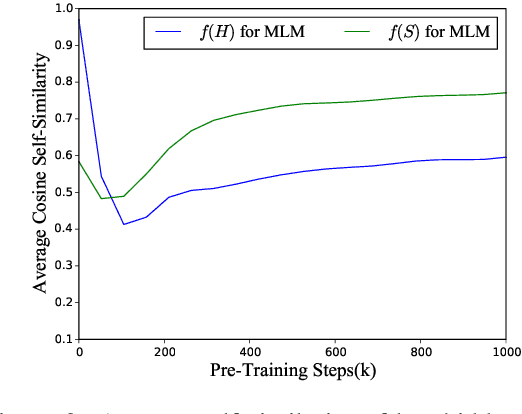
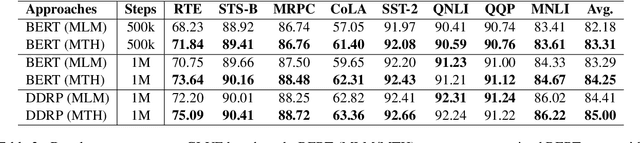
In this work, we revisit the Transformer-based pre-trained language models and identify two problems that may limit the expressiveness of the model. Firstly, existing relative position encoding models (e.g., T5 and DEBERTA) confuse two heterogeneous information: relative distance and direction. It may make the model unable to capture the associative semantics of the same direction or the same distance, which in turn affects the performance of downstream tasks. Secondly, we notice the pre-trained BERT with Mask Language Modeling (MLM) pre-training objective outputs similar token representations and attention weights of different heads, which may impose difficulties in capturing discriminative semantic representations. Motivated by the above investigation, we propose two novel techniques to improve pre-trained language models: Decoupled Directional Relative Position (DDRP) encoding and MTH pre-training objective. DDRP decouples the relative distance features and the directional features in classical relative position encoding for better position information understanding. MTH designs two novel auxiliary losses besides MLM to enlarge the dissimilarities between (a) last hidden states of different tokens, and (b) attention weights of different heads, alleviating homogenization and anisotropic problem in representation learning for better optimization. Extensive experiments and ablation studies on GLUE benchmark demonstrate the effectiveness of our proposed methods.