 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprove Transformer Pre-Training with Decoupled Directional Relative Position Encoding and Representation Differentiations
Paper and Code
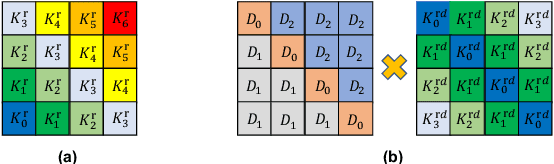
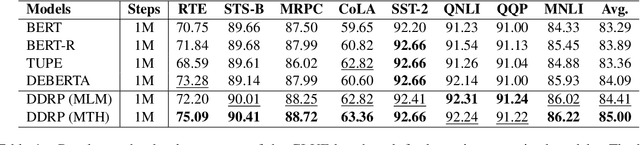
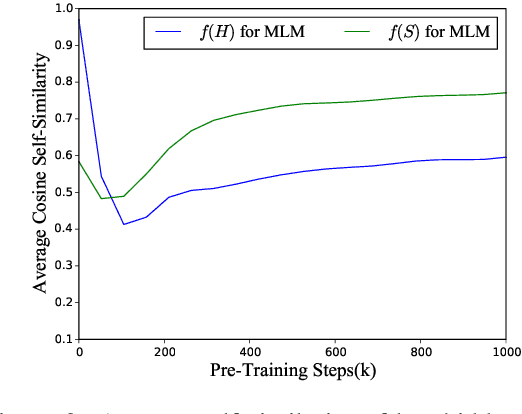
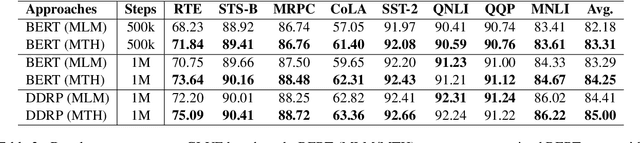
In this work, we revisit the Transformer-based pre-trained language models and identify two problems that may limit the expressiveness of the model. Firstly, existing relative position encoding models (e.g., T5 and DEBERTA) confuse two heterogeneous information: relative distance and direction. It may make the model unable to capture the associative semantics of the same direction or the same distance, which in turn affects the performance of downstream tasks. Secondly, we notice the pre-trained BERT with Mask Language Modeling (MLM) pre-training objective outputs similar token representations and attention weights of different heads, which may impose difficulties in capturing discriminative semantic representations. Motivated by the above investigation, we propose two novel techniques to improve pre-trained language models: Decoupled Directional Relative Position (DDRP) encoding and MTH pre-training objective. DDRP decouples the relative distance features and the directional features in classical relative position encoding for better position information understanding. MTH designs two novel auxiliary losses besides MLM to enlarge the dissimilarities between (a) last hidden states of different tokens, and (b) attention weights of different heads, alleviating homogenization and anisotropic problem in representation learning for better optimization. Extensive experiments and ablation studies on GLUE benchmark demonstrate the effectiveness of our proposed methods.