 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Normalization-Free Fully Integer Quantized Neural Networks via Progressive Tandem Learning
Dec 18, 2025Quantised neural networks (QNNs) shrink models and reduce inference energy through low-bit arithmetic, yet most still depend on a running statistics batch normalisation (BN) layer, preventing true integer-only deployment. Prior attempts remove BN by parameter folding or tailored initialisation; while helpful, they rarely recover BN's stability and accuracy and often impose bespoke constraints. We present a BN-free, fully integer QNN trained via a progressive, layer-wise distillation scheme that slots into existing low-bit pipelines. Starting from a pretrained BN-enabled teacher, we use layer-wise targets and progressive compensation to train a student that performs inference exclusively with integer arithmetic and contains no BN operations. On ImageNet with AlexNet, the BN-free model attains competitive Top-1 accuracy under aggressive quantisation. The procedure integrates directly with standard quantisation workflows, enabling end-to-end integer-only inference for resource-constrained settings such as edge and embedded devices.
A Reservoir-based Model for Human-like Perception of Complex Rhythm Pattern
Mar 16, 2025Rhythm is a fundamental aspect of human behaviour, present from infancy and deeply embedded in cultural practices. Rhythm anticipation is a spontaneous cognitive process that typically occurs before the onset of actual beats. While most research in both neuroscience and artificial intelligence has focused on metronome-based rhythm tasks, studies investigating the perception of complex musical rhythm patterns remain limited. To address this gap, we propose a hierarchical oscillator-based model to better understand the perception of complex musical rhythms in biological systems. The model consists of two types of coupled neurons that generate oscillations, with different layers tuned to respond to distinct perception levels. We evaluate the model using several representative rhythm patterns spanning the upper, middle, and lower bounds of human musical perception. Our findings demonstrate that, while maintaining a high degree of synchronization accuracy, the model exhibits human-like rhythmic behaviours. Additionally, the beta band neuronal activity in the model mirrors patterns observed in the human brain, further validating the biological plausibility of the approach.
A General Close-loop Predictive Coding Framework for Auditory Working Memory
Mar 16, 2025



Auditory working memory is essential for various daily activities, such as language acquisition, conversation. It involves the temporary storage and manipulation of information that is no longer present in the environment. While extensively studied in neuroscience and cognitive science, research on its modeling within neural networks remains limited. To address this gap, we propose a general framework based on a close-loop predictive coding paradigm to perform short auditory signal memory tasks. The framework is evaluated on two widely used benchmark datasets for environmental sound and speech, demonstrating high semantic similarity across both datasets.
Exploring Differences between Human Perception and Model Inference in Audio Event Recognition
Sep 10, 2024



Audio Event Recognition (AER) traditionally focuses on detecting and identifying audio events. Most existing AER models tend to detect all potential events without considering their varying significance across different contexts. This makes the AER results detected by existing models often have a large discrepancy with human auditory perception. Although this is a critical and significant issue, it has not been extensively studied by the Detection and Classification of Sound Scenes and Events (DCASE) community because solving it is time-consuming and labour-intensive. To address this issue, this paper introduces the concept of semantic importance in AER, focusing on exploring the differences between human perception and model inference. This paper constructs a Multi-Annotated Foreground Audio Event Recognition (MAFAR) dataset, which comprises audio recordings labelled by 10 professional annotators. Through labelling frequency and variance, the MAFAR dataset facilitates the quantification of semantic importance and analysis of human perception. By comparing human annotations with the predictions of ensemble pre-trained models, this paper uncovers a significant gap between human perception and model inference in both semantic identification and existence detection of audio events. Experimental results reveal that human perception tends to ignore subtle or trivial events in the event semantic identification, while model inference is easily affected by events with noises. Meanwhile, in event existence detection, models are usually more sensitive than humans.
Soundscape Captioning using Sound Affective Quality Network and Large Language Model
Jun 09, 2024



We live in a rich and varied acoustic world, which is experienced by individuals or communities as a soundscape. Computational auditory scene analysis, disentangling acoustic scenes by detecting and classifying events, focuses on objective attributes of sounds, such as their category and temporal characteristics, ignoring the effect of sounds on people and failing to explore the relationship between sounds and the emotions they evoke within a context. To fill this gap and to automate soundscape analysis, which traditionally relies on labour-intensive subjective ratings and surveys, we propose the soundscape captioning (SoundSCap) task. SoundSCap generates context-aware soundscape descriptions by capturing the acoustic scene, event information, and the corresponding human affective qualities. To this end, we propose an automatic soundscape captioner (SoundSCaper) composed of an acoustic model, SoundAQnet, and a general large language model (LLM). SoundAQnet simultaneously models multi-scale information about acoustic scenes, events, and perceived affective qualities, while LLM generates soundscape captions by parsing the information captured by SoundAQnet to a common language. The soundscape caption's quality is assessed by a jury of 16 audio/soundscape experts. The average score (out of 5) of SoundSCaper-generated captions is lower than the score of captions generated by two soundscape experts by 0.21 and 0.25, respectively, on the evaluation set and the model-unknown mixed external dataset with varying lengths and acoustic properties, but the differences are not statistically significant. Overall, SoundSCaper-generated captions show promising performance compared to captions annotated by soundscape experts. The models' code, LLM scripts, human assessment data and instructions, and expert evaluation statistics are all publicly available.
A novel Reservoir Architecture for Periodic Time Series Prediction
May 16, 2024This paper introduces a novel approach to predicting periodic time series using reservoir computing. The model is tailored to deliver precise forecasts of rhythms, a crucial aspect for tasks such as generating musical rhythm. Leveraging reservoir computing, our proposed method is ultimately oriented towards predicting human perception of rhythm. Our network accurately predicts rhythmic signals within the human frequency perception range. The model architecture incorporates primary and intermediate neurons tasked with capturing and transmitting rhythmic information. Two parameter matrices, denoted as c and k, regulate the reservoir's overall dynamics. We propose a loss function to adapt c post-training and introduce a dynamic selection (DS) mechanism that adjusts $k$ to focus on areas with outstanding contributions. Experimental results on a diverse test set showcase accurate predictions, further improved through real-time tuning of the reservoir via c and k. Comparative assessments highlight its superior performance compared to conventional models.
No More Mumbles: Enhancing Robot Intelligibility through Speech Adaptation
May 15, 2024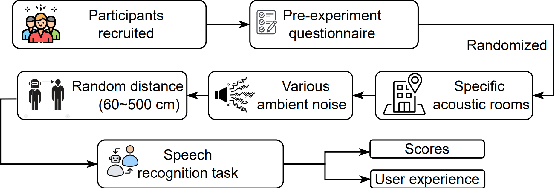


Spoken language interaction is at the heart of interpersonal communication, and people flexibly adapt their speech to different individuals and environments. It is surprising that robots, and by extension other digital devices, are not equipped to adapt their speech and instead rely on fixed speech parameters, which often hinder comprehension by the user. We conducted a speech comprehension study involving 39 participants who were exposed to different environmental and contextual conditions. During the experiment, the robot articulated words using different vocal parameters, and the participants were tasked with both recognising the spoken words and rating their subjective impression of the robot's speech. The experiment's primary outcome shows that spaces with good acoustic quality positively correlate with intelligibility and user experience. However, increasing the distance between the user and the robot exacerbated the user experience, while distracting background sounds significantly reduced speech recognition accuracy and user satisfaction. We next built an adaptive voice for the robot. For this, the robot needs to know how difficult it is for a user to understand spoken language in a particular setting. We present a prediction model that rates how annoying the ambient acoustic environment is and, consequentially, how hard it is to understand someone in this setting. Then, we develop a convolutional neural network model to adapt the robot's speech parameters to different users and spaces, while taking into account the influence of ambient acoustics on intelligibility. Finally, we present an evaluation with 27 users, demonstrating superior intelligibility and user experience with adaptive voice parameters compared to fixed voice.
EEG decoding with conditional identification information
Mar 21, 2024



Decoding EEG signals is crucial for unraveling human brain and advancing brain-computer interfaces. Traditional machine learning algorithms have been hindered by the high noise levels and inherent inter-person variations in EEG signals. Recent advances in deep neural networks (DNNs) have shown promise, owing to their advanced nonlinear modeling capabilities. However, DNN still faces challenge in decoding EEG samples of unseen individuals. To address this, this paper introduces a novel approach by incorporating the conditional identification information of each individual into the neural network, thereby enhancing model representation through the synergistic interaction of EEG and personal traits. We test our model on the WithMe dataset and demonstrated that the inclusion of these identifiers substantially boosts accuracy for both subjects in the training set and unseen subjects. This enhancement suggests promising potential for improving for EEG interpretability and understanding of relevant identification features.
Multi-level graph learning for audio event classification and human-perceived annoyance rating prediction
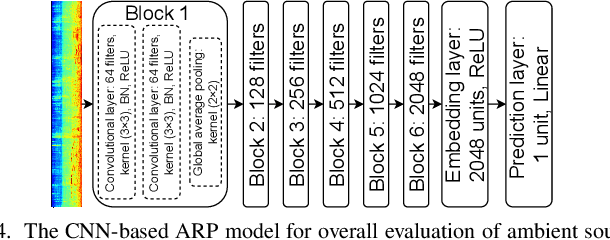
Dec 15, 2023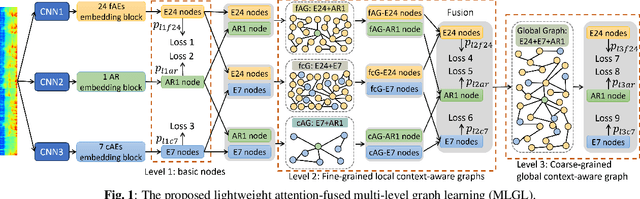
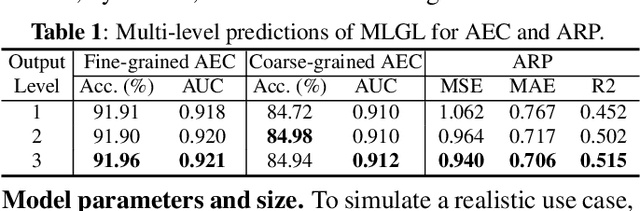
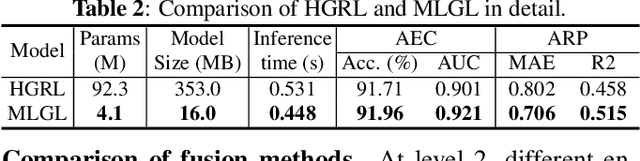
WHO's report on environmental noise estimates that 22 M people suffer from chronic annoyance related to noise caused by audio events (AEs) from various sources. Annoyance may lead to health issues and adverse effects on metabolic and cognitive systems. In cities, monitoring noise levels does not provide insights into noticeable AEs, let alone their relations to annoyance. To create annoyance-related monitoring, this paper proposes a graph-based model to identify AEs in a soundscape, and explore relations between diverse AEs and human-perceived annoyance rating (AR). Specifically, this paper proposes a lightweight multi-level graph learning (MLGL) based on local and global semantic graphs to simultaneously perform audio event classification (AEC) and human annoyance rating prediction (ARP). Experiments show that: 1) MLGL with 4.1 M parameters improves AEC and ARP results by using semantic node information in local and global context aware graphs; 2) MLGL captures relations between coarse and fine-grained AEs and AR well; 3) Statistical analysis of MLGL results shows that some AEs from different sources significantly correlate with AR, which is consistent with previous research on human perception of these sound sources.
AI-based soundscape analysis: Jointly identifying sound sources and predicting annoyance
Nov 15, 2023



Soundscape studies typically attempt to capture the perception and understanding of sonic environments by surveying users. However, for long-term monitoring or assessing interventions, sound-signal-based approaches are required. To this end, most previous research focused on psycho-acoustic quantities or automatic sound recognition. Few attempts were made to include appraisal (e.g., in circumplex frameworks). This paper proposes an artificial intelligence (AI)-based dual-branch convolutional neural network with cross-attention-based fusion (DCNN-CaF) to analyze automatic soundscape characterization, including sound recognition and appraisal. Using the DeLTA dataset containing human-annotated sound source labels and perceived annoyance, the DCNN-CaF is proposed to perform sound source classification (SSC) and human-perceived annoyance rating prediction (ARP). Experimental findings indicate that (1) the proposed DCNN-CaF using loudness and Mel features outperforms the DCNN-CaF using only one of them. (2) The proposed DCNN-CaF with cross-attention fusion outperforms other typical AI-based models and soundscape-related traditional machine learning methods on the SSC and ARP tasks. (3) Correlation analysis reveals that the relationship between sound sources and annoyance is similar for humans and the proposed AI-based DCNN-CaF model. (4) Generalization tests show that the proposed model's ARP in the presence of model-unknown sound sources is consistent with expert expectations and can explain previous findings from the literature on sound-scape augmentation.
* The Journal of the Acoustical Society of America, 154 (5), 3145