 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-motion as a structural prior for coherent and robust formation of cognitive maps
Dec 23, 2025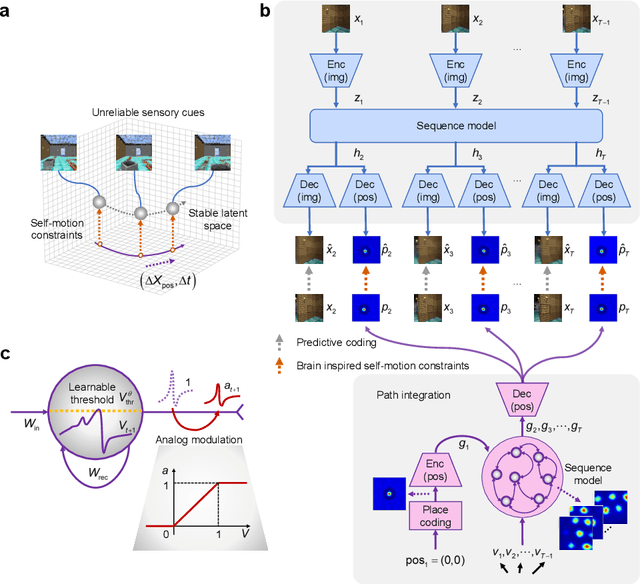
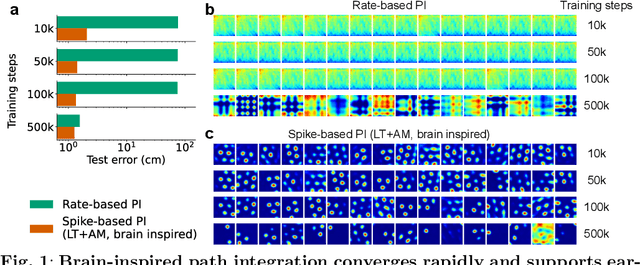
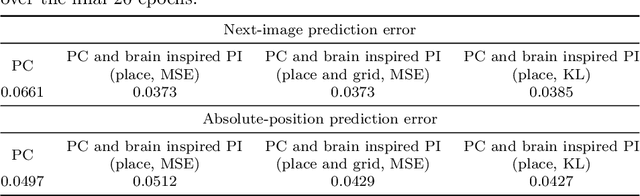
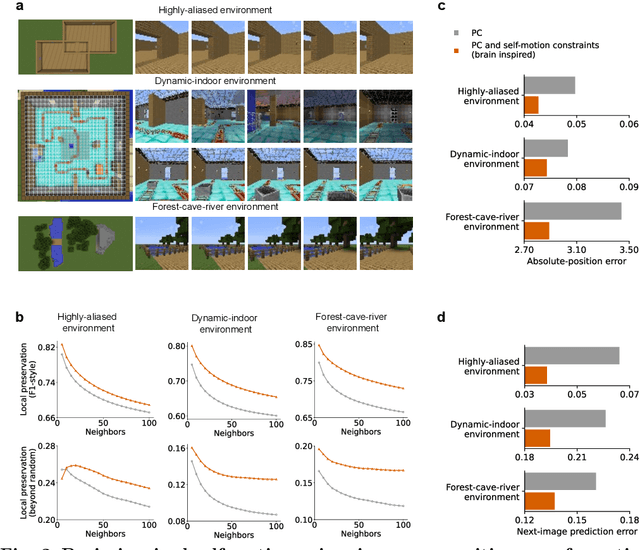
Most computational accounts of cognitive maps assume that stability is achieved primarily through sensory anchoring, with self-motion contributing to incremental positional updates only. However, biological spatial representations often remain coherent even when sensory cues degrade or conflict, suggesting that self-motion may play a deeper organizational role. Here, we show that self-motion can act as a structural prior that actively organizes the geometry of learned cognitive maps. We embed a path-integration-based motion prior in a predictive-coding framework, implemented using a capacity-efficient, brain-inspired recurrent mechanism combining spiking dynamics, analog modulation and adaptive thresholds. Across highly aliased, dynamically changing and naturalistic environments, this structural prior consistently stabilizes map formation, improving local topological fidelity, global positional accuracy and next-step prediction under sensory ambiguity. Mechanistic analyses reveal that the motion prior itself encodes geometrically precise trajectories under tight constraints of internal states and generalizes zero-shot to unseen environments, outperforming simpler motion-based constraints. Finally, deployment on a quadrupedal robot demonstrates that motion-derived structural priors enhance online landmark-based navigation under real-world sensory variability. Together, these results reframe self-motion as an organizing scaffold for coherent spatial representations, showing how brain-inspired principles can systematically strengthen spatial intelligence in embodied artificial agents.
Batch Normalization-Free Fully Integer Quantized Neural Networks via Progressive Tandem Learning
Dec 18, 2025Quantised neural networks (QNNs) shrink models and reduce inference energy through low-bit arithmetic, yet most still depend on a running statistics batch normalisation (BN) layer, preventing true integer-only deployment. Prior attempts remove BN by parameter folding or tailored initialisation; while helpful, they rarely recover BN's stability and accuracy and often impose bespoke constraints. We present a BN-free, fully integer QNN trained via a progressive, layer-wise distillation scheme that slots into existing low-bit pipelines. Starting from a pretrained BN-enabled teacher, we use layer-wise targets and progressive compensation to train a student that performs inference exclusively with integer arithmetic and contains no BN operations. On ImageNet with AlexNet, the BN-free model attains competitive Top-1 accuracy under aggressive quantisation. The procedure integrates directly with standard quantisation workflows, enabling end-to-end integer-only inference for resource-constrained settings such as edge and embedded devices.
Algorithm-hardware co-design of neuromorphic networks with dual memory pathways
Dec 11, 2025Spiking neural networks excel at event-driven sensing. Yet, maintaining task-relevant context over long timescales both algorithmically and in hardware, while respecting both tight energy and memory budgets, remains a core challenge in the field. We address this challenge through novel algorithm-hardware co-design effort. At the algorithm level, inspired by the cortical fast-slow organization in the brain, we introduce a neural network with an explicit slow memory pathway that, combined with fast spiking activity, enables a dual memory pathway (DMP) architecture in which each layer maintains a compact low-dimensional state that summarizes recent activity and modulates spiking dynamics. This explicit memory stabilizes learning while preserving event-driven sparsity, achieving competitive accuracy on long-sequence benchmarks with 40-60% fewer parameters than equivalent state-of-the-art spiking neural networks. At the hardware level, we introduce a near-memory-compute architecture that fully leverages the advantages of the DMP architecture by retaining its compact shared state while optimizing dataflow, across heterogeneous sparse-spike and dense-memory pathways. We show experimental results that demonstrate more than a 4x increase in throughput and over a 5x improvement in energy efficiency compared with state-of-the-art implementations. Together, these contributions demonstrate that biological principles can guide functional abstractions that are both algorithmically effective and hardware-efficient, establishing a scalable co-design paradigm for real-time neuromorphic computation and learning.
Exploiting heterogeneous delays for efficient computation in low-bit neural networks
Oct 31, 2025Neural networks rely on learning synaptic weights. However, this overlooks other neural parameters that can also be learned and may be utilized by the brain. One such parameter is the delay: the brain exhibits complex temporal dynamics with heterogeneous delays, where signals are transmitted asynchronously between neurons. It has been theorized that this delay heterogeneity, rather than a cost to be minimized, can be exploited in embodied contexts where task-relevant information naturally sits contextually in the time domain. We test this hypothesis by training spiking neural networks to modify not only their weights but also their delays at different levels of precision. We find that delay heterogeneity enables state-of-the-art performance on temporally complex neuromorphic problems and can be achieved even when weights are extremely imprecise (1.58-bit ternary precision: just positive, negative, or absent). By enabling high performance with extremely low-precision weights, delay heterogeneity allows memory-efficient solutions that maintain state-of-the-art accuracy even when weights are compressed over an order of magnitude more aggressively than typically studied weight-only networks. We show how delays and time-constants adaptively trade-off, and reveal through ablation that task performance depends on task-appropriate delay distributions, with temporally-complex tasks requiring longer delays. Our results suggest temporal heterogeneity is an important principle for efficient computation, particularly when task-relevant information is temporal - as in the physical world - with implications for embodied intelligent systems and neuromorphic hardware.
EEG decoding with conditional identification information
Mar 21, 2024



Decoding EEG signals is crucial for unraveling human brain and advancing brain-computer interfaces. Traditional machine learning algorithms have been hindered by the high noise levels and inherent inter-person variations in EEG signals. Recent advances in deep neural networks (DNNs) have shown promise, owing to their advanced nonlinear modeling capabilities. However, DNN still faces challenge in decoding EEG samples of unseen individuals. To address this, this paper introduces a novel approach by incorporating the conditional identification information of each individual into the neural network, thereby enhancing model representation through the synergistic interaction of EEG and personal traits. We test our model on the WithMe dataset and demonstrated that the inclusion of these identifiers substantially boosts accuracy for both subjects in the training set and unseen subjects. This enhancement suggests promising potential for improving for EEG interpretability and understanding of relevant identification features.
Delayed Memory Unit: Modelling Temporal Dependency Through Delay Gate
Oct 23, 2023



Recurrent Neural Networks (RNNs) are renowned for their adeptness in modeling temporal dependencies, a trait that has driven their widespread adoption for sequential data processing. Nevertheless, vanilla RNNs are confronted with the well-known issue of gradient vanishing and exploding, posing a significant challenge for learning and establishing long-range dependencies. Additionally, gated RNNs tend to be over-parameterized, resulting in poor network generalization. To address these challenges, we propose a novel Delayed Memory Unit (DMU) in this paper, wherein a delay line structure, coupled with delay gates, is introduced to facilitate temporal interaction and temporal credit assignment, so as to enhance the temporal modeling capabilities of vanilla RNNs. Particularly, the DMU is designed to directly distribute the input information to the optimal time instant in the future, rather than aggregating and redistributing it over time through intricate network dynamics. Our proposed DMU demonstrates superior temporal modeling capabilities across a broad range of sequential modeling tasks, utilizing considerably fewer parameters than other state-of-the-art gated RNN models in applications such as speech recognition, radar gesture recognition, ECG waveform segmentation, and permuted sequential image classification.
Adaptive Axonal Delays in feedforward spiking neural networks for accurate spoken word recognition
Feb 16, 2023Spiking neural networks (SNN) are a promising research avenue for building accurate and efficient automatic speech recognition systems. Recent advances in audio-to-spike encoding and training algorithms enable SNN to be applied in practical tasks. Biologically-inspired SNN communicates using sparse asynchronous events. Therefore, spike-timing is critical to SNN performance. In this aspect, most works focus on training synaptic weights and few have considered delays in event transmission, namely axonal delay. In this work, we consider a learnable axonal delay capped at a maximum value, which can be adapted according to the axonal delay distribution in each network layer. We show that our proposed method achieves the best classification results reported on the SHD dataset (92.45%) and NTIDIGITS dataset (95.09%). Our work illustrates the potential of training axonal delays for tasks with complex temporal structures.
Spikemax: Spike-based Loss Methods for Classification
May 19, 2022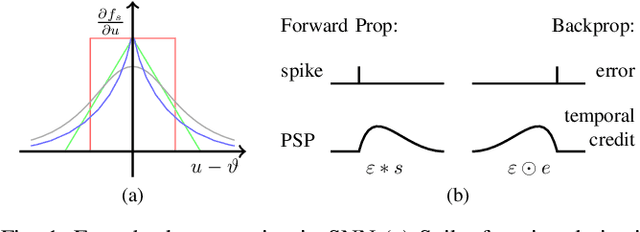
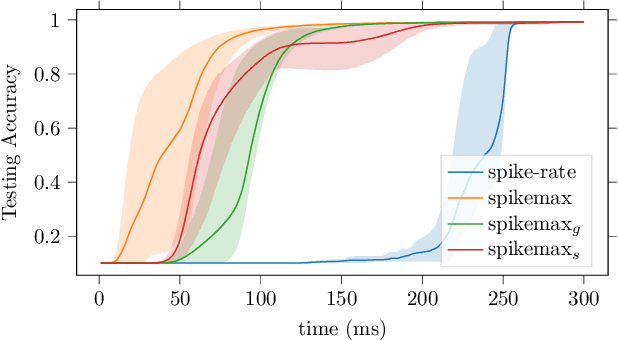

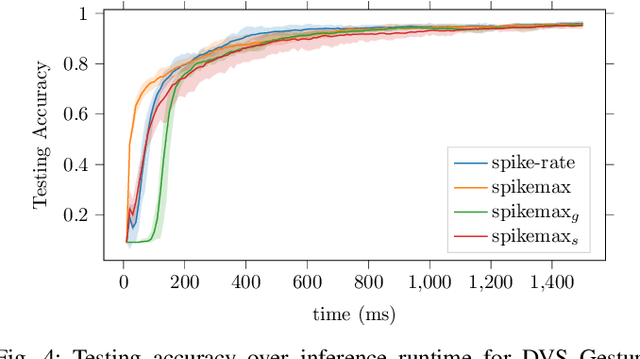
Spiking Neural Networks~(SNNs) are a promising research paradigm for low power edge-based computing. Recent works in SNN backpropagation has enabled training of SNNs for practical tasks. However, since spikes are binary events in time, standard loss formulations are not directly compatible with spike output. As a result, current works are limited to using mean-squared loss of spike count. In this paper, we formulate the output probability interpretation from the spike count measure and introduce spike-based negative log-likelihood measure which are more suited for classification tasks especially in terms of the energy efficiency and inference latency. We compare our loss measures with other existing alternatives and evaluate using classification performances on three neuromorphic benchmark datasets: NMNIST, DVS Gesture and N-TIDIGITS18. In addition, we demonstrate state of the art performances on these datasets, achieving faster inference speed and less energy consumption.
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021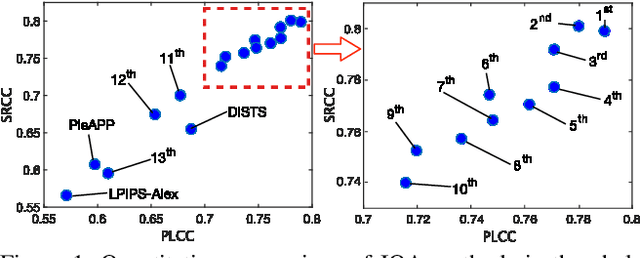
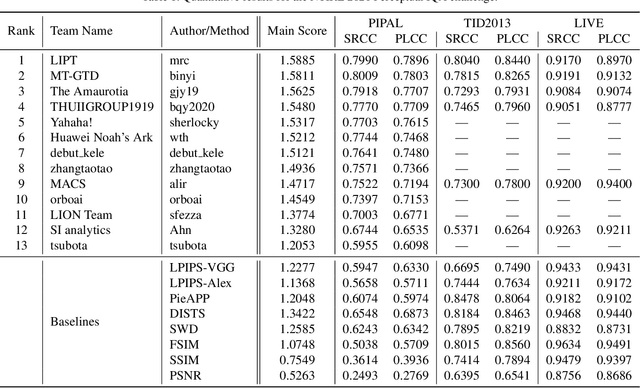

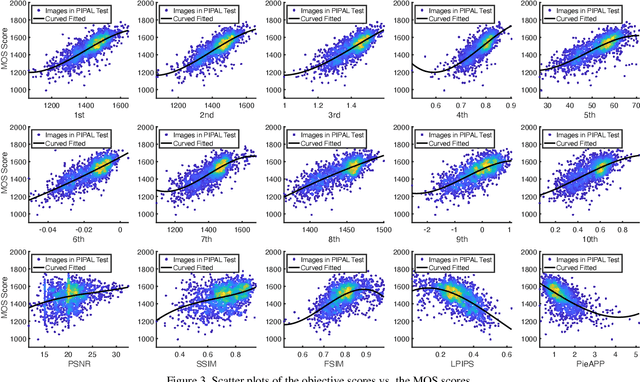
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.
GLMNet: Graph Learning-Matching Networks for Feature Matching
Nov 18, 2019


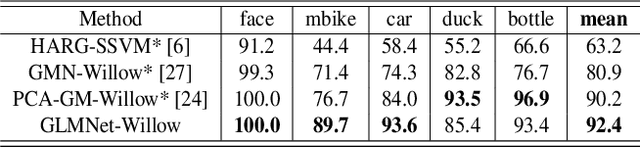
Recently, graph convolutional networks (GCNs) have shown great potential for the task of graph matching. It can integrate graph node feature embedding, node-wise affinity learning and matching optimization together in a unified end-to-end model. One important aspect of graph matching is the construction of two matching graphs. However, the matching graphs we feed to existing graph convolutional matching networks are generally fixed and independent of graph matching, which thus are not guaranteed to be optimal for the graph matching task. Also, existing GCN matching method employs several general smoothing-based graph convolutional layers to generate graph node embeddings, in which extensive smoothing convolution operation may dilute the desired discriminatory information of graph nodes. To overcome these issues, we propose a novel Graph Learning-Matching Network (GLMNet) for graph matching problem. GLMNet has three main aspects. (1) It integrates graph learning into graph matching which thus adaptively learn a pair of optimal graphs that best serve graph matching task. (2) It further employs a Laplacian sharpening convolutional module to generate more discriminative node embeddings for graph matching. (3) A new constraint regularized loss is designed for GLMNet training which can encode the desired one-to-one matching constraints in matching optimization. Experiments on two benchmarks demonstrate the effectiveness of GLMNet and advantages of its main modules.