 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural networks based EEG-Speech Models
Paper and Code
Mar 31, 2017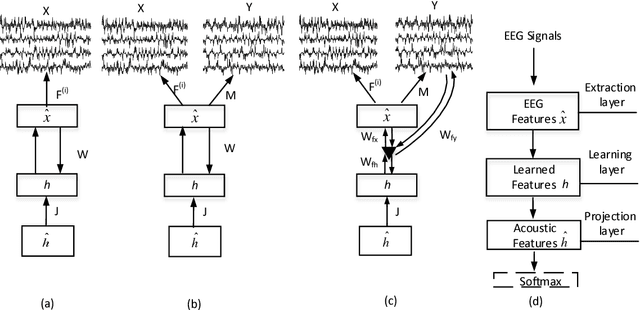

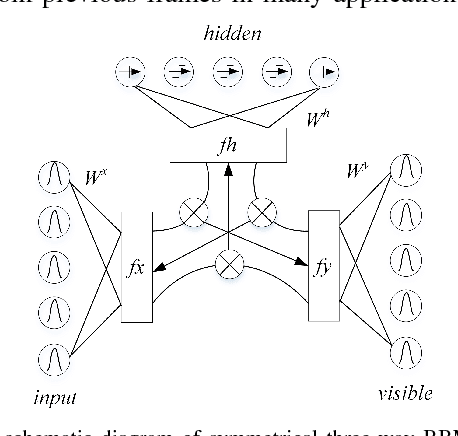

In this paper, we propose an end-to-end neural network (NN) based EEG-speech (NES) modeling framework, in which three network structures are developed to map imagined EEG signals to phonemes. The proposed NES models incorporate a language model based EEG feature extraction layer, an acoustic feature mapping layer, and a restricted Boltzmann machine (RBM) based the feature learning layer. The NES models can jointly realize the representation of multichannel EEG signals and the projection of acoustic speech signals. Among three proposed NES models, two augmented networks utilize spoken EEG signals as either bias or gate information to strengthen the feature learning and translation of imagined EEG signals. Experimental results show that all three proposed NES models outperform the baseline support vector machine (SVM) method on EEG-speech classification. With respect to binary classification, our approach achieves comparable results relative to deep believe network approach.