 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Data-Centric RLHF: Simple Metrics for Preference Dataset Comparison
Sep 15, 2024The goal of aligning language models to human preferences requires data that reveal these preferences. Ideally, time and money can be spent carefully collecting and tailoring bespoke preference data to each downstream application. However, in practice, a select few publicly available preference datasets are often used to train reward models for reinforcement learning from human feedback (RLHF). While new preference datasets are being introduced with increasing frequency, there are currently no existing efforts to measure and compare these datasets. In this paper, we systematically study preference datasets through three perspectives: scale, label noise, and information content. We propose specific metrics for each of these perspectives and uncover different axes of comparison for a better understanding of preference datasets. Our work is a first step towards a data-centric approach to alignment by providing perspectives that aid in training efficiency and iterative data collection for RLHF.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
DeepFeat: A Bottom Up and Top Down Saliency Model Based on Deep Features of Convolutional Neural Nets
Sep 08, 2017



A deep feature based saliency model (DeepFeat) is developed to leverage the understanding of the prediction of human fixations. Traditional saliency models often predict the human visual attention relying on few level image cues. Although such models predict fixations on a variety of image complexities, their approaches are limited to the incorporated features. In this study, we aim to provide an intuitive interpretation of convolu- tional neural network deep features by combining low and high level visual factors. We exploit four evaluation metrics to evaluate the correspondence between the proposed framework and the ground-truth fixations. The key findings of the results demon- strate that the DeepFeat algorithm, incorporation of bottom up and top down saliency maps, outperforms the individual bottom up and top down approach. Moreover, in comparison to nine 9 state-of-the-art saliency models, our proposed DeepFeat model achieves satisfactory performance based on all four evaluation metrics.
Line Profile Based Segmentation Algorithm for Touching Corn Kernels
Aug 04, 2017



Image segmentation of touching objects plays a key role in providing accurate classification for computer vision technologies. A new line profile based imaging segmentation algorithm has been developed to provide a robust and accurate segmentation of a group of touching corns. The performance of the line profile based algorithm has been compared to a watershed based imaging segmentation algorithm. Both algorithms are tested on three different patterns of images, which are isolated corns, single-lines, and random distributed formations. The experimental results show that the algorithm can segment a large number of touching corn kernels efficiently and accurately.
Enhanced Factored Three-Way Restricted Boltzmann Machines for Speech Detection
Apr 20, 2017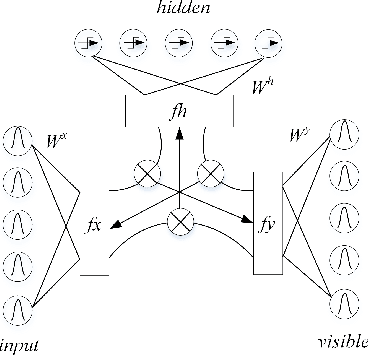

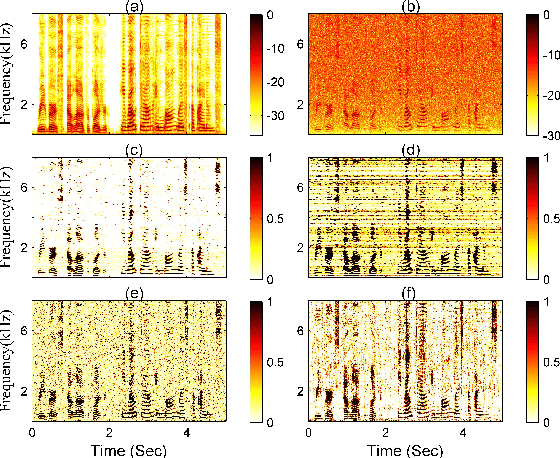
In this letter, we propose enhanced factored three way restricted Boltzmann machines (EFTW-RBMs) for speech detection. The proposed model incorporates conditional feature learning by multiplying the dynamical state of the third unit, which allows a modulation over the visible-hidden node pairs. Instead of stacking previous frames of speech as the third unit in a recursive manner, the correlation related weighting coefficients are assigned to the contextual neighboring frames. Specifically, a threshold function is designed to capture the long-term features and blend the globally stored speech structure. A factored low rank approximation is introduced to reduce the parameters of the three-dimensional interaction tensor, on which non-negative constraint is imposed to address the sparsity characteristic. The validations through the area-under-ROC-curve (AUC) and signal distortion ratio (SDR) show that our approach outperforms several existing 1D and 2D (i.e., time and time-frequency domain) speech detection algorithms in various noisy environments.
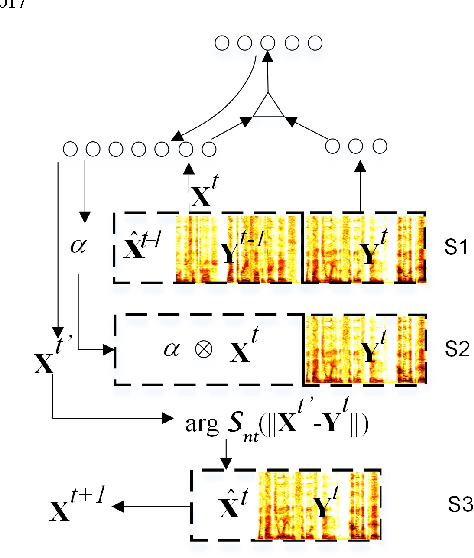
Neural networks based EEG-Speech Models
Mar 31, 2017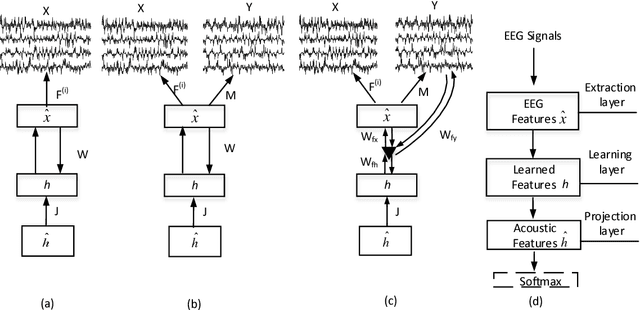

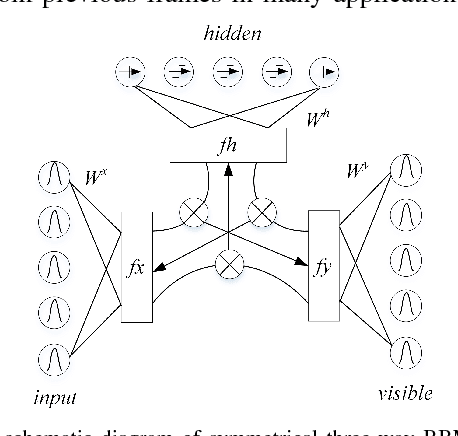

In this paper, we propose an end-to-end neural network (NN) based EEG-speech (NES) modeling framework, in which three network structures are developed to map imagined EEG signals to phonemes. The proposed NES models incorporate a language model based EEG feature extraction layer, an acoustic feature mapping layer, and a restricted Boltzmann machine (RBM) based the feature learning layer. The NES models can jointly realize the representation of multichannel EEG signals and the projection of acoustic speech signals. Among three proposed NES models, two augmented networks utilize spoken EEG signals as either bias or gate information to strengthen the feature learning and translation of imagined EEG signals. Experimental results show that all three proposed NES models outperform the baseline support vector machine (SVM) method on EEG-speech classification. With respect to binary classification, our approach achieves comparable results relative to deep believe network approach.