 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Every Note a Griff: Looking for a Useful Representation of Basso Continuo Performance Style
Jan 28, 2026Basso continuo is a baroque improvisatory accompaniment style which involves improvising multiple parts above a given bass line in a musical score on a harpsichord or organ. Basso continuo is not merely a matter of history; moreover, it is a historically inspired living practice, and The Aligned Continuo Dataset (ACoRD) records the first sample of modern-day basso continuo playing in the symbolic domain. This dataset, containing 175 MIDI recordings of 5 basso continuo scores performed by 7 players, allows us to start observing and analyzing the variety that basso continuo improvisation brings. A recently proposed basso continuo performance-to-score alignment system provides a way of mapping improvised performance notes to score notes. In order to study aligned basso continuo performances, we need an appropriate feature representation. We propose griff, a representation inspired by historical basso continuo treatises. It enables us to encode both pitch content and structure of a basso continuo realization in a transposition-invariant way. Griffs are directly extracted from aligned basso continuo performances by grouping together performance notes aligned to the same score note in a onset-time ordered way, and they provide meaningful tokens that form a feature space in which we can analyze basso continuo performance styles. We statistically describe griffs extracted from the ACoRD dataset recordings, and show in two experiments how griffs can be used for statistical analysis of individuality of different players' basso continuo performance styles. We finally present an argument why it is desirable to preserve the structure of a basso continuo improvisation in order to conduct a refined analysis of personal performance styles of individual basso continuo practitioners, and why griffs can provide a meaningful historically informed feature space worthy of a more robust empirical validation.
A Transformer-Based Visual Piano Transcription Algorithm
Nov 13, 2024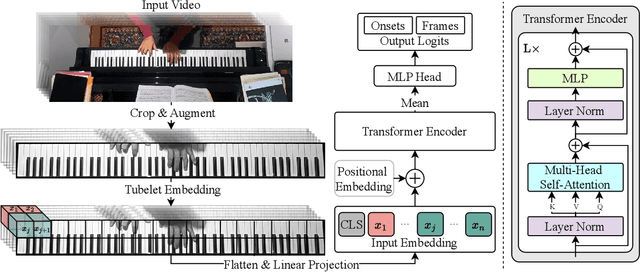
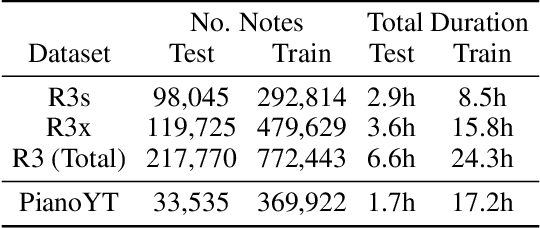
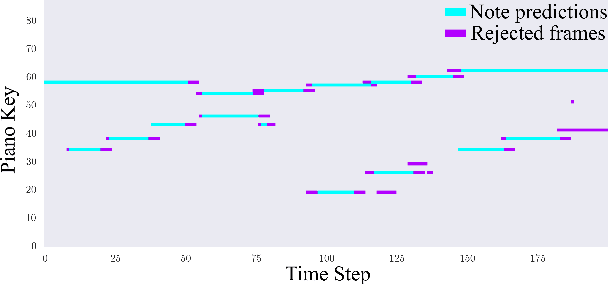
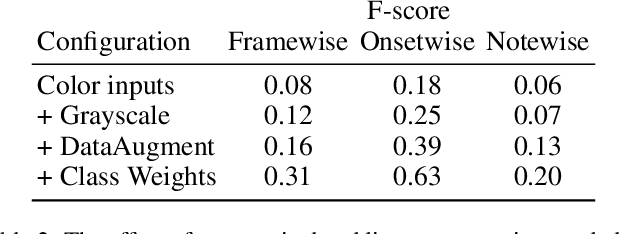
Automatic music transcription (AMT) for musical performances is a long standing problem in the field of Music Information Retrieval (MIR). Visual piano transcription (VPT) is a multimodal subproblem of AMT which focuses on extracting a symbolic representation of a piano performance from visual information only (e.g., from a top-down video of the piano keyboard). Inspired by the success of Transformers for audio-based AMT, as well as their recent successes in other computer vision tasks, in this paper we present a Transformer based architecture for VPT. The proposed VPT system combines a piano bounding box detection model with an onset and pitch detection model, allowing our system to perform well in more naturalistic conditions like imperfect image crops around the piano and slightly tilted images.
DExter: Learning and Controlling Performance Expression with Diffusion Models
Jun 21, 2024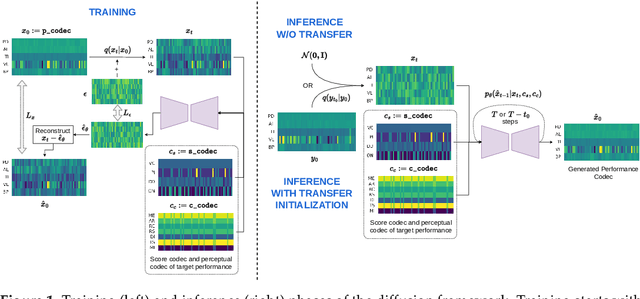
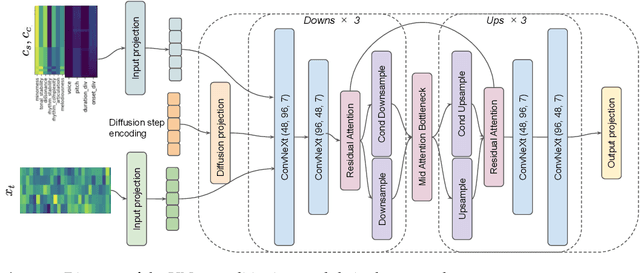
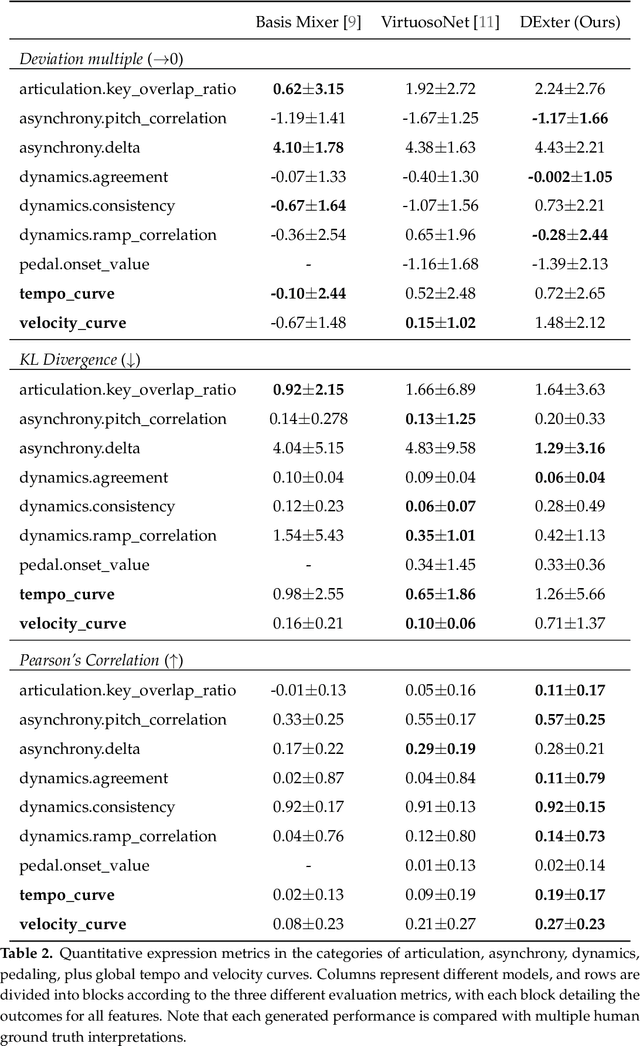
In the pursuit of developing expressive music performance models using artificial intelligence, this paper introduces DExter, a new approach leveraging diffusion probabilistic models to render Western classical piano performances. In this approach, performance parameters are represented in a continuous expression space and a diffusion model is trained to predict these continuous parameters while being conditioned on the musical score. Furthermore, DExter also enables the generation of interpretations (expressive variations of a performance) guided by perceptually meaningful features by conditioning jointly on score and perceptual feature representations. Consequently, we find that our model is useful for learning expressive performance, generating perceptually steered performances, and transferring performance styles. We assess the model through quantitative and qualitative analyses, focusing on specific performance metrics regarding dimensions like asynchrony and articulation, as well as through listening tests comparing generated performances with different human interpretations. Results show that DExter is able to capture the time-varying correlation of the expressive parameters, and compares well to existing rendering models in subjectively evaluated ratings. The perceptual-feature-conditioned generation and transferring capabilities of DExter are verified by a proxy model predicting perceptual characteristics of differently steered performances.
Sounding Out Reconstruction Error-Based Evaluation of Generative Models of Expressive Performance
Dec 31, 2023Generative models of expressive piano performance are usually assessed by comparing their predictions to a reference human performance. A generative algorithm is taken to be better than competing ones if it produces performances that are closer to a human reference performance. However, expert human performers can (and do) interpret music in different ways, making for different possible references, and quantitative closeness is not necessarily aligned with perceptual similarity, raising concerns about the validity of this evaluation approach. In this work, we present a number of experiments that shed light on this problem. Using precisely measured high-quality performances of classical piano music, we carry out a listening test indicating that listeners can sometimes perceive subtle performance difference that go unnoticed under quantitative evaluation. We further present tests that indicate that such evaluation frameworks show a lot of variability in reliability and validity across different reference performances and pieces. We discuss these results and their implications for quantitative evaluation, and hope to foster a critical appreciation of the uncertainties involved in quantitative assessments of such performances within the wider music information retrieval (MIR) community.
Are we describing the same sound? An analysis of word embedding spaces of expressive piano performance
Dec 31, 2023Semantic embeddings play a crucial role in natural language-based information retrieval. Embedding models represent words and contexts as vectors whose spatial configuration is derived from the distribution of words in large text corpora. While such representations are generally very powerful, they might fail to account for fine-grained domain-specific nuances. In this article, we investigate this uncertainty for the domain of characterizations of expressive piano performance. Using a music research dataset of free text performance characterizations and a follow-up study sorting the annotations into clusters, we derive a ground truth for a domain-specific semantic similarity structure. We test five embedding models and their similarity structure for correspondence with the ground truth. We further assess the effects of contextualizing prompts, hubness reduction, cross-modal similarity, and k-means clustering. The quality of embedding models shows great variability with respect to this task; more general models perform better than domain-adapted ones and the best model configurations reach human-level agreement.
Symbolic Music Representations for Classification Tasks: A Systematic Evaluation
Sep 10, 2023Music Information Retrieval (MIR) has seen a recent surge in deep learning-based approaches, which often involve encoding symbolic music (i.e., music represented in terms of discrete note events) in an image-like or language like fashion. However, symbolic music is neither an image nor a sentence, and research in the symbolic domain lacks a comprehensive overview of the different available representations. In this paper, we investigate matrix (piano roll), sequence, and graph representations and their corresponding neural architectures, in combination with symbolic scores and performances on three piece-level classification tasks. We also introduce a novel graph representation for symbolic performances and explore the capability of graph representations in global classification tasks. Our systematic evaluation shows advantages and limitations of each input representation. Our results suggest that the graph representation, as the newest and least explored among the three approaches, exhibits promising performance, while being more light-weight in training.
* To be published in the Proceedings of the 24th International Society for Music Information Retrieval Conference (ISMIR 2023), Milan, Italy