 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Transformer-Based Visual Piano Transcription Algorithm
Paper and Code
Nov 13, 2024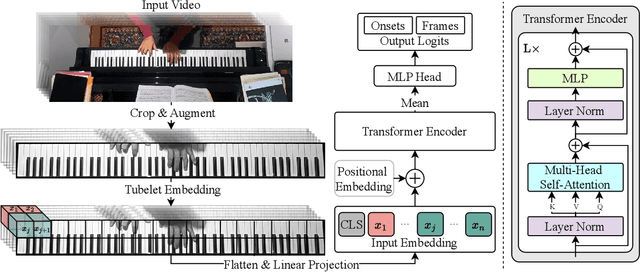
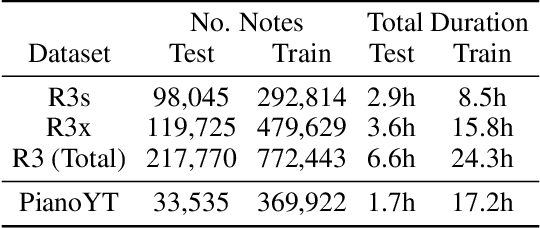
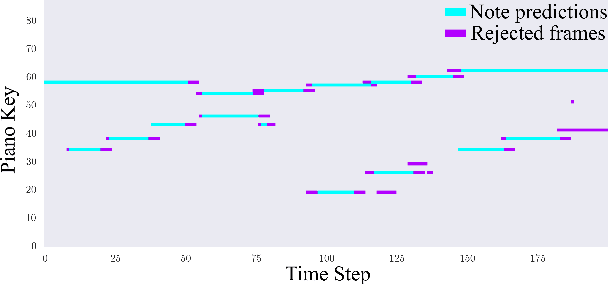
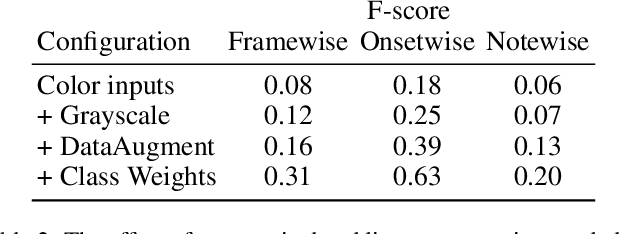
Automatic music transcription (AMT) for musical performances is a long standing problem in the field of Music Information Retrieval (MIR). Visual piano transcription (VPT) is a multimodal subproblem of AMT which focuses on extracting a symbolic representation of a piano performance from visual information only (e.g., from a top-down video of the piano keyboard). Inspired by the success of Transformers for audio-based AMT, as well as their recent successes in other computer vision tasks, in this paper we present a Transformer based architecture for VPT. The proposed VPT system combines a piano bounding box detection model with an onset and pitch detection model, allowing our system to perform well in more naturalistic conditions like imperfect image crops around the piano and slightly tilted images.