 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring System Adaptations For Minimum Latency Real-Time Piano Transcription
Sep 09, 2025Advances in neural network design and the availability of large-scale labeled datasets have driven major improvements in piano transcription. Existing approaches target either offline applications, with no restrictions on computational demands, or online transcription, with delays of 128-320 ms. However, most real-time musical applications require latencies below 30 ms. In this work, we investigate whether and how the current state-of-the-art online transcription model can be adapted for real-time piano transcription. Specifically, we eliminate all non-causal processing, and reduce computational load through shared computations across core model components and variations in model size. Additionally, we explore different pre- and postprocessing strategies, and related label encoding schemes, and discuss their suitability for real-time transcription. Evaluating the adaptions on the MAESTRO dataset, we find a drop in transcription accuracy due to strictly causal processing as well as a tradeoff between the preprocessing latency and prediction accuracy. We release our system as a baseline to support researchers in designing models towards minimum latency real-time transcription.
TheGlueNote: Learned Representations for Robust and Flexible Note Alignment
Aug 08, 2024

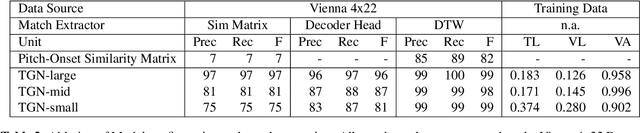
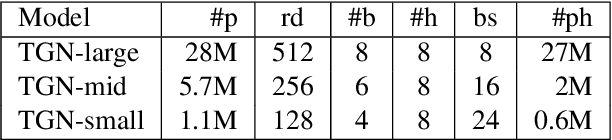
Note alignment refers to the task of matching individual notes of two versions of the same symbolically encoded piece. Methods addressing this task commonly rely on sequence alignment algorithms such as Hidden Markov Models or Dynamic Time Warping (DTW) applied directly to note or onset sequences. While successful in many cases, such methods struggle with large mismatches between the versions. In this work, we learn note-wise representations from data augmented with various complex mismatch cases, e.g. repeats, skips, block insertions, and long trills. At the heart of our approach lies a transformer encoder network - TheGlueNote - which predicts pairwise note similarities for two 512 note subsequences. We postprocess the predicted similarities using flavors of weightedDTW and pitch-separated onsetDTW to retrieve note matches for two sequences of arbitrary length. Our approach performs on par with the state of the art in terms of note alignment accuracy, is considerably more robust to version mismatches, and works directly on any pair of MIDI files.
Sounding Out Reconstruction Error-Based Evaluation of Generative Models of Expressive Performance
Dec 31, 2023Generative models of expressive piano performance are usually assessed by comparing their predictions to a reference human performance. A generative algorithm is taken to be better than competing ones if it produces performances that are closer to a human reference performance. However, expert human performers can (and do) interpret music in different ways, making for different possible references, and quantitative closeness is not necessarily aligned with perceptual similarity, raising concerns about the validity of this evaluation approach. In this work, we present a number of experiments that shed light on this problem. Using precisely measured high-quality performances of classical piano music, we carry out a listening test indicating that listeners can sometimes perceive subtle performance difference that go unnoticed under quantitative evaluation. We further present tests that indicate that such evaluation frameworks show a lot of variability in reliability and validity across different reference performances and pieces. We discuss these results and their implications for quantitative evaluation, and hope to foster a critical appreciation of the uncertainties involved in quantitative assessments of such performances within the wider music information retrieval (MIR) community.
Are we describing the same sound? An analysis of word embedding spaces of expressive piano performance
Dec 31, 2023Semantic embeddings play a crucial role in natural language-based information retrieval. Embedding models represent words and contexts as vectors whose spatial configuration is derived from the distribution of words in large text corpora. While such representations are generally very powerful, they might fail to account for fine-grained domain-specific nuances. In this article, we investigate this uncertainty for the domain of characterizations of expressive piano performance. Using a music research dataset of free text performance characterizations and a follow-up study sorting the annotations into clusters, we derive a ground truth for a domain-specific semantic similarity structure. We test five embedding models and their similarity structure for correspondence with the ground truth. We further assess the effects of contextualizing prompts, hubness reduction, cross-modal similarity, and k-means clustering. The quality of embedding models shows great variability with respect to this task; more general models perform better than domain-adapted ones and the best model configurations reach human-level agreement.
Online Symbolic Music Alignment with Offline Reinforcement Learning
Dec 31, 2023



Symbolic Music Alignment is the process of matching performed MIDI notes to corresponding score notes. In this paper, we introduce a reinforcement learning (RL)-based online symbolic music alignment technique. The RL agent - an attention-based neural network - iteratively estimates the current score position from local score and performance contexts. For this symbolic alignment task, environment states can be sampled exhaustively and the reward is dense, rendering a formulation as a simplified offline RL problem straightforward. We evaluate the trained agent in three ways. First, in its capacity to identify correct score positions for sampled test contexts; second, as the core technique of a complete algorithm for symbolic online note-wise alignment; and finally, as a real-time symbolic score follower. We further investigate the pitch-based score and performance representations used as the agent's inputs. To this end, we develop a second model, a two-step Dynamic Time Warping (DTW)-based offline alignment algorithm leveraging the same input representation. The proposed model outperforms a state-of-the-art reference model of offline symbolic music alignment.
The match file format: Encoding Alignments between Scores and Performances
Jun 02, 2022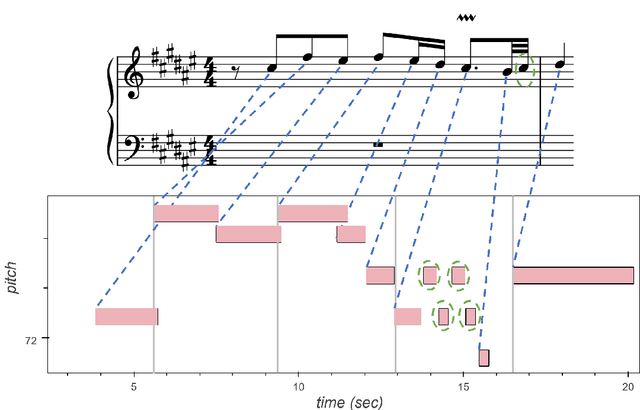


This paper presents the specifications of match: a file format that extends a MIDI human performance with note-, beat-, and downbeat-level alignments to a corresponding musical score. This enables advanced analyses of the performance that are relevant for various tasks, such as expressive performance modeling, score following, music transcription, and performer classification. The match file includes a set of score-related descriptors that makes it usable also as a bare-bones score representation. For applications that require the use of structural score elements (e.g., voices, parts, beams, slurs), the match file can be easily combined with the symbolic score. To support the practical application of our work, we release a corrected and upgraded version of the Vienna4x22 dataset of scores and performances aligned with match files.
Partitura: A Python Package for Symbolic Music Processing
Jun 02, 2022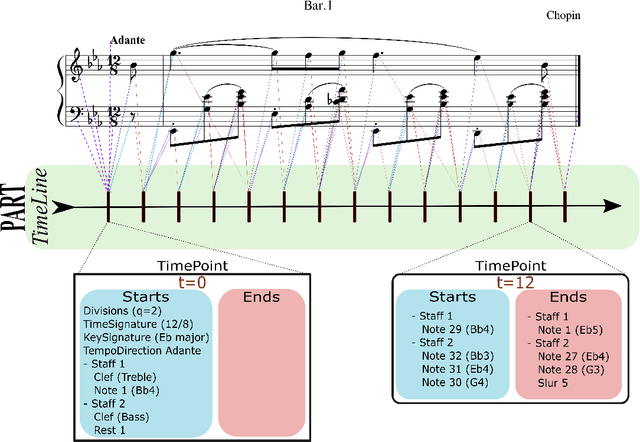

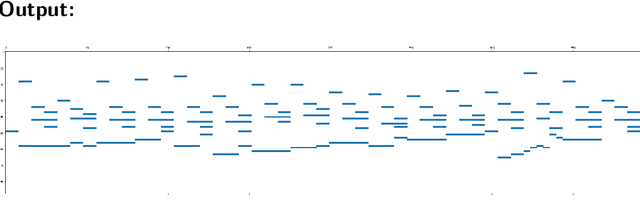
Partitura is a lightweight Python package for handling symbolic musical information. It provides easy access to features commonly used in music information retrieval tasks, like note arrays (lists of timed pitched events) and 2D piano roll matrices, as well as other score elements such as time and key signatures, performance directives, and repeat structures. Partitura can load musical scores (in MEI, MusicXML, Kern, and MIDI formats), MIDI performances, and score-to-performance alignments. The package includes some tools for music analysis, such as automatic pitch spelling, key signature identification, and voice separation. Partitura is an open-source project and is available at https://github.com/CPJKU/partitura/.