 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsights on Harmonic Tones from a Generative Music Experiment
Jun 08, 2025The ultimate purpose of generative music AI is music production. The studio-lab, a social form within the art-science branch of cross-disciplinarity, is a way to advance music production with AI music models. During a studio-lab experiment involving researchers, music producers, and an AI model for music generating bass-like audio, it was observed that the producers used the model's output to convey two or more pitches with a single harmonic complex tone, which in turn revealed that the model had learned to generate structured and coherent simultaneous melodic lines using monophonic sequences of harmonic complex tones. These findings prompt a reconsideration of the long-standing debate on whether humans can perceive harmonics as distinct pitches and highlight how generative AI can not only enhance musical creativity but also contribute to a deeper understanding of music.
Accompaniment Prompt Adherence: A Measure for Evaluating Music Accompaniment Systems
Mar 08, 2025



Generative systems of musical accompaniments are rapidly growing, yet there are no standardized metrics to evaluate how well generations align with the conditional audio prompt. We introduce a distribution-based measure called "Accompaniment Prompt Adherence" (APA), and validate it through objective experiments on synthetic data perturbations, and human listening tests. Results show that APA aligns well with human judgments of adherence and is discriminative to transformations that degrade adherence. We release a Python implementation of the metric using the widely adopted pre-trained CLAP embedding model, offering a valuable tool for evaluating and comparing accompaniment generation systems.
Diff-A-Riff: Musical Accompaniment Co-creation via Latent Diffusion Models
Jun 12, 2024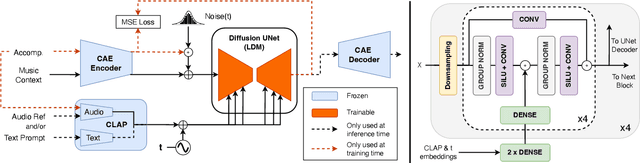
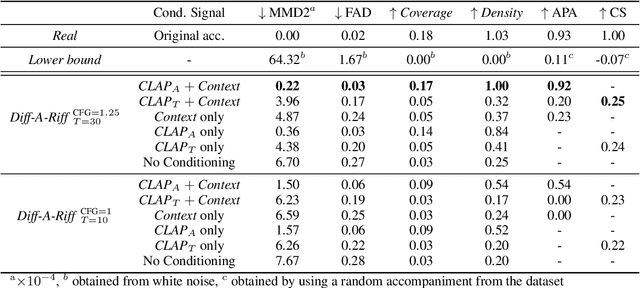
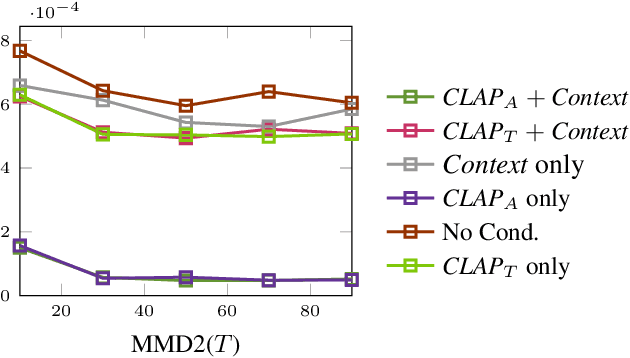
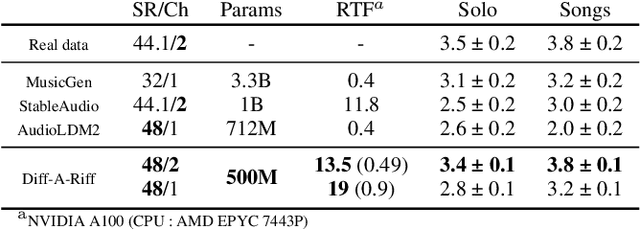
Recent advancements in deep generative models present new opportunities for music production but also pose challenges, such as high computational demands and limited audio quality. Moreover, current systems frequently rely solely on text input and typically focus on producing complete musical pieces, which is incompatible with existing workflows in music production. To address these issues, we introduce "Diff-A-Riff," a Latent Diffusion Model designed to generate high-quality instrumental accompaniments adaptable to any musical context. This model offers control through either audio references, text prompts, or both, and produces 48kHz pseudo-stereo audio while significantly reducing inference time and memory usage. We demonstrate the model's capabilities through objective metrics and subjective listening tests, with extensive examples available on the accompanying website: sonycslparis.github.io/diffariff-companion/
Measuring audio prompt adherence with distribution-based embedding distances
Apr 04, 2024An increasing number of generative music models can be conditioned on an audio prompt that serves as musical context for which the model is to create an accompaniment (often further specified using a text prompt). Evaluation of how well model outputs adhere to the audio prompt is often done in a model or problem specific manner, presumably because no generic evaluation method for audio prompt adherence has emerged. Such a method could be useful both in the development and training of new models, and to make performance comparable across models. In this paper we investigate whether commonly used distribution-based distances like Fr\'echet Audio Distance (FAD), can be used to measure audio prompt adherence. We propose a simple procedure based on a small number of constituents (an embedding model, a projection, an embedding distance, and a data fusion method), that we systematically assess using a baseline validation. In a follow-up experiment we test the sensitivity of the proposed audio adherence measure to pitch and time shift perturbations. The results show that the proposed measure is sensitive to such perturbations, even when the reference and candidate distributions are from different music collections. Although more experimentation is needed to answer unaddressed questions like the robustness of the measure to acoustic artifacts that do not affect the audio prompt adherence, the current results suggest that distribution-based embedding distances provide a viable way of measuring audio prompt adherence. An python/pytorch implementation of the proposed measure is publicly available as a github repository.
Bass Accompaniment Generation via Latent Diffusion
Feb 02, 2024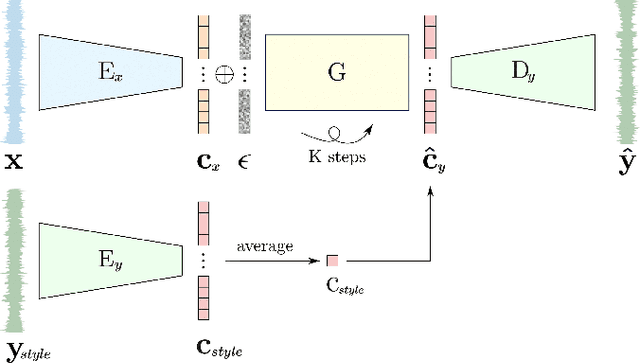
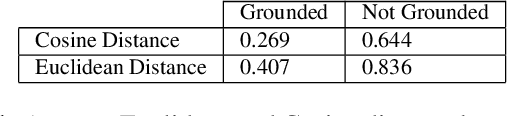
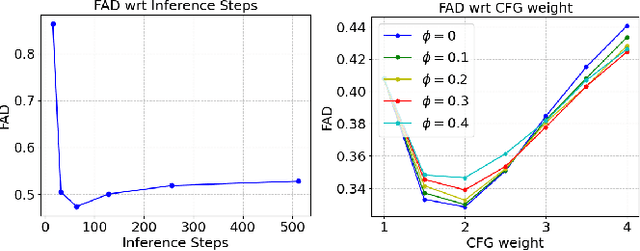
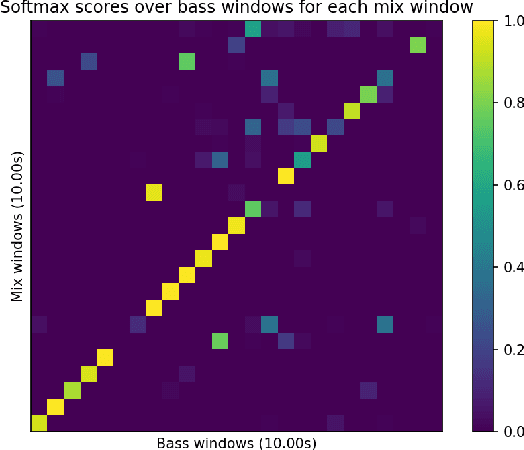
The ability to automatically generate music that appropriately matches an arbitrary input track is a challenging task. We present a novel controllable system for generating single stems to accompany musical mixes of arbitrary length. At the core of our method are audio autoencoders that efficiently compress audio waveform samples into invertible latent representations, and a conditional latent diffusion model that takes as input the latent encoding of a mix and generates the latent encoding of a corresponding stem. To provide control over the timbre of generated samples, we introduce a technique to ground the latent space to a user-provided reference style during diffusion sampling. For further improving audio quality, we adapt classifier-free guidance to avoid distortions at high guidance strengths when generating an unbounded latent space. We train our model on a dataset of pairs of mixes and matching bass stems. Quantitative experiments demonstrate that, given an input mix, the proposed system can generate basslines with user-specified timbres. Our controllable conditional audio generation framework represents a significant step forward in creating generative AI tools to assist musicians in music production.
"Melatonin": A Case Study on AI-induced Musical Style
Aug 18, 2022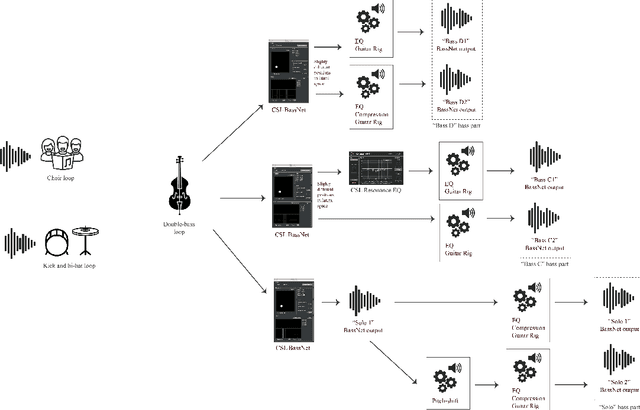


Although the use of AI tools in music composition and production is steadily increasing, as witnessed by the newly founded AI song contest, analysis of music produced using these tools is still relatively uncommon as a mean to gain insight in the ways AI tools impact music production. In this paper we present a case study of "Melatonin", a song produced by extensive use of BassNet, an AI tool originally designed to generate bass lines. Through analysis of the artists' work flow and song project, we identify style characteristics of the song in relation to the affordances of the tool, highlighting manifestations of style in terms of both idiom and sound.
The match file format: Encoding Alignments between Scores and Performances
Jun 02, 2022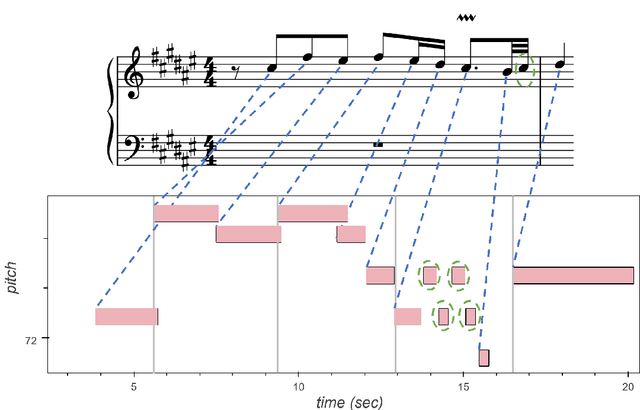


This paper presents the specifications of match: a file format that extends a MIDI human performance with note-, beat-, and downbeat-level alignments to a corresponding musical score. This enables advanced analyses of the performance that are relevant for various tasks, such as expressive performance modeling, score following, music transcription, and performer classification. The match file includes a set of score-related descriptors that makes it usable also as a bare-bones score representation. For applications that require the use of structural score elements (e.g., voices, parts, beams, slurs), the match file can be easily combined with the symbolic score. To support the practical application of our work, we release a corrected and upgraded version of the Vienna4x22 dataset of scores and performances aligned with match files.
Partitura: A Python Package for Symbolic Music Processing
Jun 02, 2022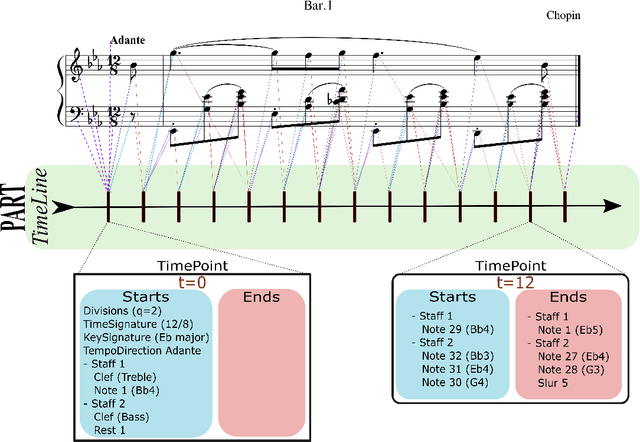

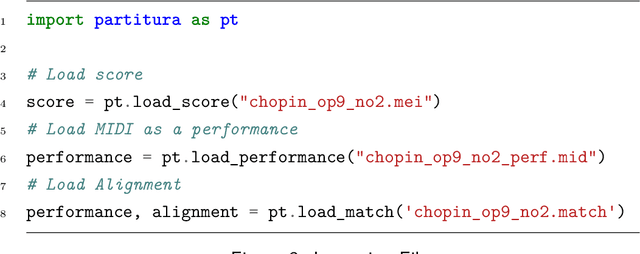
Partitura is a lightweight Python package for handling symbolic musical information. It provides easy access to features commonly used in music information retrieval tasks, like note arrays (lists of timed pitched events) and 2D piano roll matrices, as well as other score elements such as time and key signatures, performance directives, and repeat structures. Partitura can load musical scores (in MEI, MusicXML, Kern, and MIDI formats), MIDI performances, and score-to-performance alignments. The package includes some tools for music analysis, such as automatic pitch spelling, key signature identification, and voice separation. Partitura is an open-source project and is available at https://github.com/CPJKU/partitura/.
partitura: A Python Package for Handling Symbolic Musical Data
Jan 31, 2022This demo paper introduces partitura, a Python package for handling symbolic musical information. The principal aim of this package is to handle richly structured musical information as conveyed by modern staff music notation. It provides a much wider range of possibilities to deal with music than the more reductive (but very common) piano roll-oriented approach inspired by the MIDI standard. The package is an open source project and is available on GitHub.
High-Level Control of Drum Track Generation Using Learned Patterns of Rhythmic Interaction
Aug 02, 2019



Spurred by the potential of deep learning, computational music generation has gained renewed academic interest. A crucial issue in music generation is that of user control, especially in scenarios where the music generation process is conditioned on existing musical material. Here we propose a model for conditional kick drum track generation that takes existing musical material as input, in addition to a low-dimensional code that encodes the desired relation between the existing material and the new material to be generated. These relational codes are learned in an unsupervised manner from a music dataset. We show that codes can be sampled to create a variety of musically plausible kick drum tracks and that the model can be used to transfer kick drum patterns from one song to another. Lastly, we demonstrate that the learned codes are largely invariant to tempo and time-shift.