 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveBand: Live Accompaniment Generation in the Audio Domain
Jun 02, 2026We present LiveBand, a real-time system that generates high-fidelity music accompaniments to live audio input, respecting strict causal constraints. Our method trains a causal transformer generator in the continuous latent space of a pre-trained causal audio autoencoder, using adversarial sequence-level supervision from a discriminator. At each timestep, the generator receives only the causally available mix context and Gaussian noise, and predicts accompaniment latents without access to future mix frames or ground-truth target latents. Training is performed in a single parallel forward pass under causal masking, while streaming inference proceeds autoregressively with a rolling attention state. The model's training and inference computations are matched by design, eliminating teacher forcing and the associated exposure bias. On a multi-instrument music accompaniment benchmark, LiveBand improves over prior work on objective measures of audio quality, beat alignment, and mix adherence, while enabling real-time streaming generation without lookahead into the future on consumer hardware.
Diffusion Timbre Transfer Via Mutual Information Guided Inpainting
Jan 03, 2026We study timbre transfer as an inference-time editing problem for music audio. Starting from a strong pre-trained latent diffusion model, we introduce a lightweight procedure that requires no additional training: (i) a dimension-wise noise injection that targets latent channels most informative of instrument identity, and (ii) an early-step clamping mechanism that re-imposes the input's melodic and rhythmic structure during reverse diffusion. The method operates directly on audio latents and is compatible with text/audio conditioning (e.g., CLAP). We discuss design choices,analyze trade-offs between timbral change and structural preservation, and show that simple inference-time controls can meaningfully steer pre-trained models for style-transfer use cases.
LiLAC: A Lightweight Latent ControlNet for Musical Audio Generation
Jun 13, 2025Text-to-audio diffusion models produce high-quality and diverse music but many, if not most, of the SOTA models lack the fine-grained, time-varying controls essential for music production. ControlNet enables attaching external controls to a pre-trained generative model by cloning and fine-tuning its encoder on new conditionings. However, this approach incurs a large memory footprint and restricts users to a fixed set of controls. We propose a lightweight, modular architecture that considerably reduces parameter count while matching ControlNet in audio quality and condition adherence. Our method offers greater flexibility and significantly lower memory usage, enabling more efficient training and deployment of independent controls. We conduct extensive objective and subjective evaluations and provide numerous audio examples on the accompanying website at https://lightlatentcontrol.github.io
Accompaniment Prompt Adherence: A Measure for Evaluating Music Accompaniment Systems
Mar 08, 2025



Generative systems of musical accompaniments are rapidly growing, yet there are no standardized metrics to evaluate how well generations align with the conditional audio prompt. We introduce a distribution-based measure called "Accompaniment Prompt Adherence" (APA), and validate it through objective experiments on synthetic data perturbations, and human listening tests. Results show that APA aligns well with human judgments of adherence and is discriminative to transformations that degrade adherence. We release a Python implementation of the metric using the widely adopted pre-trained CLAP embedding model, offering a valuable tool for evaluating and comparing accompaniment generation systems.
Continuous Autoregressive Models with Noise Augmentation Avoid Error Accumulation
Nov 27, 2024Autoregressive models are typically applied to sequences of discrete tokens, but recent research indicates that generating sequences of continuous embeddings in an autoregressive manner is also feasible. However, such Continuous Autoregressive Models (CAMs) can suffer from a decline in generation quality over extended sequences due to error accumulation during inference. We introduce a novel method to address this issue by injecting random noise into the input embeddings during training. This procedure makes the model robust against varying error levels at inference. We further reduce error accumulation through an inference procedure that introduces low-level noise. Experiments on musical audio generation show that CAM substantially outperforms existing autoregressive and non-autoregressive approaches while preserving audio quality over extended sequences. This work paves the way for generating continuous embeddings in a purely autoregressive setting, opening new possibilities for real-time and interactive generative applications.
Improving Musical Accompaniment Co-creation via Diffusion Transformers
Oct 30, 2024Building upon Diff-A-Riff, a latent diffusion model for musical instrument accompaniment generation, we present a series of improvements targeting quality, diversity, inference speed, and text-driven control. First, we upgrade the underlying autoencoder to a stereo-capable model with superior fidelity and replace the latent U-Net with a Diffusion Transformer. Additionally, we refine text prompting by training a cross-modality predictive network to translate text-derived CLAP embeddings to audio-derived CLAP embeddings. Finally, we improve inference speed by training the latent model using a consistency framework, achieving competitive quality with fewer denoising steps. Our model is evaluated against the original Diff-A-Riff variant using objective metrics in ablation experiments, demonstrating promising advancements in all targeted areas. Sound examples are available at: https://sonycslparis.github.io/improved_dar/.
Diff-A-Riff: Musical Accompaniment Co-creation via Latent Diffusion Models
Jun 12, 2024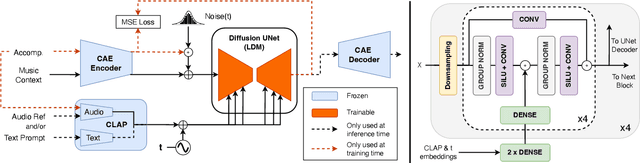
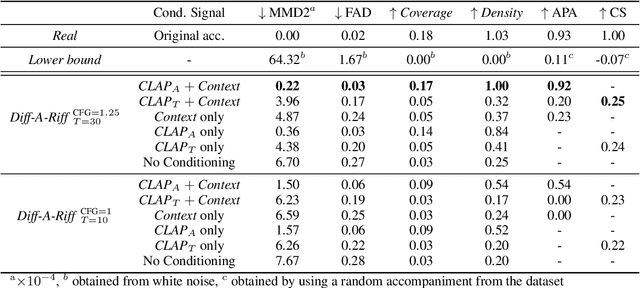
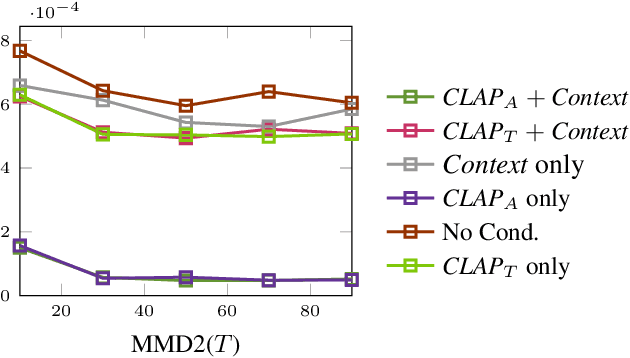
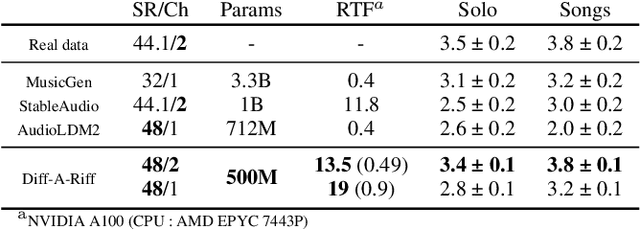
Recent advancements in deep generative models present new opportunities for music production but also pose challenges, such as high computational demands and limited audio quality. Moreover, current systems frequently rely solely on text input and typically focus on producing complete musical pieces, which is incompatible with existing workflows in music production. To address these issues, we introduce "Diff-A-Riff," a Latent Diffusion Model designed to generate high-quality instrumental accompaniments adaptable to any musical context. This model offers control through either audio references, text prompts, or both, and produces 48kHz pseudo-stereo audio while significantly reducing inference time and memory usage. We demonstrate the model's capabilities through objective metrics and subjective listening tests, with extensive examples available on the accompanying website: sonycslparis.github.io/diffariff-companion/
Stochastic Restoration of Heavily Compressed Musical Audio using Generative Adversarial Networks
Jul 04, 2022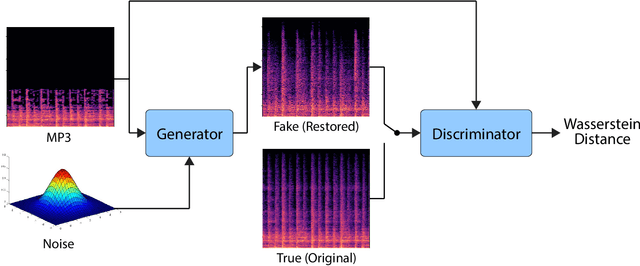
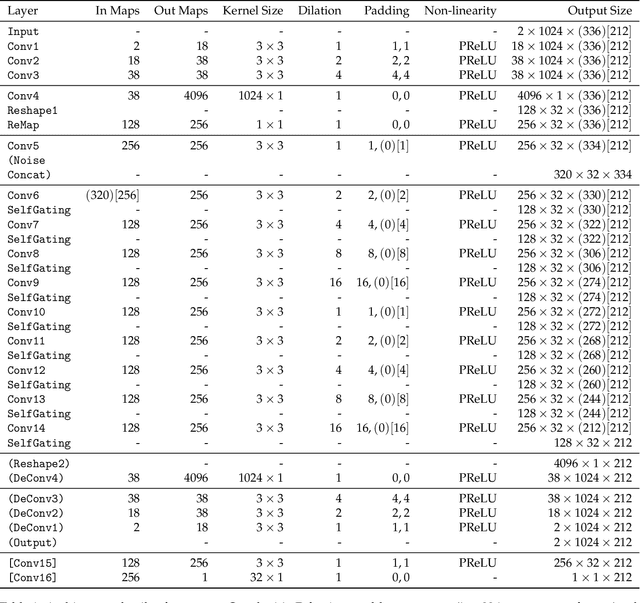
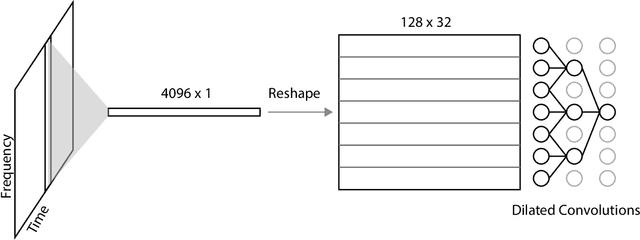
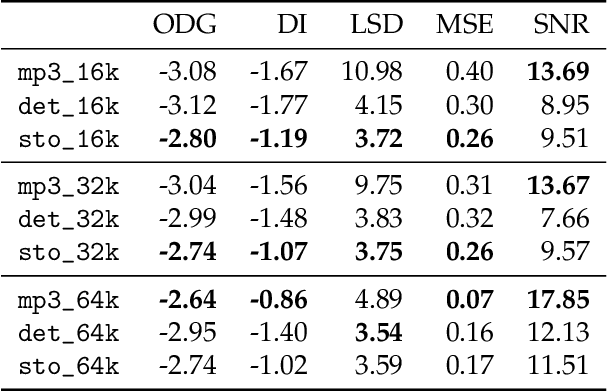
Lossy audio codecs compress (and decompress) digital audio streams by removing information that tends to be inaudible in human perception. Under high compression rates, such codecs may introduce a variety of impairments in the audio signal. Many works have tackled the problem of audio enhancement and compression artifact removal using deep learning techniques. However, only a few works tackle the restoration of heavily compressed audio signals in the musical domain. In such a scenario, there is no unique solution for the restoration of the original signal. Therefore, in this study, we test a stochastic generator of a Generative Adversarial Network (GAN) architecture for this task. Such a stochastic generator, conditioned on highly compressed musical audio signals, could one day generate outputs indistinguishable from high-quality releases. Therefore, the present study may yield insights into more efficient musical data storage and transmission. We train stochastic and deterministic generators on MP3-compressed audio signals with 16, 32, and 64 kbit/s. We perform an extensive evaluation of the different experiments utilizing objective metrics and listening tests. We find that the models can improve the quality of the audio signals over the MP3 versions for 16 and 32 kbit/s and that the stochastic generators are capable of generating outputs that are closer to the original signals than those of the deterministic generators.
* 21 pages, 5 figures, published in MDPI Electronics Special Issue "Machine Learning Applied to Music/Audio Signal Processing"
DrumGAN VST: A Plugin for Drum Sound Analysis/Synthesis With Autoencoding Generative Adversarial Networks
Jun 29, 2022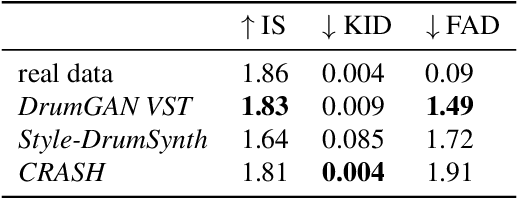
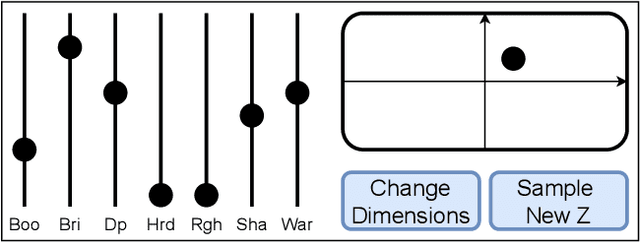


In contemporary popular music production, drum sound design is commonly performed by cumbersome browsing and processing of pre-recorded samples in sound libraries. One can also use specialized synthesis hardware, typically controlled through low-level, musically meaningless parameters. Today, the field of Deep Learning offers methods to control the synthesis process via learned high-level features and allows generating a wide variety of sounds. In this paper, we present DrumGAN VST, a plugin for synthesizing drum sounds using a Generative Adversarial Network. DrumGAN VST operates on 44.1 kHz sample-rate audio, offers independent and continuous instrument class controls, and features an encoding neural network that maps sounds into the GAN's latent space, enabling resynthesis and manipulation of pre-existing drum sounds. We provide numerous sound examples and a demo of the proposed VST plugin.
DarkGAN: Exploiting Knowledge Distillation for Comprehensible Audio Synthesis with GANs
Aug 03, 2021

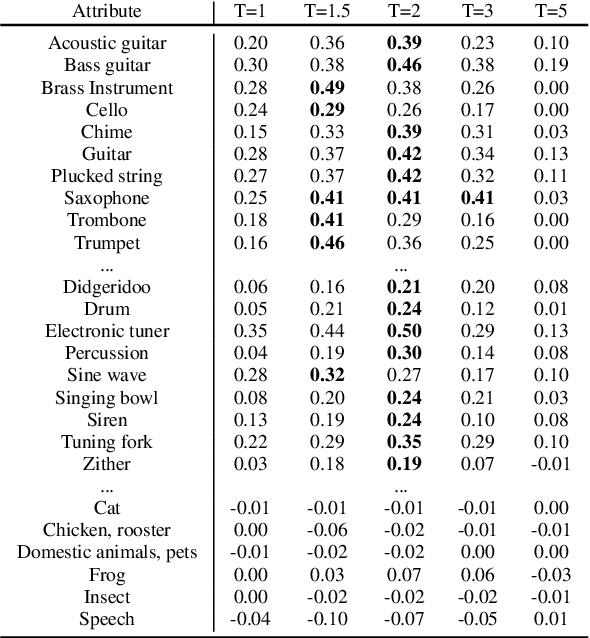

Generative Adversarial Networks (GANs) have achieved excellent audio synthesis quality in the last years. However, making them operable with semantically meaningful controls remains an open challenge. An obvious approach is to control the GAN by conditioning it on metadata contained in audio datasets. Unfortunately, audio datasets often lack the desired annotations, especially in the musical domain. A way to circumvent this lack of annotations is to generate them, for example, with an automatic audio-tagging system. The output probabilities of such systems (so-called "soft labels") carry rich information about the characteristics of the respective audios and can be used to distill the knowledge from a teacher model into a student model. In this work, we perform knowledge distillation from a large audio tagging system into an adversarial audio synthesizer that we call DarkGAN. Results show that DarkGAN can synthesize musical audio with acceptable quality and exhibits moderate attribute control even with out-of-distribution input conditioning. We release the code and provide audio examples on the accompanying website.
* 9 pages, 3 figures, 2 tables, accepted to ISMIR2021