 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDarkGAN: Exploiting Knowledge Distillation for Comprehensible Audio Synthesis with GANs
Paper and Code


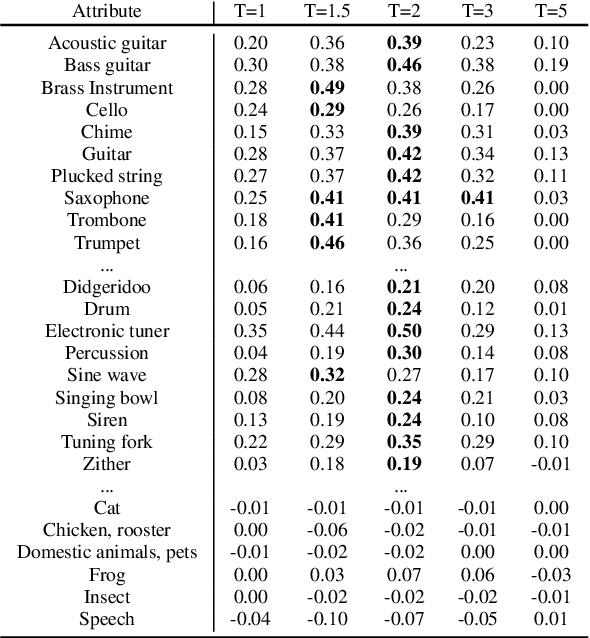

Generative Adversarial Networks (GANs) have achieved excellent audio synthesis quality in the last years. However, making them operable with semantically meaningful controls remains an open challenge. An obvious approach is to control the GAN by conditioning it on metadata contained in audio datasets. Unfortunately, audio datasets often lack the desired annotations, especially in the musical domain. A way to circumvent this lack of annotations is to generate them, for example, with an automatic audio-tagging system. The output probabilities of such systems (so-called "soft labels") carry rich information about the characteristics of the respective audios and can be used to distill the knowledge from a teacher model into a student model. In this work, we perform knowledge distillation from a large audio tagging system into an adversarial audio synthesizer that we call DarkGAN. Results show that DarkGAN can synthesize musical audio with acceptable quality and exhibits moderate attribute control even with out-of-distribution input conditioning. We release the code and provide audio examples on the accompanying website.