 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Timbre Transfer Via Mutual Information Guided Inpainting
Jan 03, 2026We study timbre transfer as an inference-time editing problem for music audio. Starting from a strong pre-trained latent diffusion model, we introduce a lightweight procedure that requires no additional training: (i) a dimension-wise noise injection that targets latent channels most informative of instrument identity, and (ii) an early-step clamping mechanism that re-imposes the input's melodic and rhythmic structure during reverse diffusion. The method operates directly on audio latents and is compatible with text/audio conditioning (e.g., CLAP). We discuss design choices,analyze trade-offs between timbral change and structural preservation, and show that simple inference-time controls can meaningfully steer pre-trained models for style-transfer use cases.
Perceptually Aligning Representations of Music via Noise-Augmented Autoencoders
Nov 10, 2025We argue that training autoencoders to reconstruct inputs from noised versions of their encodings, when combined with perceptual losses, yields encodings that are structured according to a perceptual hierarchy. We demonstrate the emergence of this hierarchical structure by showing that, after training an audio autoencoder in this manner, perceptually salient information is captured in coarser representation structures than with conventional training. Furthermore, we show that such perceptual hierarchies improve latent diffusion decoding in the context of estimating surprisal in music pitches and predicting EEG-brain responses to music listening. Pretrained weights are available on github.com/CPJKU/pa-audioic.
Music2Latent2: Audio Compression with Summary Embeddings and Autoregressive Decoding
Jan 29, 2025Efficiently compressing high-dimensional audio signals into a compact and informative latent space is crucial for various tasks, including generative modeling and music information retrieval (MIR). Existing audio autoencoders, however, often struggle to achieve high compression ratios while preserving audio fidelity and facilitating efficient downstream applications. We introduce Music2Latent2, a novel audio autoencoder that addresses these limitations by leveraging consistency models and a novel approach to representation learning based on unordered latent embeddings, which we call summary embeddings. Unlike conventional methods that encode local audio features into ordered sequences, Music2Latent2 compresses audio signals into sets of summary embeddings, where each embedding can capture distinct global features of the input sample. This enables to achieve higher reconstruction quality at the same compression ratio. To handle arbitrary audio lengths, Music2Latent2 employs an autoregressive consistency model trained on two consecutive audio chunks with causal masking, ensuring coherent reconstruction across segment boundaries. Additionally, we propose a novel two-step decoding procedure that leverages the denoising capabilities of consistency models to further refine the generated audio at no additional cost. Our experiments demonstrate that Music2Latent2 outperforms existing continuous audio autoencoders regarding audio quality and performance on downstream tasks. Music2Latent2 paves the way for new possibilities in audio compression.
Continuous Autoregressive Models with Noise Augmentation Avoid Error Accumulation
Nov 27, 2024Autoregressive models are typically applied to sequences of discrete tokens, but recent research indicates that generating sequences of continuous embeddings in an autoregressive manner is also feasible. However, such Continuous Autoregressive Models (CAMs) can suffer from a decline in generation quality over extended sequences due to error accumulation during inference. We introduce a novel method to address this issue by injecting random noise into the input embeddings during training. This procedure makes the model robust against varying error levels at inference. We further reduce error accumulation through an inference procedure that introduces low-level noise. Experiments on musical audio generation show that CAM substantially outperforms existing autoregressive and non-autoregressive approaches while preserving audio quality over extended sequences. This work paves the way for generating continuous embeddings in a purely autoregressive setting, opening new possibilities for real-time and interactive generative applications.
Improving Musical Accompaniment Co-creation via Diffusion Transformers
Oct 30, 2024Building upon Diff-A-Riff, a latent diffusion model for musical instrument accompaniment generation, we present a series of improvements targeting quality, diversity, inference speed, and text-driven control. First, we upgrade the underlying autoencoder to a stereo-capable model with superior fidelity and replace the latent U-Net with a Diffusion Transformer. Additionally, we refine text prompting by training a cross-modality predictive network to translate text-derived CLAP embeddings to audio-derived CLAP embeddings. Finally, we improve inference speed by training the latent model using a consistency framework, achieving competitive quality with fewer denoising steps. Our model is evaluated against the original Diff-A-Riff variant using objective metrics in ablation experiments, demonstrating promising advancements in all targeted areas. Sound examples are available at: https://sonycslparis.github.io/improved_dar/.
Music2Latent: Consistency Autoencoders for Latent Audio Compression
Aug 12, 2024



Efficient audio representations in a compressed continuous latent space are critical for generative audio modeling and Music Information Retrieval (MIR) tasks. However, some existing audio autoencoders have limitations, such as multi-stage training procedures, slow iterative sampling, or low reconstruction quality. We introduce Music2Latent, an audio autoencoder that overcomes these limitations by leveraging consistency models. Music2Latent encodes samples into a compressed continuous latent space in a single end-to-end training process while enabling high-fidelity single-step reconstruction. Key innovations include conditioning the consistency model on upsampled encoder outputs at all levels through cross connections, using frequency-wise self-attention to capture long-range frequency dependencies, and employing frequency-wise learned scaling to handle varying value distributions across frequencies at different noise levels. We demonstrate that Music2Latent outperforms existing continuous audio autoencoders in sound quality and reconstruction accuracy while achieving competitive performance on downstream MIR tasks using its latent representations. To our knowledge, this represents the first successful attempt at training an end-to-end consistency autoencoder model.
Diff-A-Riff: Musical Accompaniment Co-creation via Latent Diffusion Models
Jun 12, 2024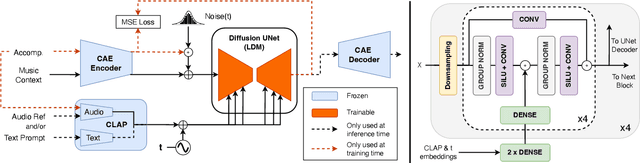
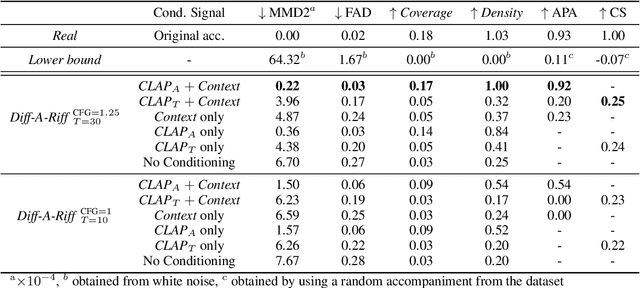
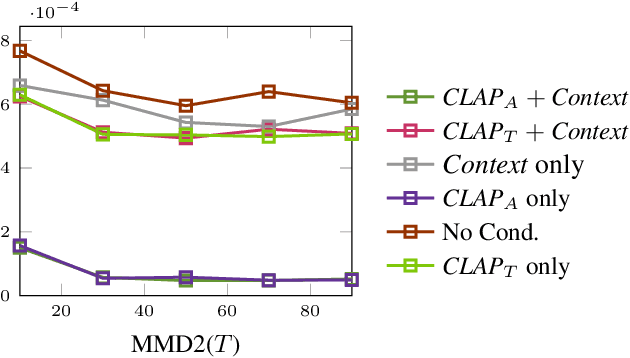
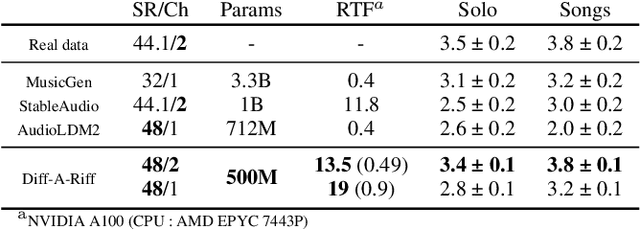
Recent advancements in deep generative models present new opportunities for music production but also pose challenges, such as high computational demands and limited audio quality. Moreover, current systems frequently rely solely on text input and typically focus on producing complete musical pieces, which is incompatible with existing workflows in music production. To address these issues, we introduce "Diff-A-Riff," a Latent Diffusion Model designed to generate high-quality instrumental accompaniments adaptable to any musical context. This model offers control through either audio references, text prompts, or both, and produces 48kHz pseudo-stereo audio while significantly reducing inference time and memory usage. We demonstrate the model's capabilities through objective metrics and subjective listening tests, with extensive examples available on the accompanying website: sonycslparis.github.io/diffariff-companion/
Bass Accompaniment Generation via Latent Diffusion
Feb 02, 2024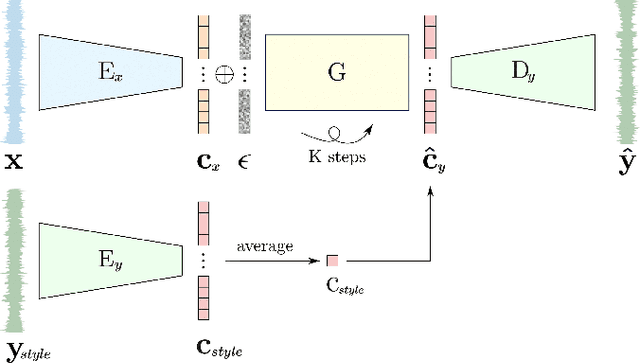
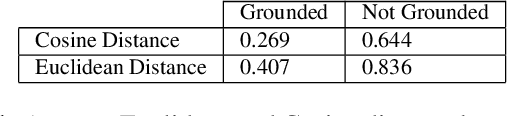
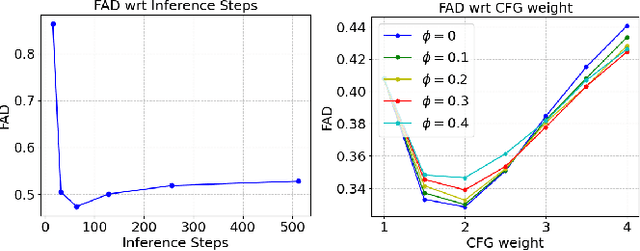
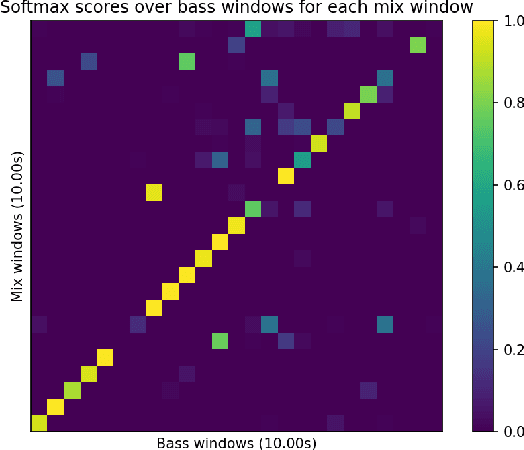
The ability to automatically generate music that appropriately matches an arbitrary input track is a challenging task. We present a novel controllable system for generating single stems to accompany musical mixes of arbitrary length. At the core of our method are audio autoencoders that efficiently compress audio waveform samples into invertible latent representations, and a conditional latent diffusion model that takes as input the latent encoding of a mix and generates the latent encoding of a corresponding stem. To provide control over the timbre of generated samples, we introduce a technique to ground the latent space to a user-provided reference style during diffusion sampling. For further improving audio quality, we adapt classifier-free guidance to avoid distortions at high guidance strengths when generating an unbounded latent space. We train our model on a dataset of pairs of mixes and matching bass stems. Quantitative experiments demonstrate that, given an input mix, the proposed system can generate basslines with user-specified timbres. Our controllable conditional audio generation framework represents a significant step forward in creating generative AI tools to assist musicians in music production.
Self-Supervised Music Source Separation Using Vector-Quantized Source Category Estimates
Nov 21, 2023Music source separation is focused on extracting distinct sonic elements from composite tracks. Historically, many methods have been grounded in supervised learning, necessitating labeled data, which is occasionally constrained in its diversity. More recent methods have delved into N-shot techniques that utilize one or more audio samples to aid in the separation. However, a challenge with some of these methods is the necessity for an audio query during inference, making them less suited for genres with varied timbres and effects. This paper offers a proof-of-concept for a self-supervised music source separation system that eliminates the need for audio queries at inference time. In the training phase, while it adopts a query-based approach, we introduce a modification by substituting the continuous embedding of query audios with Vector Quantized (VQ) representations. Trained end-to-end with up to N classes as determined by the VQ's codebook size, the model seeks to effectively categorise instrument classes. During inference, the input is partitioned into N sources, with some potentially left unutilized based on the mix's instrument makeup. This methodology suggests an alternative avenue for considering source separation across diverse music genres. We provide examples and additional results online.
Musika! Fast Infinite Waveform Music Generation
Aug 18, 2022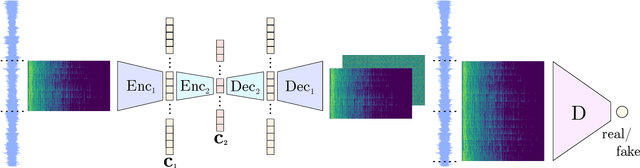
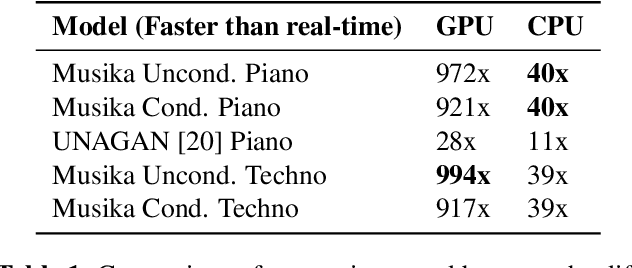
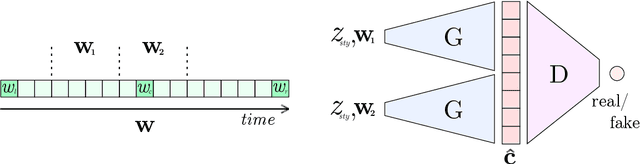

Fast and user-controllable music generation could enable novel ways of composing or performing music. However, state-of-the-art music generation systems require large amounts of data and computational resources for training, and are slow at inference. This makes them impractical for real-time interactive use. In this work, we introduce Musika, a music generation system that can be trained on hundreds of hours of music using a single consumer GPU, and that allows for much faster than real-time generation of music of arbitrary length on a consumer CPU. We achieve this by first learning a compact invertible representation of spectrogram magnitudes and phases with adversarial autoencoders, then training a Generative Adversarial Network (GAN) on this representation for a particular music domain. A latent coordinate system enables generating arbitrarily long sequences of excerpts in parallel, while a global context vector allows the music to remain stylistically coherent through time. We perform quantitative evaluations to assess the quality of the generated samples and showcase options for user control in piano and techno music generation. We release the source code and pretrained autoencoder weights at github.com/marcoppasini/musika, such that a GAN can be trained on a new music domain with a single GPU in a matter of hours.