 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMelGAN-VC: Voice Conversion and Audio Style Transfer on arbitrarily long samples using Spectrograms
Paper and Code
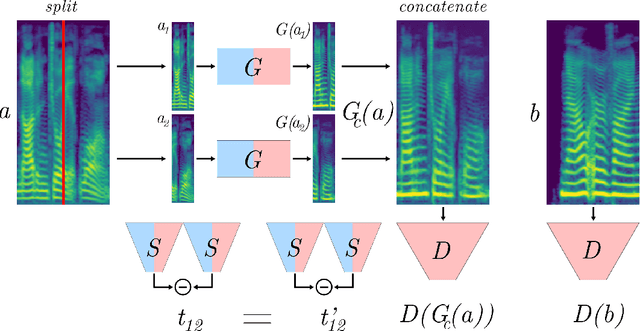
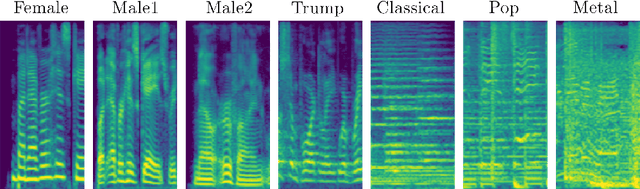
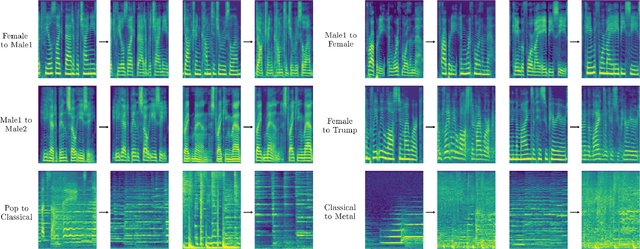
Traditional voice conversion methods rely on parallel recordings of multiple speakers pronouncing the same sentences. For real-world applications however, parallel data is rarely available. We propose MelGAN-VC, a voice conversion method that relies on non-parallel speech data and is able to convert audio signals of arbitrary length from a source voice to a target voice. We firstly compute spectrograms from waveform data and then perform a domain translation using a Generative Adversarial Network (GAN) architecture. An additional siamese network helps preserving speech information in the translation process, without sacrificing the ability to flexibly model the style of the target speaker. We test our framework with a dataset of clean speech recordings, as well as with a collection of noisy real-world speech examples. Finally, we apply the same method to perform music style transfer, translating arbitrarily long music samples from one genre to another, and showing that our framework is flexible and can be used for audio manipulation applications different from voice conversion.