 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring System Adaptations For Minimum Latency Real-Time Piano Transcription
Sep 09, 2025Advances in neural network design and the availability of large-scale labeled datasets have driven major improvements in piano transcription. Existing approaches target either offline applications, with no restrictions on computational demands, or online transcription, with delays of 128-320 ms. However, most real-time musical applications require latencies below 30 ms. In this work, we investigate whether and how the current state-of-the-art online transcription model can be adapted for real-time piano transcription. Specifically, we eliminate all non-causal processing, and reduce computational load through shared computations across core model components and variations in model size. Additionally, we explore different pre- and postprocessing strategies, and related label encoding schemes, and discuss their suitability for real-time transcription. Evaluating the adaptions on the MAESTRO dataset, we find a drop in transcription accuracy due to strictly causal processing as well as a tradeoff between the preprocessing latency and prediction accuracy. We release our system as a baseline to support researchers in designing models towards minimum latency real-time transcription.
Effective Pre-Training of Audio Transformers for Sound Event Detection
Sep 14, 2024


We propose a pre-training pipeline for audio spectrogram transformers for frame-level sound event detection tasks. On top of common pre-training steps, we add a meticulously designed training routine on AudioSet frame-level annotations. This includes a balanced sampler, aggressive data augmentation, and ensemble knowledge distillation. For five transformers, we obtain a substantial performance improvement over previously available checkpoints both on AudioSet frame-level predictions and on frame-level sound event detection downstream tasks, confirming our pipeline's effectiveness. We publish the resulting checkpoints that researchers can directly fine-tune to build high-performance models for sound event detection tasks.
Beat this! Accurate beat tracking without DBN postprocessing
Jul 31, 2024



We propose a system for tracking beats and downbeats with two objectives: generality across a diverse music range, and high accuracy. We achieve generality by training on multiple datasets -- including solo instrument recordings, pieces with time signature changes, and classical music with high tempo variations -- and by removing the commonly used Dynamic Bayesian Network (DBN) postprocessing, which introduces constraints on the meter and tempo. For high accuracy, among other improvements, we develop a loss function tolerant to small time shifts of annotations, and an architecture alternating convolutions with transformers either over frequency or time. Our system surpasses the current state of the art in F1 score despite using no DBN. However, it can still fail, especially for difficult and underrepresented genres, and performs worse on continuity metrics, so we publish our model, code, and preprocessed datasets, and invite others to beat this.
Learning General Audio Representations with Large-Scale Training of Patchout Audio Transformers
Nov 25, 2022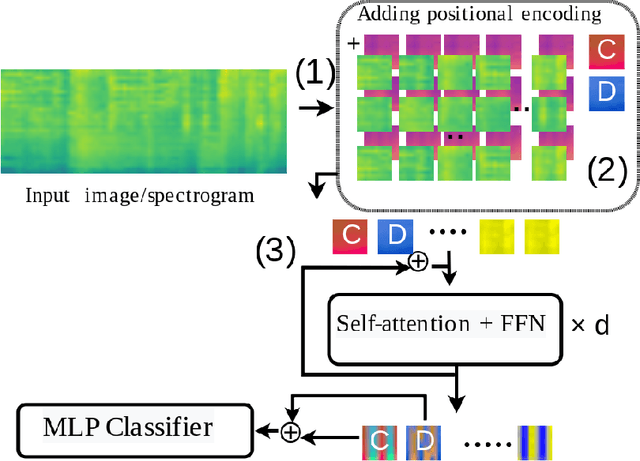


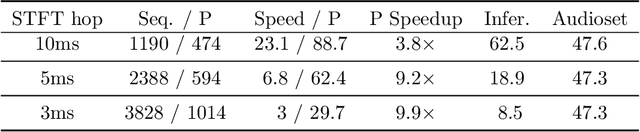
The success of supervised deep learning methods is largely due to their ability to learn relevant features from raw data. Deep Neural Networks (DNNs) trained on large-scale datasets are capable of capturing a diverse set of features, and learning a representation that can generalize onto unseen tasks and datasets that are from the same domain. Hence, these models can be used as powerful feature extractors, in combination with shallower models as classifiers, for smaller tasks and datasets where the amount of training data is insufficient for learning an end-to-end model from scratch. During the past years, Convolutional Neural Networks (CNNs) have largely been the method of choice for audio processing. However, recently attention-based transformer models have demonstrated great potential in supervised settings, outperforming CNNs. In this work, we investigate the use of audio transformers trained on large-scale datasets to learn general-purpose representations. We study how the different setups in these audio transformers affect the quality of their embeddings. We experiment with the models' time resolution, extracted embedding level, and receptive fields in order to see how they affect performance on a variety of tasks and datasets, following the HEAR 2021 NeurIPS challenge evaluation setup. Our results show that representations extracted by audio transformers outperform CNN representations. Furthermore, we will show that transformers trained on Audioset can be extremely effective representation extractors for a wide range of downstream tasks.
Musika! Fast Infinite Waveform Music Generation
Aug 18, 2022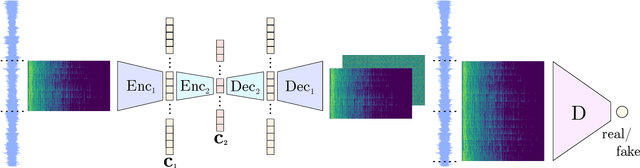
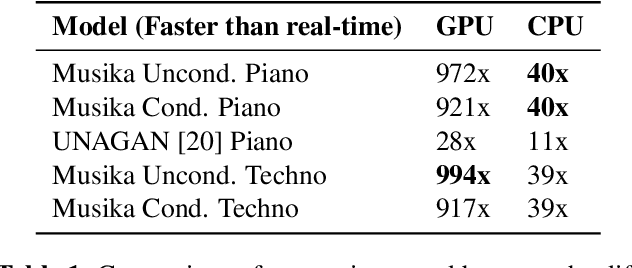
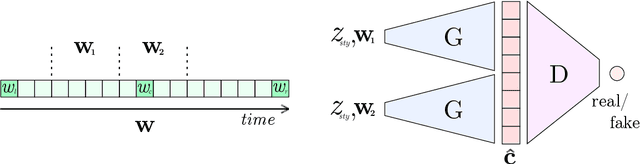

Fast and user-controllable music generation could enable novel ways of composing or performing music. However, state-of-the-art music generation systems require large amounts of data and computational resources for training, and are slow at inference. This makes them impractical for real-time interactive use. In this work, we introduce Musika, a music generation system that can be trained on hundreds of hours of music using a single consumer GPU, and that allows for much faster than real-time generation of music of arbitrary length on a consumer CPU. We achieve this by first learning a compact invertible representation of spectrogram magnitudes and phases with adversarial autoencoders, then training a Generative Adversarial Network (GAN) on this representation for a particular music domain. A latent coordinate system enables generating arbitrarily long sequences of excerpts in parallel, while a global context vector allows the music to remain stylistically coherent through time. We perform quantitative evaluations to assess the quality of the generated samples and showcase options for user control in piano and techno music generation. We release the source code and pretrained autoencoder weights at github.com/marcoppasini/musika, such that a GAN can be trained on a new music domain with a single GPU in a matter of hours.
EfficientLEAF: A Faster LEarnable Audio Frontend of Questionable Use
Jul 12, 2022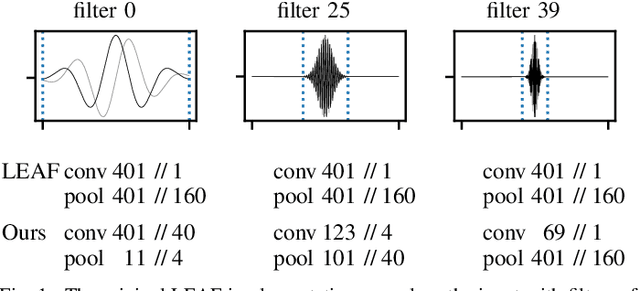
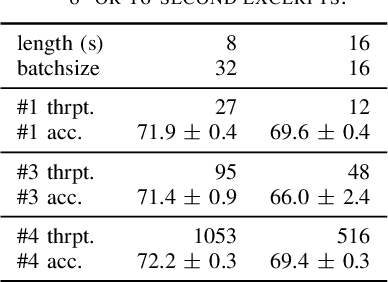
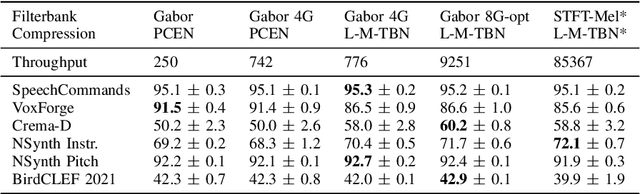
In audio classification, differentiable auditory filterbanks with few parameters cover the middle ground between hard-coded spectrograms and raw audio. LEAF (arXiv:2101.08596), a Gabor-based filterbank combined with Per-Channel Energy Normalization (PCEN), has shown promising results, but is computationally expensive. With inhomogeneous convolution kernel sizes and strides, and by replacing PCEN with better parallelizable operations, we can reach similar results more efficiently. In experiments on six audio classification tasks, our frontend matches the accuracy of LEAF at 3% of the cost, but both fail to consistently outperform a fixed mel filterbank. The quest for learnable audio frontends is not solved.
Efficient Training of Audio Transformers with Patchout
Oct 29, 2021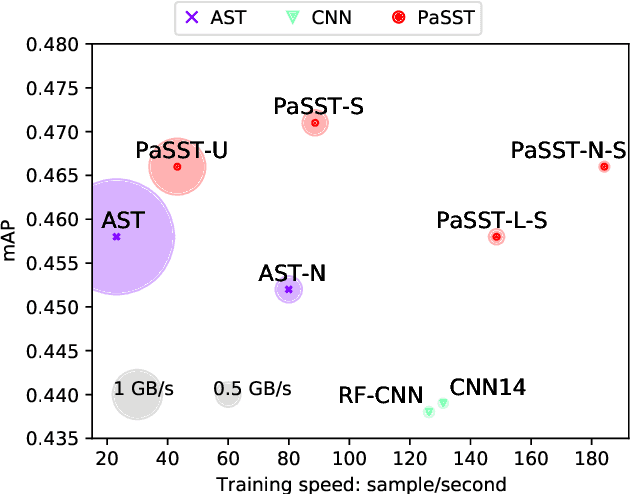
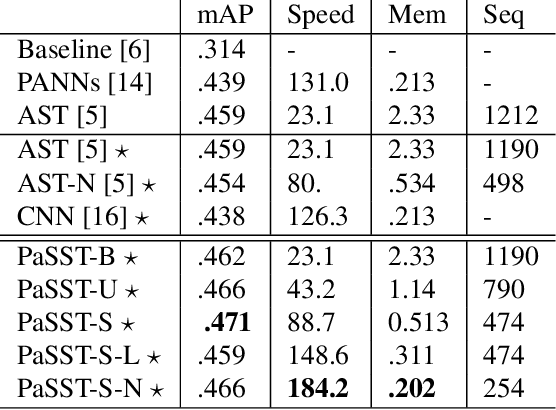
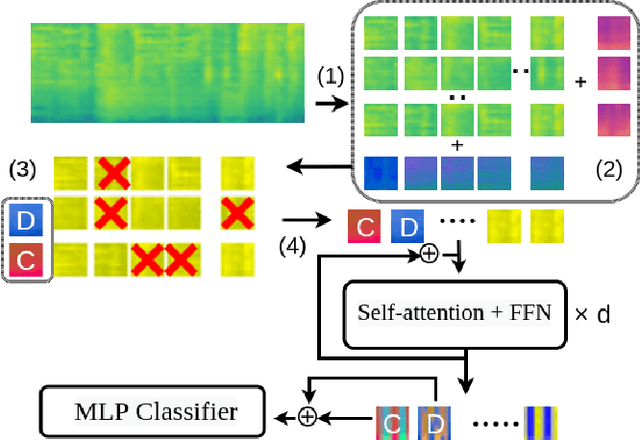

The great success of transformer-based models in natural language processing (NLP) has led to various attempts at adapting these architectures to other domains such as vision and audio. Recent work has shown that transformers can outperform Convolutional Neural Networks (CNNs) on vision and audio tasks. However, one of the main shortcomings of transformer models, compared to the well-established CNNs, is the computational complexity. Compute and memory complexity grow quadratically with the input length. Therefore, there has been extensive work on optimizing transformers, but often at the cost of lower predictive performance. In this work, we propose a novel method to optimize and regularize transformers on audio spectrograms. The proposed models achieve a new state-of-the-art performance on Audioset and can be trained on a single consumer-grade GPU. Furthermore, we propose a transformer model that outperforms CNNs in terms of both performance and training speed.
Over-Parameterization and Generalization in Audio Classification
Jul 19, 2021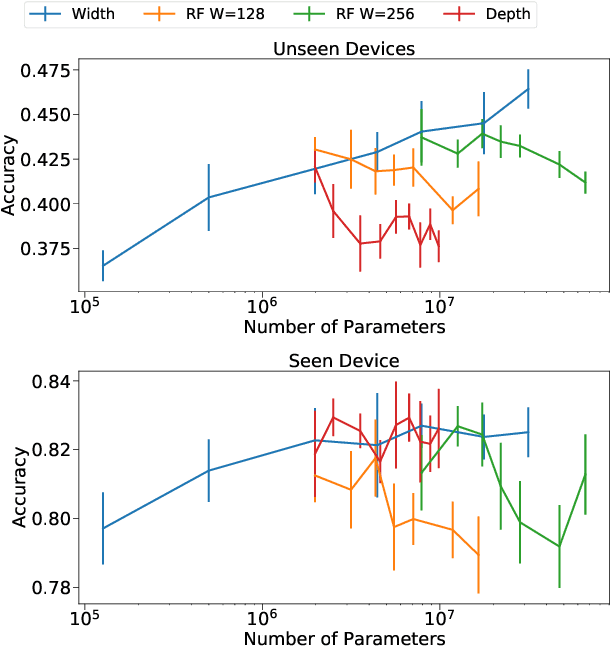
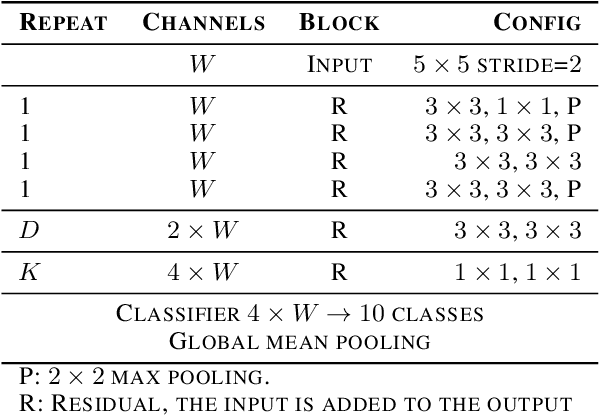
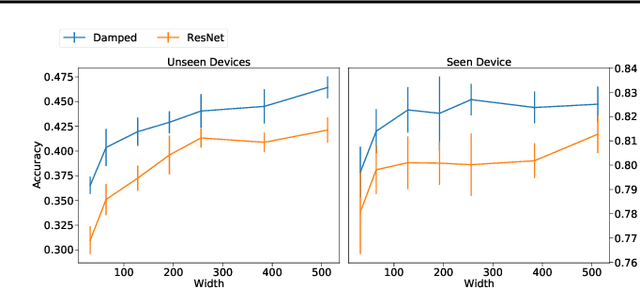
Convolutional Neural Networks (CNNs) have been dominating classification tasks in various domains, such as machine vision, machine listening, and natural language processing. In machine listening, while generally exhibiting very good generalization capabilities, CNNs are sensitive to the specific audio recording device used, which has been recognized as a substantial problem in the acoustic scene classification (DCASE) community. In this study, we investigate the relationship between over-parameterization of acoustic scene classification models, and their resulting generalization abilities. Specifically, we test scaling CNNs in width and depth, under different conditions. Our results indicate that increasing width improves generalization to unseen devices, even without an increase in the number of parameters.
Deep Learning for Audio Signal Processing
May 25, 2019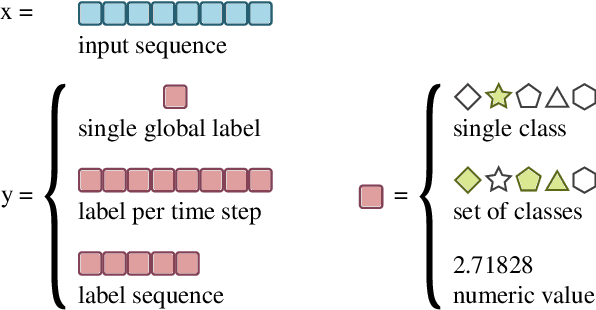
Given the recent surge in developments of deep learning, this article provides a review of the state-of-the-art deep learning techniques for audio signal processing. Speech, music, and environmental sound processing are considered side-by-side, in order to point out similarities and differences between the domains, highlighting general methods, problems, key references, and potential for cross-fertilization between areas. The dominant feature representations (in particular, log-mel spectra and raw waveform) and deep learning models are reviewed, including convolutional neural networks, variants of the long short-term memory architecture, as well as more audio-specific neural network models. Subsequently, prominent deep learning application areas are covered, i.e. audio recognition (automatic speech recognition, music information retrieval, environmental sound detection, localization and tracking) and synthesis and transformation (source separation, audio enhancement, generative models for speech, sound, and music synthesis). Finally, key issues and future questions regarding deep learning applied to audio signal processing are identified.
* 15 pages, 2 pdf figures
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016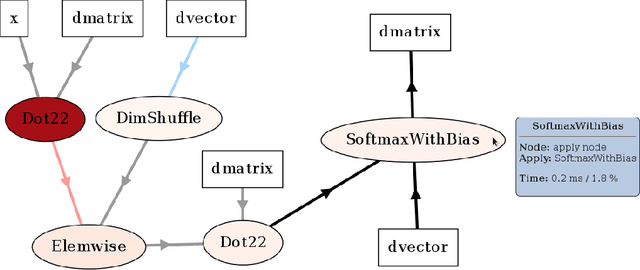
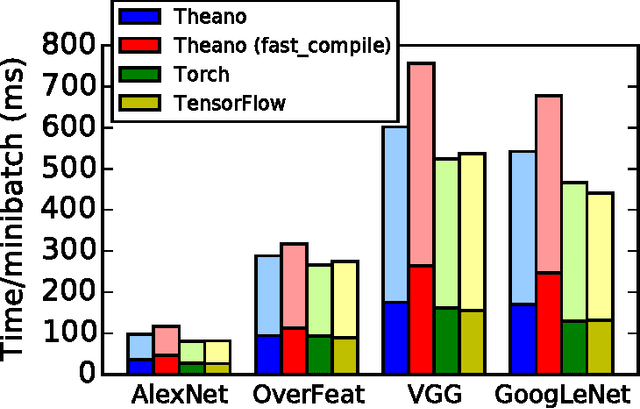
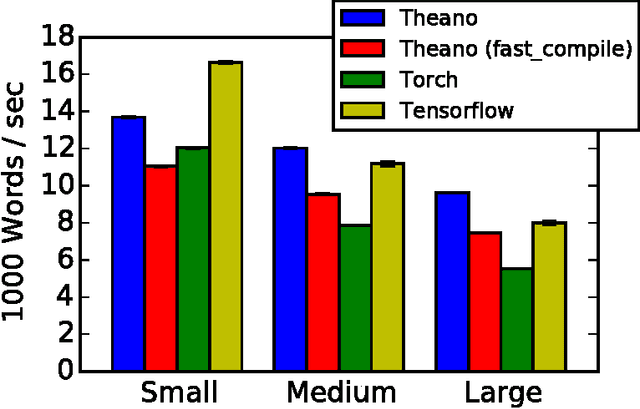
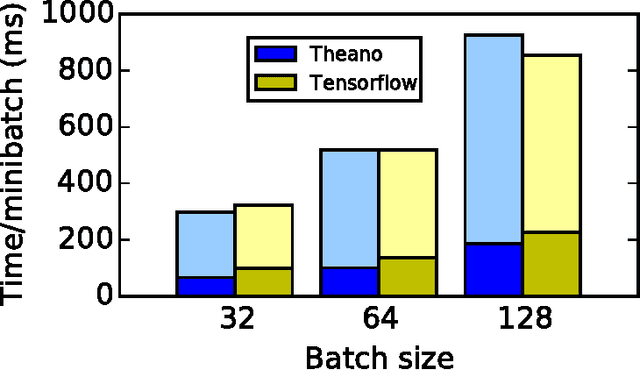
Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.