 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacet-Level Tracing of Evidence Uncertainty and Hallucination in RAG
Apr 10, 2026Retrieval-Augmented Generation (RAG) aims to reduce hallucination by grounding answers in retrieved evidence, yet hallucinated answers remain common even when relevant documents are available. Existing evaluations focus on answer-level or passage-level accuracy, offering limited insight into how evidence is used during generation. In this work, we introduce a facet-level diagnostics framework for QA that decomposes each input question into atomic reasoning facets. For each facet, we assess evidence sufficiency and grounding using a structured Facet x Chunk matrix that combines retrieval relevance with natural language inference-based faithfulness scores. To diagnose evidence usage, we analyze three controlled inference modes: Strict RAG, which enforces exclusive reliance on retrieved evidence; Soft RAG, which allows integration of retrieved evidence and parametric knowledge; and LLM-only generation without retrieval. Comparing these modes enables thorough analysis of retrieval-generation misalignment, defined as cases where relevant evidence is retrieved but not correctly integrated during generation. Across medical QA and HotpotQA, we evaluate three open-source and closed-source LLMs (GPT, Gemini, and LLaMA), providing interpretable diagnostics that reveal recurring facet-level failure modes, including evidence absence, evidence misalignment, and prior-driven overrides. Our results demonstrate that hallucinations in RAG systems are driven less by retrieval accuracy and more by how retrieved evidence is integrated during generation, with facet-level analysis exposing systematic evidence override and misalignment patterns that remain hidden under answer-level evaluation.
Robust Harmful Meme Detection under Missing Modalities via Shared Representation Learning
Feb 01, 2026Internet memes are powerful tools for communication, capable of spreading political, psychological, and sociocultural ideas. However, they can be harmful and can be used to disseminate hate toward targeted individuals or groups. Although previous studies have focused on designing new detection methods, these often rely on modal-complete data, such as text and images. In real-world settings, however, modalities like text may be missing due to issues like poor OCR quality, making existing methods sensitive to missing information and leading to performance deterioration. To address this gap, in this paper, we present the first-of-its-kind work to comprehensively investigate the behavior of harmful meme detection methods in the presence of modal-incomplete data. Specifically, we propose a new baseline method that learns a shared representation for multiple modalities by projecting them independently. These shared representations can then be leveraged when data is modal-incomplete. Experimental results on two benchmark datasets demonstrate that our method outperforms existing approaches when text is missing. Moreover, these results suggest that our method allows for better integration of visual features, reducing dependence on text and improving robustness in scenarios where textual information is missing. Our work represents a significant step forward in enabling the real-world application of harmful meme detection, particularly in situations where a modality is absent.
Unlabeled Debiasing in Downstream Tasks via Class-wise Low Variance Regularization
Sep 29, 2024Language models frequently inherit societal biases from their training data. Numerous techniques have been proposed to mitigate these biases during both the pre-training and fine-tuning stages. However, fine-tuning a pre-trained debiased language model on a downstream task can reintroduce biases into the model. Additionally, existing debiasing methods for downstream tasks either (i) require labels of protected attributes (e.g., age, race, or political views) that are often not available or (ii) rely on indicators of bias, which restricts their applicability to gender debiasing since they rely on gender-specific words. To address this, we introduce a novel debiasing regularization technique based on the class-wise variance of embeddings. Crucially, our method does not require attribute labels and targets any attribute, thus addressing the shortcomings of existing debiasing methods. Our experiments on encoder language models and three datasets demonstrate that our method outperforms existing strong debiasing baselines that rely on target attribute labels while maintaining performance on the target task.
The Importance of Cognitive Biases in the Recommendation Ecosystem
Aug 22, 2024Cognitive biases have been studied in psychology, sociology, and behavioral economics for decades. Traditionally, they have been considered a negative human trait that leads to inferior decision-making, reinforcement of stereotypes, or can be exploited to manipulate consumers, respectively. We argue that cognitive biases also manifest in different parts of the recommendation ecosystem and at different stages of the recommendation process. More importantly, we contest this traditional detrimental perspective on cognitive biases and claim that certain cognitive biases can be beneficial when accounted for by recommender systems. Concretely, we provide empirical evidence that biases such as feature-positive effect, Ikea effect, and cultural homophily can be observed in various components of the recommendation pipeline, including input data (such as ratings or side information), recommendation algorithm or model (and consequently recommended items), and user interactions with the system. In three small experiments covering recruitment and entertainment domains, we study the pervasiveness of the aforementioned biases. We ultimately advocate for a prejudice-free consideration of cognitive biases to improve user and item models as well as recommendation algorithms.
Effective Controllable Bias Mitigation for Classification and Retrieval using Gate Adapters
Jan 29, 2024



Bias mitigation of Language Models has been the topic of many studies with a recent focus on learning separate modules like adapters for on-demand debiasing. Besides optimizing for a modularized debiased model, it is often critical in practice to control the degree of bias reduction at inference time, e.g., in order to tune for a desired performance-fairness trade-off in search results or to control the strength of debiasing in classification tasks. In this paper, we introduce Controllable Gate Adapter (ConGater), a novel modular gating mechanism with adjustable sensitivity parameters, which allows for a gradual transition from the biased state of the model to the fully debiased version at inference time. We demonstrate ConGater performance by (1) conducting adversarial debiasing experiments with three different models on three classification tasks with four protected attributes, and (2) reducing the bias of search results through fairness list-wise regularization to enable adjusting a trade-off between performance and fairness metrics. Our experiments on the classification tasks show that compared to baselines of the same caliber, ConGater can maintain higher task performance while containing less information regarding the attributes. Our results on the retrieval task show that the fully debiased ConGater can achieve the same fairness performance while maintaining more than twice as high task performance than recent strong baselines. Overall, besides strong performance ConGater enables the continuous transitioning between biased and debiased states of models, enhancing personalization of use and interpretability through controllability.
ScaLearn: Simple and Highly Parameter-Efficient Task Transfer by Learning to Scale
Oct 02, 2023



Multi-task learning (MTL) has shown considerable practical benefits, particularly when using pre-trained language models (PLMs). While this is commonly achieved by simultaneously learning $n$ tasks under a joint optimization procedure, recent methods such as AdapterFusion structure the problem into two distinct stages: (i) task learning, where knowledge specific to a task is encapsulated within sets of parameters (\eg adapters), and (ii) transfer, where this already learned knowledge is leveraged for a target task. This separation of concerns provides numerous benefits, such as promoting reusability, and addressing cases involving data privacy and societal concerns; on the flip side, current two-stage MTL methods come with the cost of introducing a substantial number of additional parameters. In this work, we address this issue by leveraging the usefulness of linearly scaling the output representations of source adapters for transfer learning. We introduce ScaLearn, a simple and highly parameter-efficient two-stage MTL method that capitalizes on the knowledge of the source tasks by learning a minimal set of scaling parameters that enable effective knowledge transfer to a target task. Our experiments on three benchmarks (GLUE, SuperGLUE, and HumSet) show that our ScaLearn, in addition to facilitating the benefits of two-stage MTL, consistently outperforms strong baselines with only a small number of transfer parameters - roughly 0.35% of those of AdapterFusion. Remarkably, we observe that ScaLearn maintains its strong abilities even when further reducing parameters through uniform scaling and layer-sharing, achieving similarly competitive results with only $8$ transfer parameters for each target task. Our proposed approach thus demonstrates the power of simple scaling as a promise for more efficient task transfer.
Domain Information Control at Inference Time for Acoustic Scene Classification
Jun 13, 2023Domain shift is considered a challenge in machine learning as it causes significant degradation of model performance. In the Acoustic Scene Classification task (ASC), domain shift is mainly caused by different recording devices. Several studies have already targeted domain generalization to improve the performance of ASC models on unseen domains, such as new devices. Recently, the Controllable Gate Adapter ConGater has been proposed in Natural Language Processing to address the biased training data problem. ConGater allows controlling the debiasing process at inference time. ConGater's main advantage is the continuous and selective debiasing of a trained model, during inference. In this work, we adapt ConGater to the audio spectrogram transformer for an acoustic scene classification task. We show that ConGater can be used to selectively adapt the learned representations to be invariant to device domain shifts such as recording devices. Our analysis shows that ConGater can progressively remove device information from the learned representations and improve the model generalization, especially under domain shift conditions (e.g. unseen devices). We show that information removal can be extended to both device and location domain. Finally, we demonstrate ConGater's ability to enhance specific device performance without further training.
Learning General Audio Representations with Large-Scale Training of Patchout Audio Transformers
Nov 25, 2022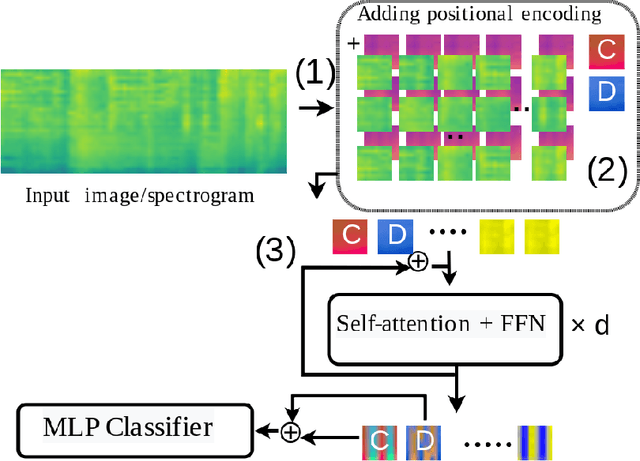


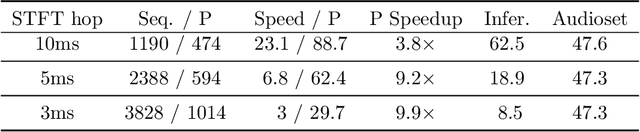
The success of supervised deep learning methods is largely due to their ability to learn relevant features from raw data. Deep Neural Networks (DNNs) trained on large-scale datasets are capable of capturing a diverse set of features, and learning a representation that can generalize onto unseen tasks and datasets that are from the same domain. Hence, these models can be used as powerful feature extractors, in combination with shallower models as classifiers, for smaller tasks and datasets where the amount of training data is insufficient for learning an end-to-end model from scratch. During the past years, Convolutional Neural Networks (CNNs) have largely been the method of choice for audio processing. However, recently attention-based transformer models have demonstrated great potential in supervised settings, outperforming CNNs. In this work, we investigate the use of audio transformers trained on large-scale datasets to learn general-purpose representations. We study how the different setups in these audio transformers affect the quality of their embeddings. We experiment with the models' time resolution, extracted embedding level, and receptive fields in order to see how they affect performance on a variety of tasks and datasets, following the HEAR 2021 NeurIPS challenge evaluation setup. Our results show that representations extracted by audio transformers outperform CNN representations. Furthermore, we will show that transformers trained on Audioset can be extremely effective representation extractors for a wide range of downstream tasks.