 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment Any Text: A Universal Approach for Robust, Efficient and Adaptable Sentence Segmentation
Jun 24, 2024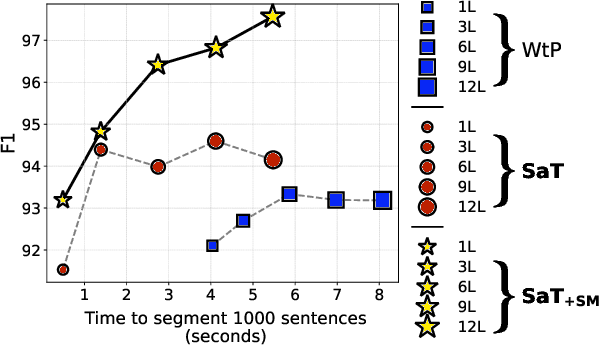
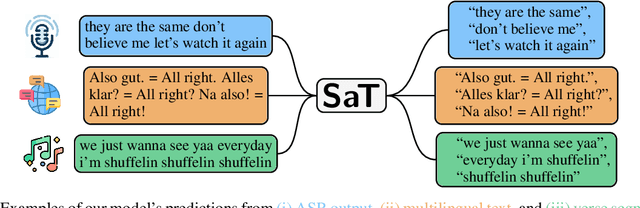
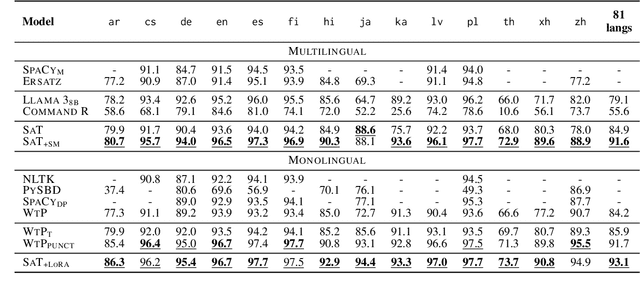
Segmenting text into sentences plays an early and crucial role in many NLP systems. This is commonly achieved by using rule-based or statistical methods relying on lexical features such as punctuation. Although some recent works no longer exclusively rely on punctuation, we find that no prior method achieves all of (i) robustness to missing punctuation, (ii) effective adaptability to new domains, and (iii) high efficiency. We introduce a new model - Segment any Text (SaT) - to solve this problem. To enhance robustness, we propose a new pretraining scheme that ensures less reliance on punctuation. To address adaptability, we introduce an extra stage of parameter-efficient fine-tuning, establishing state-of-the-art performance in distinct domains such as verses from lyrics and legal documents. Along the way, we introduce architectural modifications that result in a threefold gain in speed over the previous state of the art and solve spurious reliance on context far in the future. Finally, we introduce a variant of our model with fine-tuning on a diverse, multilingual mixture of sentence-segmented data, acting as a drop-in replacement and enhancement for existing segmentation tools. Overall, our contributions provide a universal approach for segmenting any text. Our method outperforms all baselines - including strong LLMs - across 8 corpora spanning diverse domains and languages, especially in practically relevant situations where text is poorly formatted. Our models and code, including documentation, are available at https://huggingface.co/segment-any-text under the MIT license.
What the Weight?! A Unified Framework for Zero-Shot Knowledge Composition
Jan 25, 2024The knowledge encapsulated in a model is the core factor determining its final performance on downstream tasks. Much research in NLP has focused on efficient methods for storing and adapting different types of knowledge, e.g., in dedicated modularized structures, and on how to effectively combine these, e.g., by learning additional parameters. However, given the many possible options, a thorough understanding of the mechanisms involved in these compositions is missing, and hence it remains unclear which strategies to utilize. To address this research gap, we propose a novel framework for zero-shot module composition, which encompasses existing and some novel variations for selecting, weighting, and combining parameter modules under a single unified notion. Focusing on the scenario of domain knowledge and adapter layers, our framework provides a systematic unification of concepts, allowing us to conduct the first comprehensive benchmarking study of various zero-shot knowledge composition strategies. In particular, we test two module combination methods and five selection and weighting strategies for their effectiveness and efficiency in an extensive experimental setup. Our results highlight the efficacy of ensembling but also hint at the power of simple though often-ignored weighting methods. Further in-depth analyses allow us to understand the role of weighting vs. top-k selection, and show that, to a certain extent, the performance of adapter composition can even be predicted.
ScaLearn: Simple and Highly Parameter-Efficient Task Transfer by Learning to Scale
Oct 02, 2023



Multi-task learning (MTL) has shown considerable practical benefits, particularly when using pre-trained language models (PLMs). While this is commonly achieved by simultaneously learning $n$ tasks under a joint optimization procedure, recent methods such as AdapterFusion structure the problem into two distinct stages: (i) task learning, where knowledge specific to a task is encapsulated within sets of parameters (\eg adapters), and (ii) transfer, where this already learned knowledge is leveraged for a target task. This separation of concerns provides numerous benefits, such as promoting reusability, and addressing cases involving data privacy and societal concerns; on the flip side, current two-stage MTL methods come with the cost of introducing a substantial number of additional parameters. In this work, we address this issue by leveraging the usefulness of linearly scaling the output representations of source adapters for transfer learning. We introduce ScaLearn, a simple and highly parameter-efficient two-stage MTL method that capitalizes on the knowledge of the source tasks by learning a minimal set of scaling parameters that enable effective knowledge transfer to a target task. Our experiments on three benchmarks (GLUE, SuperGLUE, and HumSet) show that our ScaLearn, in addition to facilitating the benefits of two-stage MTL, consistently outperforms strong baselines with only a small number of transfer parameters - roughly 0.35% of those of AdapterFusion. Remarkably, we observe that ScaLearn maintains its strong abilities even when further reducing parameters through uniform scaling and layer-sharing, achieving similarly competitive results with only $8$ transfer parameters for each target task. Our proposed approach thus demonstrates the power of simple scaling as a promise for more efficient task transfer.