 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Autoguidance for Item-Side Fairness in Diffusion Recommender Systems
Feb 16, 2026Diffusion recommender systems achieve strong recommendation accuracy but often suffer from popularity bias, resulting in unequal item exposure. To address this shortcoming, we introduce A2G-DiffRec, a diffusion recommender that incorporates adaptive autoguidance, where the main model is guided by a less-trained version of itself. Instead of using a fixed guidance weight, A2G-DiffRec learns to adaptively weigh the outputs of the main and weak models during training, supervised by a popularity regularization that promotes balanced exposure across items with different popularity levels. Experimental results on the MovieLens-1M, Foursquare-Tokyo, and Music4All-Onion datasets show that A2G-DiffRec is effective in enhancing item-side fairness at a marginal cost of accuracy reduction compared to existing guided diffusion recommenders and other non-diffusion baselines.
The Importance of Cognitive Biases in the Recommendation Ecosystem
Aug 22, 2024Cognitive biases have been studied in psychology, sociology, and behavioral economics for decades. Traditionally, they have been considered a negative human trait that leads to inferior decision-making, reinforcement of stereotypes, or can be exploited to manipulate consumers, respectively. We argue that cognitive biases also manifest in different parts of the recommendation ecosystem and at different stages of the recommendation process. More importantly, we contest this traditional detrimental perspective on cognitive biases and claim that certain cognitive biases can be beneficial when accounted for by recommender systems. Concretely, we provide empirical evidence that biases such as feature-positive effect, Ikea effect, and cultural homophily can be observed in various components of the recommendation pipeline, including input data (such as ratings or side information), recommendation algorithm or model (and consequently recommended items), and user interactions with the system. In three small experiments covering recruitment and entertainment domains, we study the pervasiveness of the aforementioned biases. We ultimately advocate for a prejudice-free consideration of cognitive biases to improve user and item models as well as recommendation algorithms.
Oh, Behave! Country Representation Dynamics Created by Feedback Loops in Music Recommender Systems
Aug 21, 2024



Recent work suggests that music recommender systems are prone to disproportionally frequent recommendations of music from countries more prominently represented in the training data, notably the US. However, it remains unclear to what extent feedback loops in music recommendation influence the dynamics of such imbalance. In this work, we investigate the dynamics of representation of local (i.e., country-specific) and US-produced music in user profiles and recommendations. To this end, we conduct a feedback loop simulation study using the standardized LFM-2b dataset. The results suggest that most of the investigated recommendation models decrease the proportion of music from local artists in their recommendations. Furthermore, we find that models preserving average proportions of US and local music do not necessarily provide country-calibrated recommendations. We also look into popularity calibration and, surprisingly, find that the most popularity-calibrated model in our study (ItemKNN) provides the least country-calibrated recommendations. In addition, users from less represented countries (e.g., Finland) are, in the long term, most affected by the under-representation of their local music in recommendations.
Parameter-efficient Modularised Bias Mitigation via AdapterFusion
Feb 13, 2023



Large pre-trained language models contain societal biases and carry along these biases to downstream tasks. Current in-processing bias mitigation approaches (like adversarial training) impose debiasing by updating a model's parameters, effectively transferring the model to a new, irreversible debiased state. In this work, we propose a novel approach to develop stand-alone debiasing functionalities separate from the model, which can be integrated into the model on-demand, while keeping the core model untouched. Drawing from the concept of AdapterFusion in multi-task learning, we introduce DAM (Debiasing with Adapter Modules) - a debiasing approach to first encapsulate arbitrary bias mitigation functionalities into separate adapters, and then add them to the model on-demand in order to deliver fairness qualities. We conduct a large set of experiments on three classification tasks with gender, race, and age as protected attributes. Our results show that DAM improves or maintains the effectiveness of bias mitigation, avoids catastrophic forgetting in a multi-attribute scenario, and maintains on-par task performance, while granting parameter-efficiency and easy switching between the original and debiased models.
Unlearning Protected User Attributes in Recommendations with Adversarial Training
Jun 09, 2022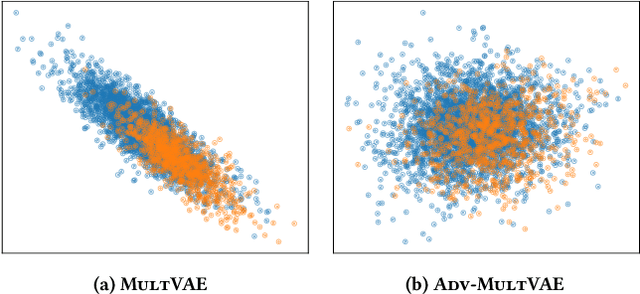
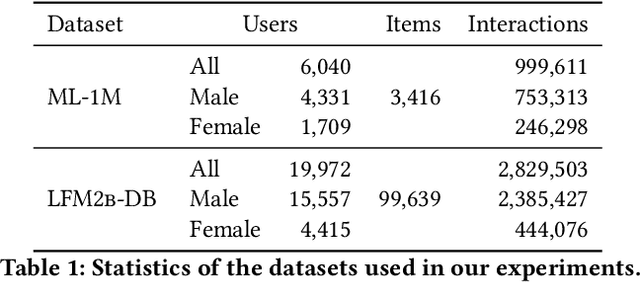
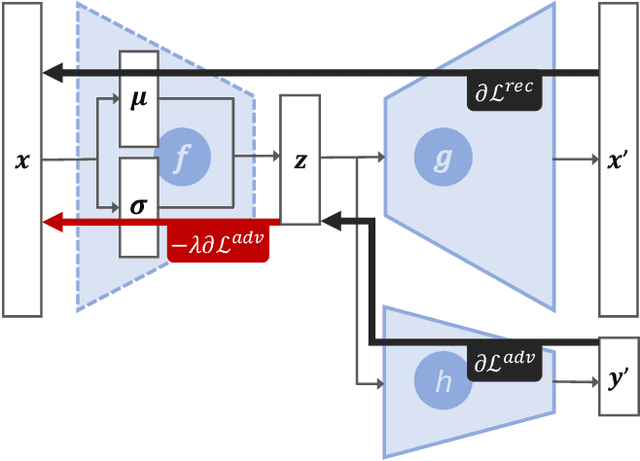
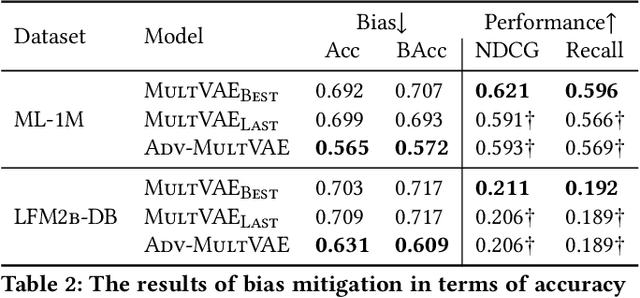
Collaborative filtering algorithms capture underlying consumption patterns, including the ones specific to particular demographics or protected information of users, e.g. gender, race, and location. These encoded biases can influence the decision of a recommendation system (RS) towards further separation of the contents provided to various demographic subgroups, and raise privacy concerns regarding the disclosure of users' protected attributes. In this work, we investigate the possibility and challenges of removing specific protected information of users from the learned interaction representations of a RS algorithm, while maintaining its effectiveness. Specifically, we incorporate adversarial training into the state-of-the-art MultVAE architecture, resulting in a novel model, Adversarial Variational Auto-Encoder with Multinomial Likelihood (Adv-MultVAE), which aims at removing the implicit information of protected attributes while preserving recommendation performance. We conduct experiments on the MovieLens-1M and LFM-2b-DemoBias datasets, and evaluate the effectiveness of the bias mitigation method based on the inability of external attackers in revealing the users' gender information from the model. Comparing with baseline MultVAE, the results show that Adv-MultVAE, with marginal deterioration in performance (w.r.t. NDCG and recall), largely mitigates inherent biases in the model on both datasets.
Grep-BiasIR: A Dataset for Investigating Gender Representation-Bias in Information Retrieval Results
Jan 19, 2022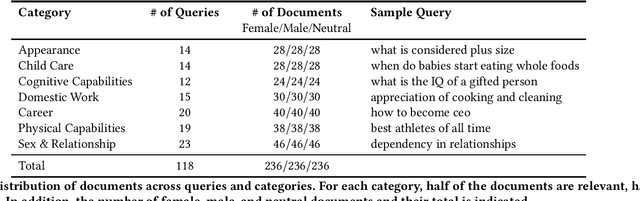

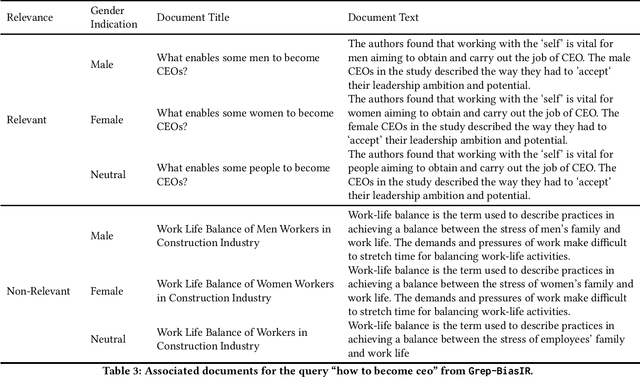
The results of information retrieval (IR) systems on specific queries can reflect the existing societal biases and stereotypes, which will be further propagated and straightened through interactions of the uses with the systems. We introduce Grep-BiasIR, a novel thoroughly-audited dataset which aim to facilitate the studies of gender bias in the retrieved results of IR systems. The Grep-BiasIR dataset offers 105 bias-sensitive neutral search queries, where each query is accompanied with a set of relevant and non-relevant documents with contents indicating various genders. The dataset is available at https://github.com/KlaraKrieg/GrepBiasIR.
Analyzing Item Popularity Bias of Music Recommender Systems: Are Different Genders Equally Affected?
Aug 16, 2021

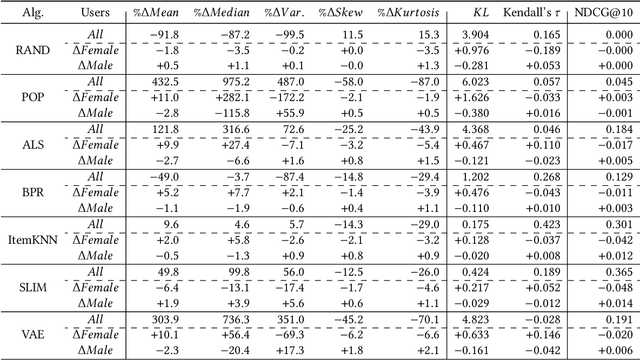
Several studies have identified discrepancies between the popularity of items in user profiles and the corresponding recommendation lists. Such behavior, which concerns a variety of recommendation algorithms, is referred to as popularity bias. Existing work predominantly adopts simple statistical measures, such as the difference of mean or median popularity, to quantify popularity bias. Moreover, it does so irrespective of user characteristics other than the inclination to popular content. In this work, in contrast, we propose to investigate popularity differences (between the user profile and recommendation list) in terms of median, a variety of statistical moments, as well as similarity measures that consider the entire popularity distributions (Kullback-Leibler divergence and Kendall's tau rank-order correlation). This results in a more detailed picture of the characteristics of popularity bias. Furthermore, we investigate whether such algorithmic popularity bias affects users of different genders in the same way. We focus on music recommendation and conduct experiments on the recently released standardized LFM-2b dataset, containing listening profiles of Last.fm users. We investigate the algorithmic popularity bias of seven common recommendation algorithms (five collaborative filtering and two baselines). Our experiments show that (1) the studied metrics provide novel insights into popularity bias in comparison with only using average differences, (2) algorithms less inclined towards popularity bias amplification do not necessarily perform worse in terms of utility (NDCG), (3) the majority of the investigated recommenders intensify the popularity bias of the female users.
A Modern Perspective on Query Likelihood with Deep Generative Retrieval Models
Jun 25, 2021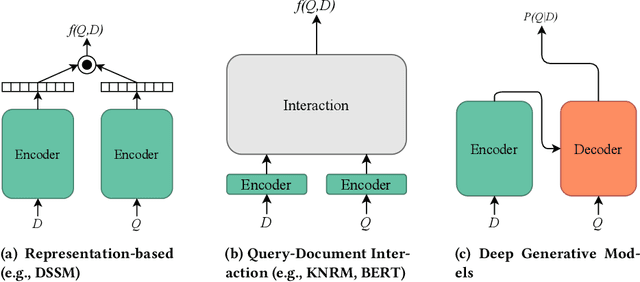
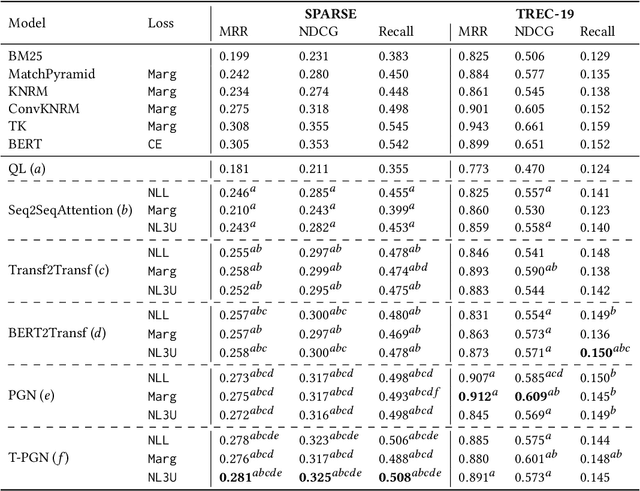
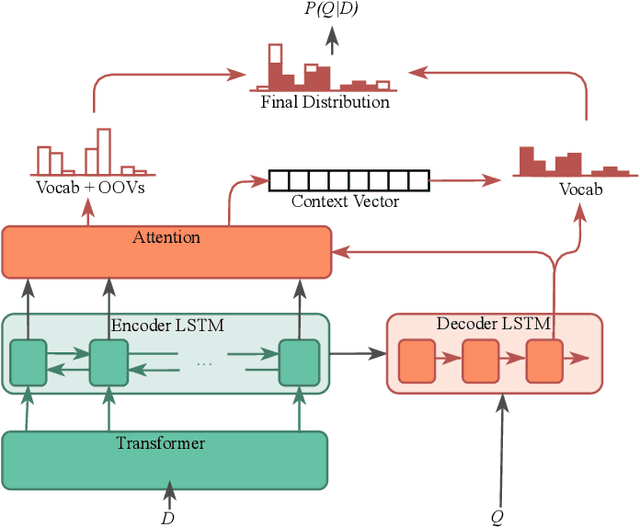

Existing neural ranking models follow the text matching paradigm, where document-to-query relevance is estimated through predicting the matching score. Drawing from the rich literature of classical generative retrieval models, we introduce and formalize the paradigm of deep generative retrieval models defined via the cumulative probabilities of generating query terms. This paradigm offers a grounded probabilistic view on relevance estimation while still enabling the use of modern neural architectures. In contrast to the matching paradigm, the probabilistic nature of generative rankers readily offers a fine-grained measure of uncertainty. We adopt several current neural generative models in our framework and introduce a novel generative ranker (T-PGN), which combines the encoding capacity of Transformers with the Pointer Generator Network model. We conduct an extensive set of evaluation experiments on passage retrieval, leveraging the MS MARCO Passage Re-ranking and TREC Deep Learning 2019 Passage Re-ranking collections. Our results show the significantly higher performance of the T-PGN model when compared with other generative models. Lastly, we demonstrate that exploiting the uncertainty information of deep generative rankers opens new perspectives to query/collection understanding, and significantly improves the cut-off prediction task.
Not All Relevance Scores are Equal: Efficient Uncertainty and Calibration Modeling for Deep Retrieval Models
May 10, 2021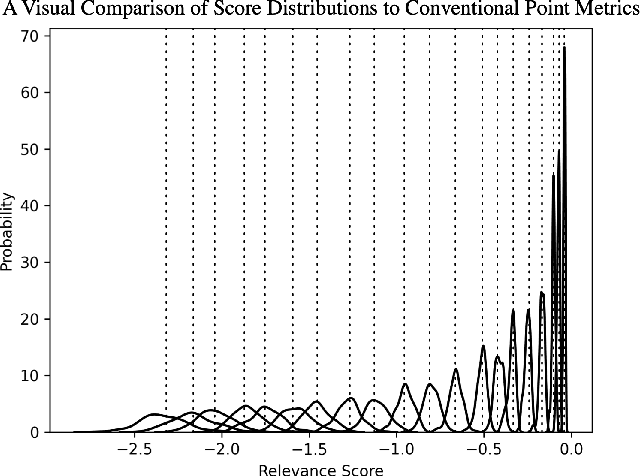
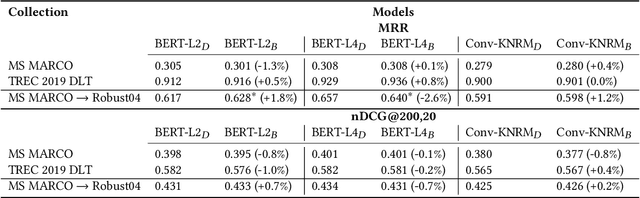
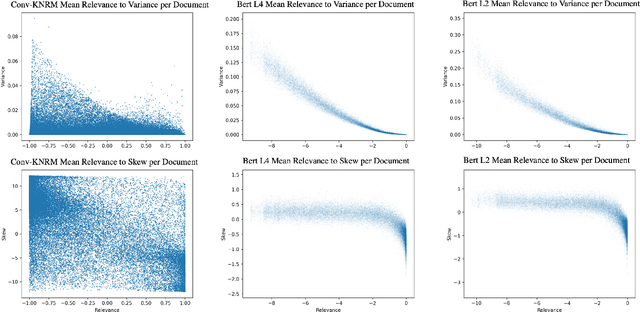
In any ranking system, the retrieval model outputs a single score for a document based on its belief on how relevant it is to a given search query. While retrieval models have continued to improve with the introduction of increasingly complex architectures, few works have investigated a retrieval model's belief in the score beyond the scope of a single value. We argue that capturing the model's uncertainty with respect to its own scoring of a document is a critical aspect of retrieval that allows for greater use of current models across new document distributions, collections, or even improving effectiveness for down-stream tasks. In this paper, we address this problem via an efficient Bayesian framework for retrieval models which captures the model's belief in the relevance score through a stochastic process while adding only negligible computational overhead. We evaluate this belief via a ranking based calibration metric showing that our approximate Bayesian framework significantly improves a retrieval model's ranking effectiveness through a risk aware reranking as well as its confidence calibration. Lastly, we demonstrate that this additional uncertainty information is actionable and reliable on down-stream tasks represented via cutoff prediction.
TripClick: The Log Files of a Large Health Web Search Engine
Mar 14, 2021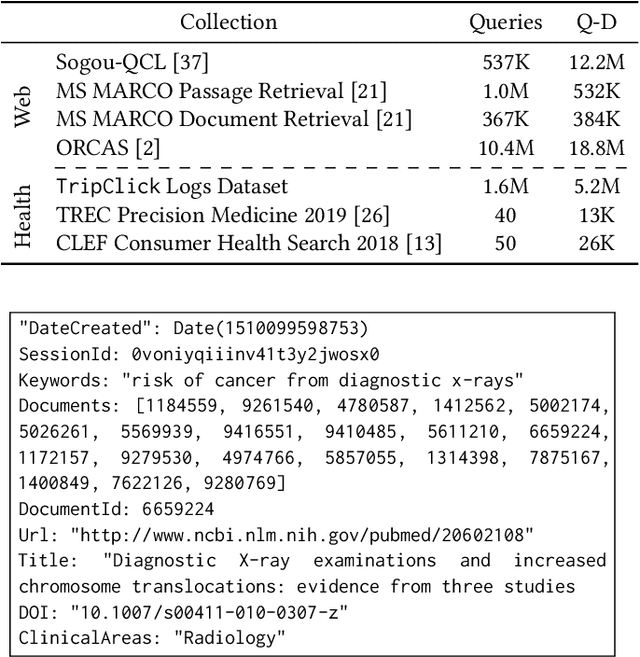
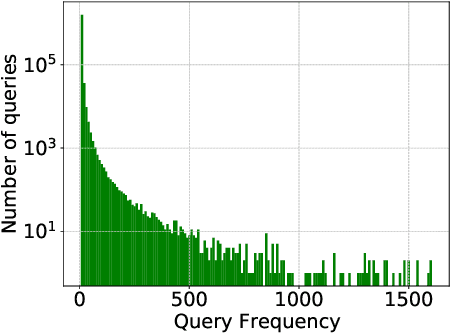
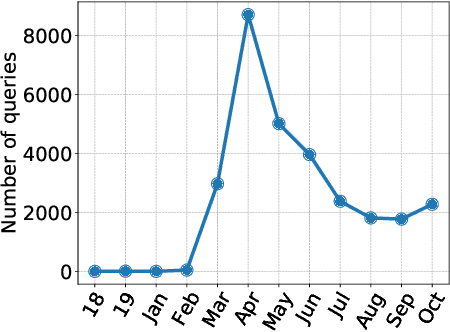

Click logs are valuable resources for a variety of information retrieval (IR) tasks. This includes query understanding/analysis, as well as learning effective IR models particularly when the models require large amounts of training data. We release a large-scale domain-specific dataset of click logs, obtained from user interactions of the Trip Database health web search engine. Our click log dataset comprises approximately 5.2 million user interactions collected between 2013 and 2020. We use this dataset to create a standard IR evaluation benchmark -- TripClick -- with around 700,000 unique free-text queries and 1.3 million pairs of query-document relevance signals, whose relevance is estimated by two click-through models. As such, the collection is one of the few datasets offering the necessary data richness and scale to train neural IR models with a large amount of parameters, and notably the first in the health domain. Using TripClick, we conduct experiments to evaluate a variety of IR models, showing the benefits of exploiting this data to train neural architectures. In particular, the evaluation results show that the best performing neural IR model significantly improves the performance by a large margin relative to classical IR models, especially for more frequent queries.