 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlearning Protected User Attributes in Recommendations with Adversarial Training
Paper and Code
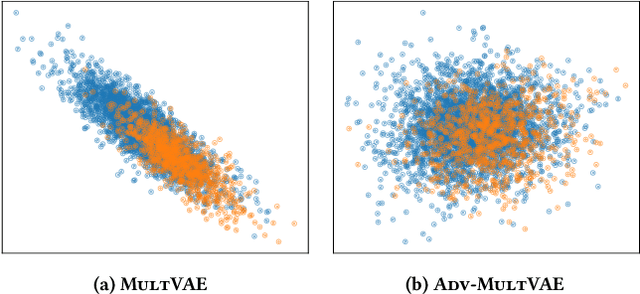
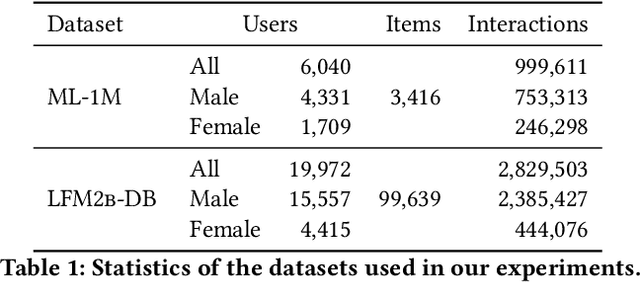
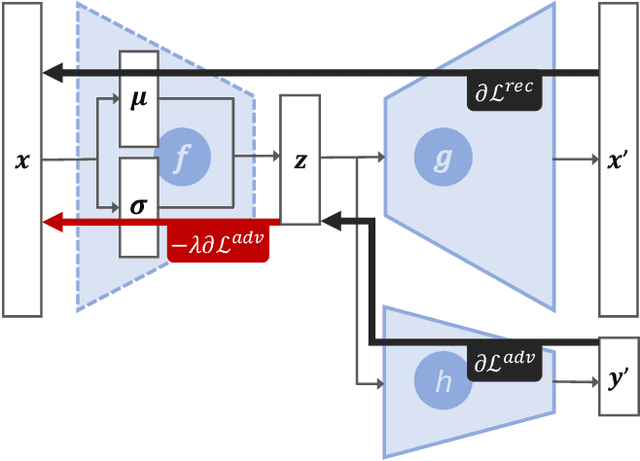
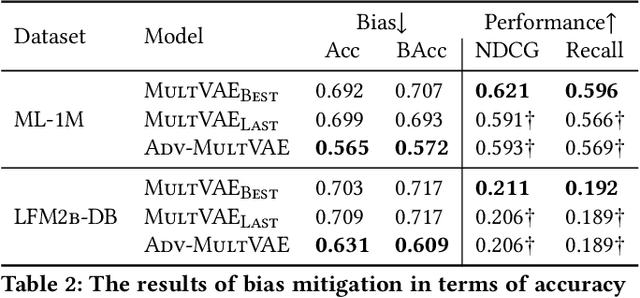
Collaborative filtering algorithms capture underlying consumption patterns, including the ones specific to particular demographics or protected information of users, e.g. gender, race, and location. These encoded biases can influence the decision of a recommendation system (RS) towards further separation of the contents provided to various demographic subgroups, and raise privacy concerns regarding the disclosure of users' protected attributes. In this work, we investigate the possibility and challenges of removing specific protected information of users from the learned interaction representations of a RS algorithm, while maintaining its effectiveness. Specifically, we incorporate adversarial training into the state-of-the-art MultVAE architecture, resulting in a novel model, Adversarial Variational Auto-Encoder with Multinomial Likelihood (Adv-MultVAE), which aims at removing the implicit information of protected attributes while preserving recommendation performance. We conduct experiments on the MovieLens-1M and LFM-2b-DemoBias datasets, and evaluate the effectiveness of the bias mitigation method based on the inability of external attackers in revealing the users' gender information from the model. Comparing with baseline MultVAE, the results show that Adv-MultVAE, with marginal deterioration in performance (w.r.t. NDCG and recall), largely mitigates inherent biases in the model on both datasets.