 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntermediate Languages Matter: Formal Languages and LLMs affect Neurosymbolic Reasoning
Sep 04, 2025Large language models (LLMs) achieve astonishing results on a wide range of tasks. However, their formal reasoning ability still lags behind. A promising approach is Neurosymbolic LLM reasoning. It works by using LLMs as translators from natural to formal languages and symbolic solvers for deriving correct results. Still, the contributing factors to the success of Neurosymbolic LLM reasoning remain unclear. This paper demonstrates that one previously overlooked factor is the choice of the formal language. We introduce the intermediate language challenge: selecting a suitable formal language for neurosymbolic reasoning. By comparing four formal languages across three datasets and seven LLMs, we show that the choice of formal language affects both syntactic and semantic reasoning capabilities. We also discuss the varying effects across different LLMs.
Making LLMs Reason? The Intermediate Language Problem in Neurosymbolic Approaches
Feb 24, 2025



Logical reasoning tasks manifest themselves as a challenge to Large Language Models (LLMs). Neurosymbolic approaches use LLMs to translate logical reasoning problems formulated in natural language into a formal intermediate language. Subsequently, the usage of symbolic reasoners yields reliable solving thereof. However, LLMs often fail in translation due to poorly chosen intermediate languages. We introduce the intermediate language problem, which is the problem of choosing a suitable formal language representation for neurosymbolic approaches. Theoretically, we argue that its origins lie in the inability of LLMs to distinguish syntax from semantics and the relative independence of the problem from its representation. We showcase its existence experimentally by contrasting two intermediate languages, Answer Set Programming and the Python Knowledge Engine. In addition, we demonstrate the effects of varying degrees of supplementary context information. Our results show a maximum difference in overall-accuracy of 53.20% and 49.26% in execution-accuracy. When using the GPT4o-mini LLM we beat the state-of-the-art in overall-accuracy on the ProntoQA dataset by 21.20% and by 50.50% on the ProofWriter dataset.
Unlearning Protected User Attributes in Recommendations with Adversarial Training
Jun 09, 2022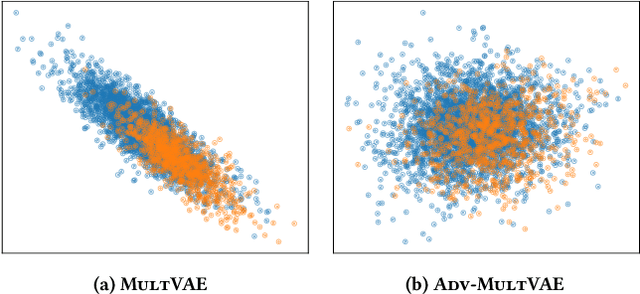
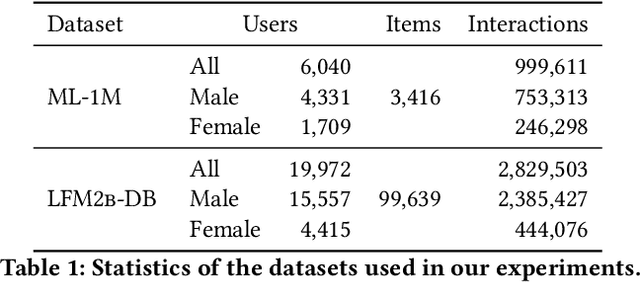
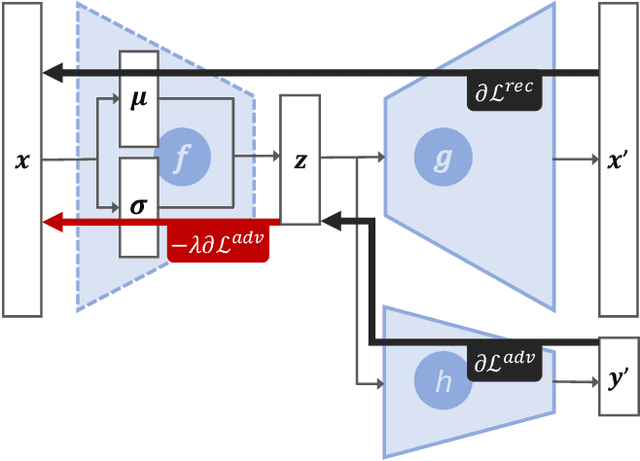
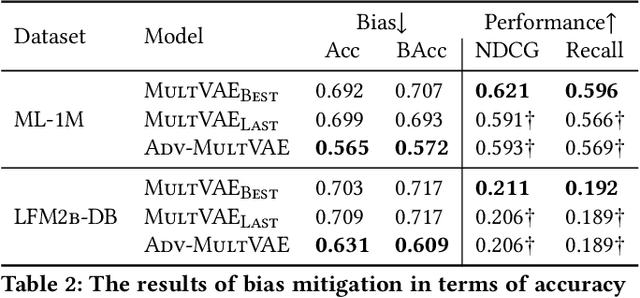
Collaborative filtering algorithms capture underlying consumption patterns, including the ones specific to particular demographics or protected information of users, e.g. gender, race, and location. These encoded biases can influence the decision of a recommendation system (RS) towards further separation of the contents provided to various demographic subgroups, and raise privacy concerns regarding the disclosure of users' protected attributes. In this work, we investigate the possibility and challenges of removing specific protected information of users from the learned interaction representations of a RS algorithm, while maintaining its effectiveness. Specifically, we incorporate adversarial training into the state-of-the-art MultVAE architecture, resulting in a novel model, Adversarial Variational Auto-Encoder with Multinomial Likelihood (Adv-MultVAE), which aims at removing the implicit information of protected attributes while preserving recommendation performance. We conduct experiments on the MovieLens-1M and LFM-2b-DemoBias datasets, and evaluate the effectiveness of the bias mitigation method based on the inability of external attackers in revealing the users' gender information from the model. Comparing with baseline MultVAE, the results show that Adv-MultVAE, with marginal deterioration in performance (w.r.t. NDCG and recall), largely mitigates inherent biases in the model on both datasets.