 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Unlearning of Multiple Protected User Attributes From Variational Autoencoder Recommenders Using Adversarial Training
Oct 28, 2024In widely used neural network-based collaborative filtering models, users' history logs are encoded into latent embeddings that represent the users' preferences. In this setting, the models are capable of mapping users' protected attributes (e.g., gender or ethnicity) from these user embeddings even without explicit access to them, resulting in models that may treat specific demographic user groups unfairly and raise privacy issues. While prior work has approached the removal of a single protected attribute of a user at a time, multiple attributes might come into play in real-world scenarios. In the work at hand, we present AdvXMultVAE which aims to unlearn multiple protected attributes (exemplified by gender and age) simultaneously to improve fairness across demographic user groups. For this purpose, we couple a variational autoencoder (VAE) architecture with adversarial training (AdvMultVAE) to support simultaneous removal of the users' protected attributes with continuous and/or categorical values. Our experiments on two datasets, LFM-2b-100k and Ml-1m, from the music and movie domains, respectively, show that our approach can yield better results than its singular removal counterparts (based on AdvMultVAE) in effectively mitigating demographic biases whilst improving the anonymity of latent embeddings.
A Multimodal Single-Branch Embedding Network for Recommendation in Cold-Start and Missing Modality Scenarios
Sep 26, 2024Most recommender systems adopt collaborative filtering (CF) and provide recommendations based on past collective interactions. Therefore, the performance of CF algorithms degrades when few or no interactions are available, a scenario referred to as cold-start. To address this issue, previous work relies on models leveraging both collaborative data and side information on the users or items. Similar to multimodal learning, these models aim at combining collaborative and content representations in a shared embedding space. In this work we propose a novel technique for multimodal recommendation, relying on a multimodal Single-Branch embedding network for Recommendation (SiBraR). Leveraging weight-sharing, SiBraR encodes interaction data as well as multimodal side information using the same single-branch embedding network on different modalities. This makes SiBraR effective in scenarios of missing modality, including cold start. Our extensive experiments on large-scale recommendation datasets from three different recommendation domains (music, movie, and e-commerce) and providing multimodal content information (audio, text, image, labels, and interactions) show that SiBraR significantly outperforms CF as well as state-of-the-art content-based RSs in cold-start scenarios, and is competitive in warm scenarios. We show that SiBraR's recommendations are accurate in missing modality scenarios, and that the model is able to map different modalities to the same region of the shared embedding space, hence reducing the modality gap.
Unlearning Protected User Attributes in Recommendations with Adversarial Training
Jun 09, 2022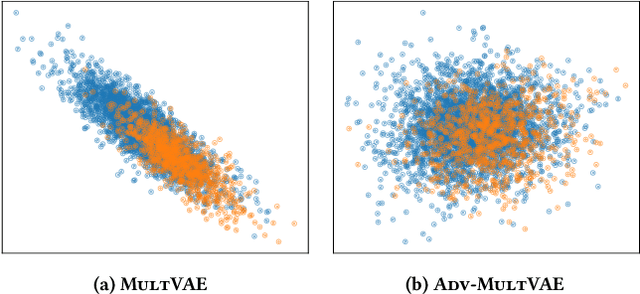
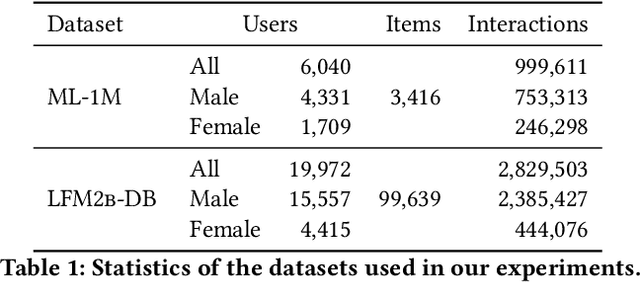
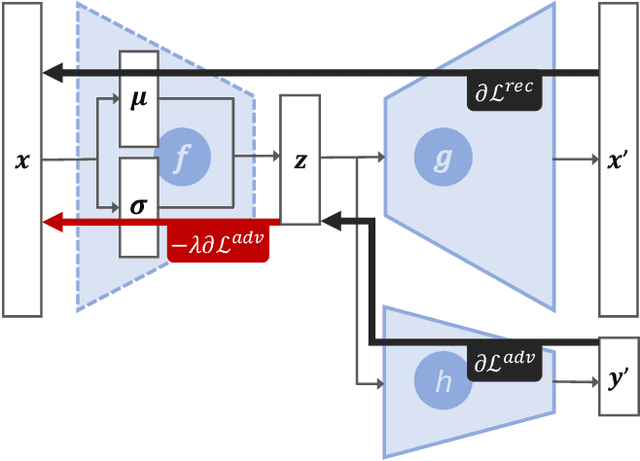
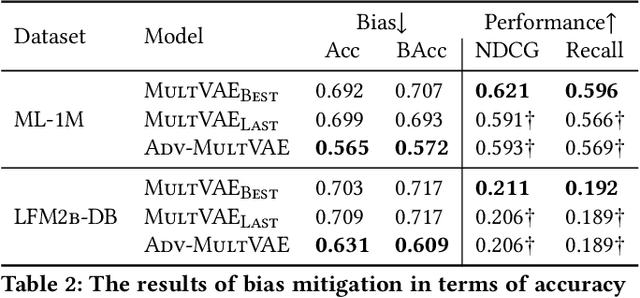
Collaborative filtering algorithms capture underlying consumption patterns, including the ones specific to particular demographics or protected information of users, e.g. gender, race, and location. These encoded biases can influence the decision of a recommendation system (RS) towards further separation of the contents provided to various demographic subgroups, and raise privacy concerns regarding the disclosure of users' protected attributes. In this work, we investigate the possibility and challenges of removing specific protected information of users from the learned interaction representations of a RS algorithm, while maintaining its effectiveness. Specifically, we incorporate adversarial training into the state-of-the-art MultVAE architecture, resulting in a novel model, Adversarial Variational Auto-Encoder with Multinomial Likelihood (Adv-MultVAE), which aims at removing the implicit information of protected attributes while preserving recommendation performance. We conduct experiments on the MovieLens-1M and LFM-2b-DemoBias datasets, and evaluate the effectiveness of the bias mitigation method based on the inability of external attackers in revealing the users' gender information from the model. Comparing with baseline MultVAE, the results show that Adv-MultVAE, with marginal deterioration in performance (w.r.t. NDCG and recall), largely mitigates inherent biases in the model on both datasets.