 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTripClick: The Log Files of a Large Health Web Search Engine
Paper and Code
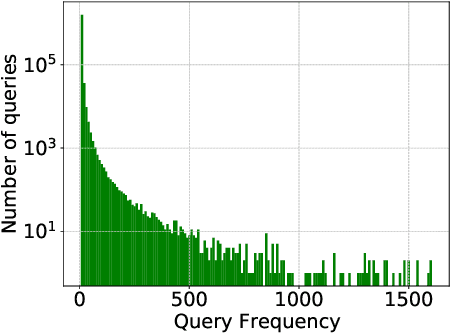
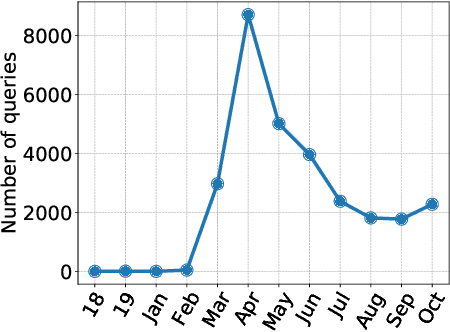

Click logs are valuable resources for a variety of information retrieval (IR) tasks. This includes query understanding/analysis, as well as learning effective IR models particularly when the models require large amounts of training data. We release a large-scale domain-specific dataset of click logs, obtained from user interactions of the Trip Database health web search engine. Our click log dataset comprises approximately 5.2 million user interactions collected between 2013 and 2020. We use this dataset to create a standard IR evaluation benchmark -- TripClick -- with around 700,000 unique free-text queries and 1.3 million pairs of query-document relevance signals, whose relevance is estimated by two click-through models. As such, the collection is one of the few datasets offering the necessary data richness and scale to train neural IR models with a large amount of parameters, and notably the first in the health domain. Using TripClick, we conduct experiments to evaluate a variety of IR models, showing the benefits of exploiting this data to train neural architectures. In particular, the evaluation results show that the best performing neural IR model significantly improves the performance by a large margin relative to classical IR models, especially for more frequent queries.