 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Recurrent Adapters for Efficient Multi-Task Adaptation of Large Speech Models
Mar 25, 2024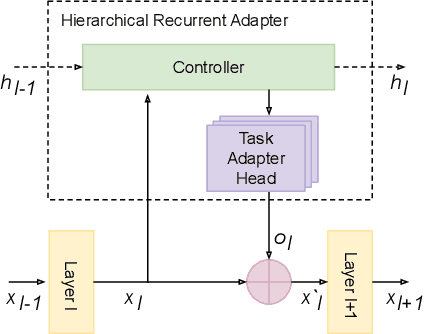
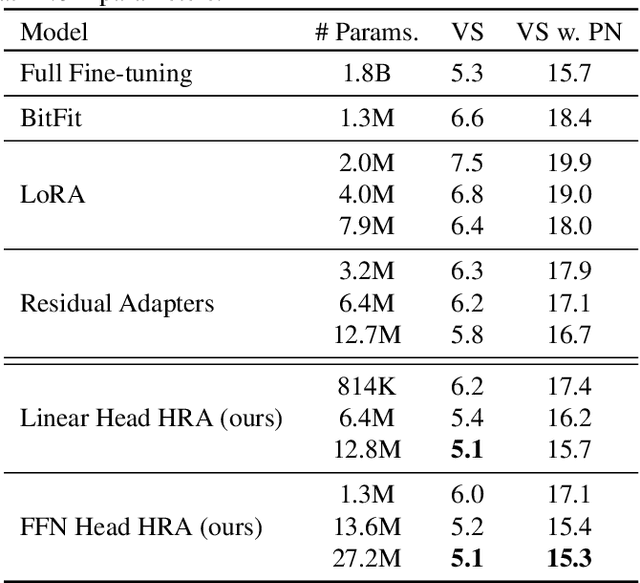
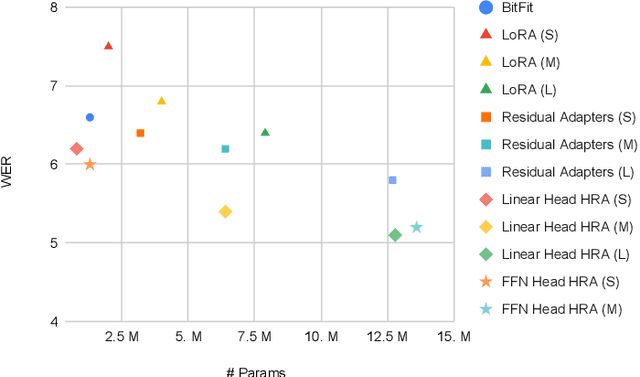
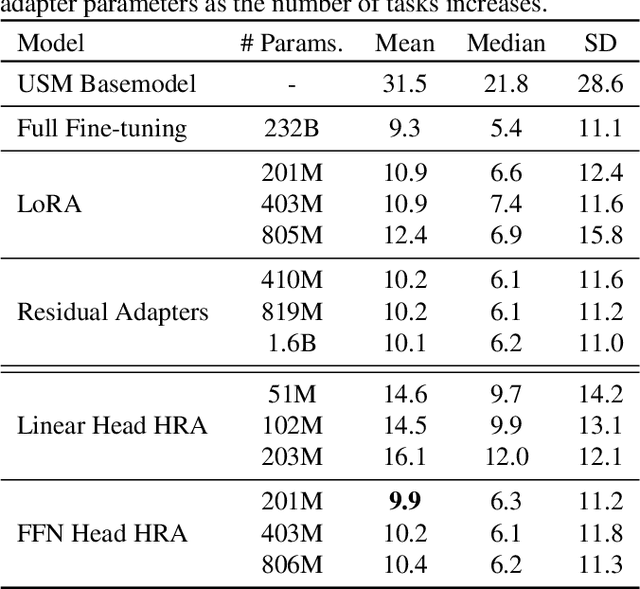
Parameter efficient adaptation methods have become a key mechanism to train large pre-trained models for downstream tasks. However, their per-task parameter overhead is considered still high when the number of downstream tasks to adapt for is large. We introduce an adapter module that has a better efficiency in large scale multi-task adaptation scenario. Our adapter is hierarchical in terms of how the adapter parameters are allocated. The adapter consists of a single shared controller network and multiple task-level adapter heads to reduce the per-task parameter overhead without performance regression on downstream tasks. The adapter is also recurrent so the entire adapter parameters are reused across different layers of the pre-trained model. Our Hierarchical Recurrent Adapter (HRA) outperforms the previous adapter-based approaches as well as full model fine-tuning baseline in both single and multi-task adaptation settings when evaluated on automatic speech recognition tasks.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Contextual Biasing with the Knuth-Morris-Pratt Matching Algorithm
Sep 29, 2023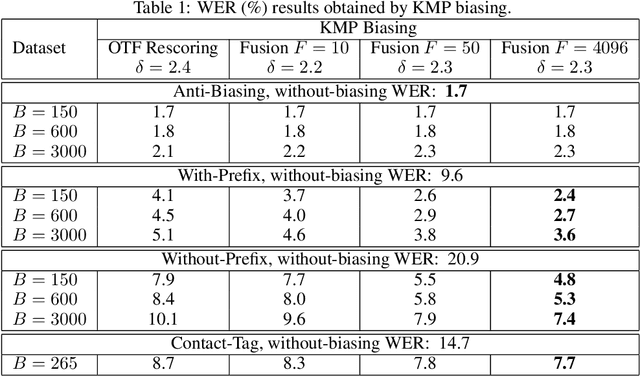
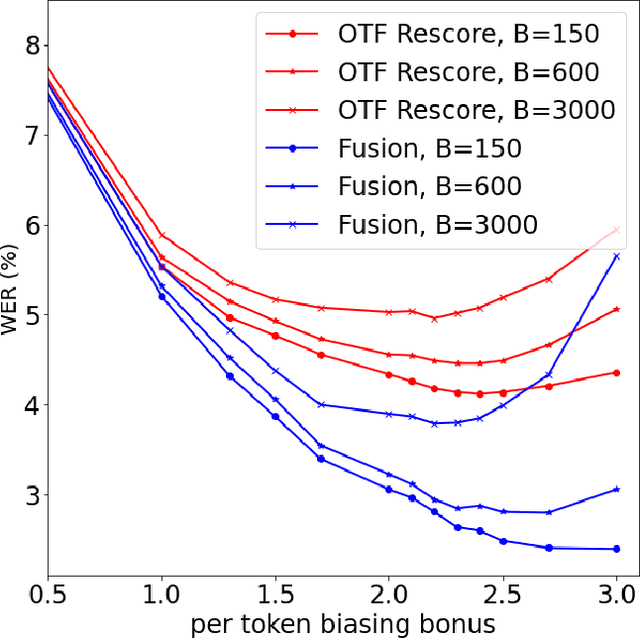
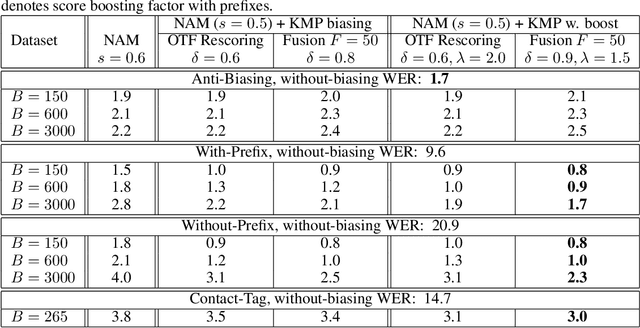
Contextual biasing refers to the problem of biasing the automatic speech recognition (ASR) systems towards rare entities that are relevant to the specific user or application scenarios. We propose algorithms for contextual biasing based on the Knuth-Morris-Pratt algorithm for pattern matching. During beam search, we boost the score of a token extension if it extends matching into a set of biasing phrases. Our method simulates the classical approaches often implemented in the weighted finite state transducer (WFST) framework, but avoids the FST language altogether, with careful considerations on memory footprint and efficiency on tensor processing units (TPUs) by vectorization. Without introducing additional model parameters, our method achieves significant word error rate (WER) reductions on biasing test sets by itself, and yields further performance gain when combined with a model-based biasing method.
Massive End-to-end Models for Short Search Queries
Sep 22, 2023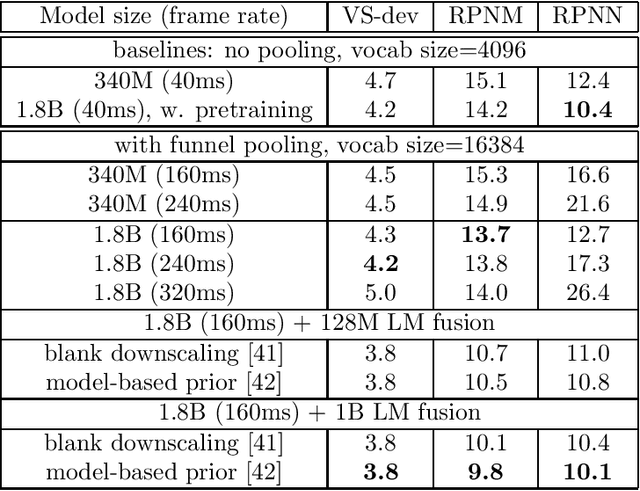
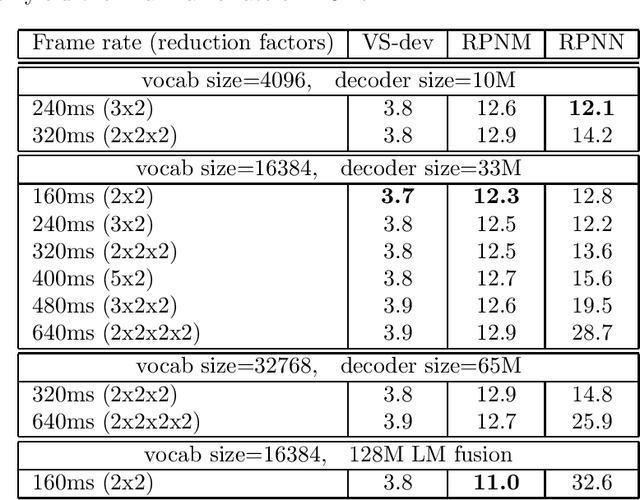
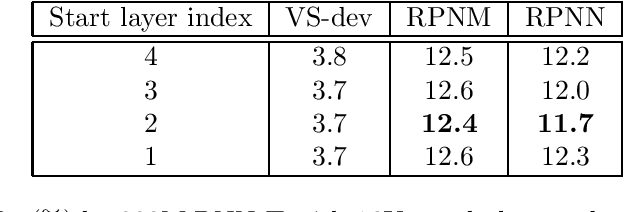
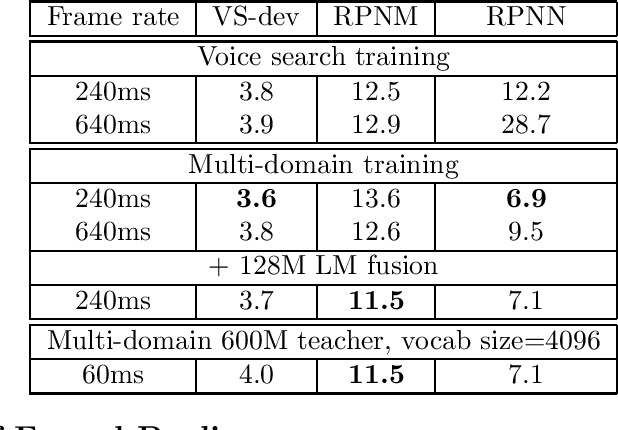
In this work, we investigate two popular end-to-end automatic speech recognition (ASR) models, namely Connectionist Temporal Classification (CTC) and RNN-Transducer (RNN-T), for offline recognition of voice search queries, with up to 2B model parameters. The encoders of our models use the neural architecture of Google's universal speech model (USM), with additional funnel pooling layers to significantly reduce the frame rate and speed up training and inference. We perform extensive studies on vocabulary size, time reduction strategy, and its generalization performance on long-form test sets. Despite the speculation that, as the model size increases, CTC can be as good as RNN-T which builds label dependency into the prediction, we observe that a 900M RNN-T clearly outperforms a 1.8B CTC and is more tolerant to severe time reduction, although the WER gap can be largely removed by LM shallow fusion.
Improving Speech Recognition for African American English With Audio Classification
Sep 16, 2023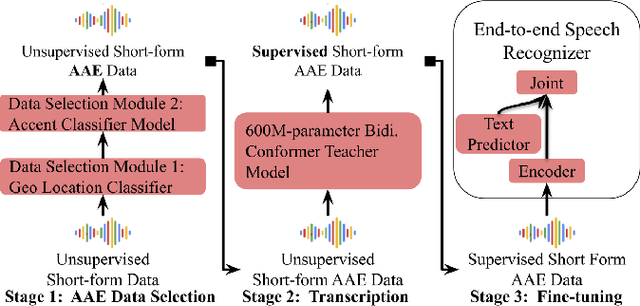
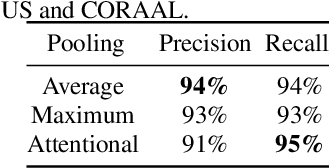
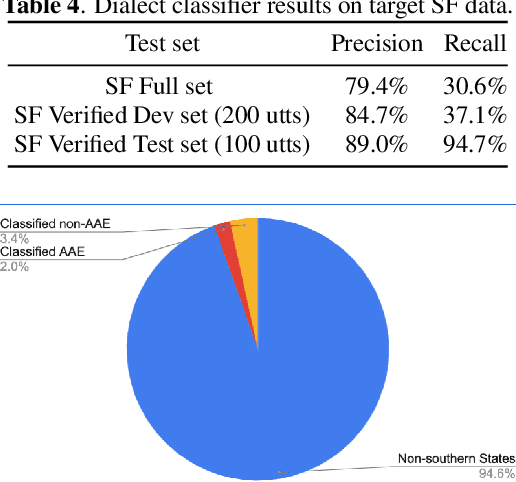

Automatic speech recognition (ASR) systems have been shown to have large quality disparities between the language varieties they are intended or expected to recognize. One way to mitigate this is to train or fine-tune models with more representative datasets. But this approach can be hindered by limited in-domain data for training and evaluation. We propose a new way to improve the robustness of a US English short-form speech recognizer using a small amount of out-of-domain (long-form) African American English (AAE) data. We use CORAAL, YouTube and Mozilla Common Voice to train an audio classifier to approximately output whether an utterance is AAE or some other variety including Mainstream American English (MAE). By combining the classifier output with coarse geographic information, we can select a subset of utterances from a large corpus of untranscribed short-form queries for semi-supervised learning at scale. Fine-tuning on this data results in a 38.5% relative word error rate disparity reduction between AAE and MAE without reducing MAE quality.
Augmenting conformers with structured state space models for online speech recognition
Sep 15, 2023
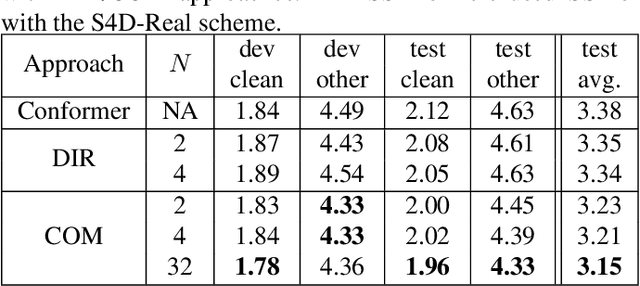
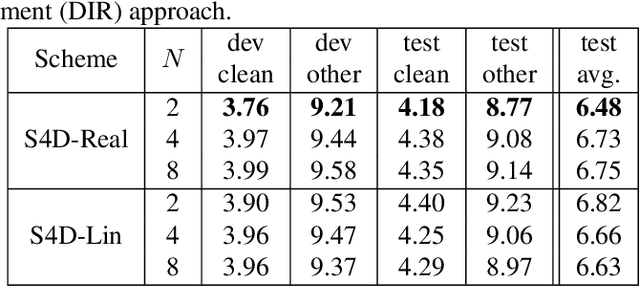
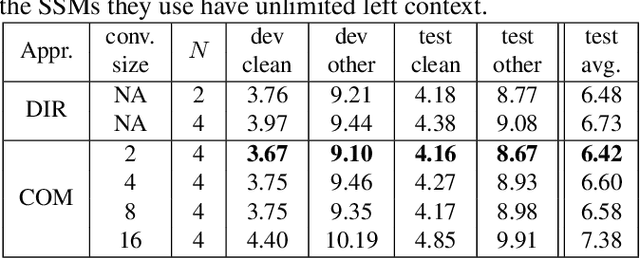
Online speech recognition, where the model only accesses context to the left, is an important and challenging use case for ASR systems. In this work, we investigate augmenting neural encoders for online ASR by incorporating structured state-space sequence models (S4), which are a family of models that provide a parameter-efficient way of accessing arbitrarily long left context. We perform systematic ablation studies to compare variants of S4 models and propose two novel approaches that combine them with convolutions. We find that the most effective design is to stack a small S4 using real-valued recurrent weights with a local convolution, allowing them to work complementarily. Our best model achieves WERs of 4.01%/8.53% on test sets from Librispeech, outperforming Conformers with extensively tuned convolution.
AudioPaLM: A Large Language Model That Can Speak and Listen
Jun 22, 2023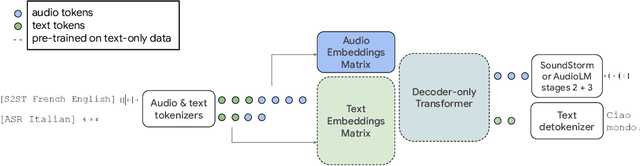



We introduce AudioPaLM, a large language model for speech understanding and generation. AudioPaLM fuses text-based and speech-based language models, PaLM-2 [Anil et al., 2023] and AudioLM [Borsos et al., 2022], into a unified multimodal architecture that can process and generate text and speech with applications including speech recognition and speech-to-speech translation. AudioPaLM inherits the capability to preserve paralinguistic information such as speaker identity and intonation from AudioLM and the linguistic knowledge present only in text large language models such as PaLM-2. We demonstrate that initializing AudioPaLM with the weights of a text-only large language model improves speech processing, successfully leveraging the larger quantity of text training data used in pretraining to assist with the speech tasks. The resulting model significantly outperforms existing systems for speech translation tasks and has the ability to perform zero-shot speech-to-text translation for many languages for which input/target language combinations were not seen in training. AudioPaLM also demonstrates features of audio language models, such as transferring a voice across languages based on a short spoken prompt. We release examples of our method at https://google-research.github.io/seanet/audiopalm/examples
A Comparison of Semi-Supervised Learning Techniques for Streaming ASR at Scale
Apr 19, 2023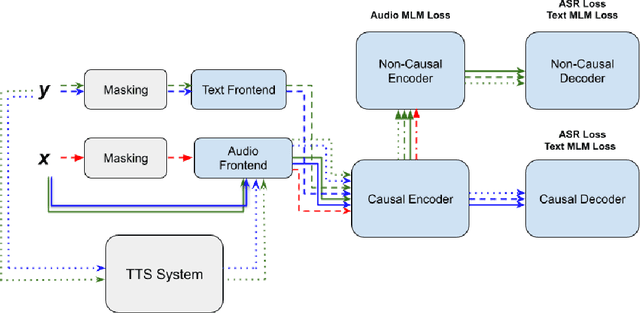
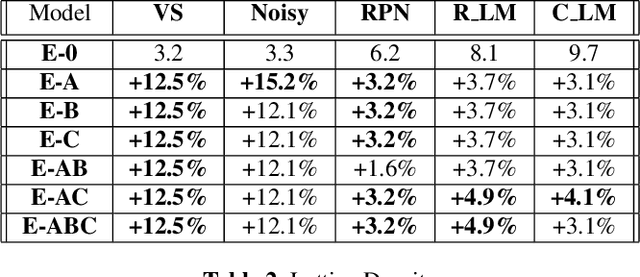
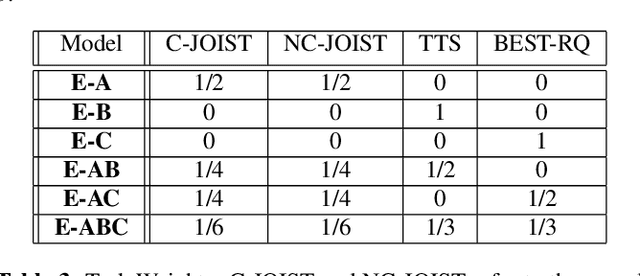
Unpaired text and audio injection have emerged as dominant methods for improving ASR performance in the absence of a large labeled corpus. However, little guidance exists on deploying these methods to improve production ASR systems that are trained on very large supervised corpora and with realistic requirements like a constrained model size and CPU budget, streaming capability, and a rich lattice for rescoring and for downstream NLU tasks. In this work, we compare three state-of-the-art semi-supervised methods encompassing both unpaired text and audio as well as several of their combinations in a controlled setting using joint training. We find that in our setting these methods offer many improvements beyond raw WER, including substantial gains in tail-word WER, decoder computation during inference, and lattice density.
Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages
Mar 03, 2023
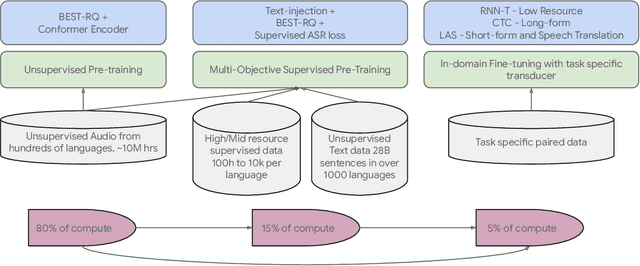
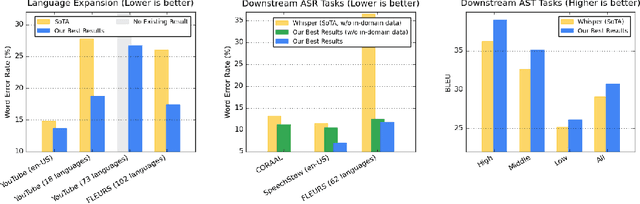

We introduce the Universal Speech Model (USM), a single large model that performs automatic speech recognition (ASR) across 100+ languages. This is achieved by pre-training the encoder of the model on a large unlabeled multilingual dataset of 12 million (M) hours spanning over 300 languages, and fine-tuning on a smaller labeled dataset. We use multilingual pre-training with random-projection quantization and speech-text modality matching to achieve state-of-the-art performance on downstream multilingual ASR and speech-to-text translation tasks. We also demonstrate that despite using a labeled training set 1/7-th the size of that used for the Whisper model, our model exhibits comparable or better performance on both in-domain and out-of-domain speech recognition tasks across many languages.