 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparison of Semi-Supervised Learning Techniques for Streaming ASR at Scale
Paper and Code
Apr 19, 2023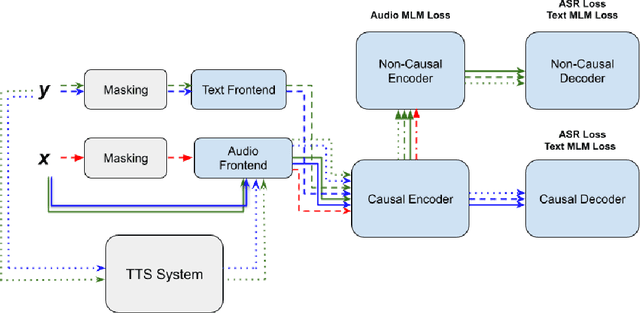
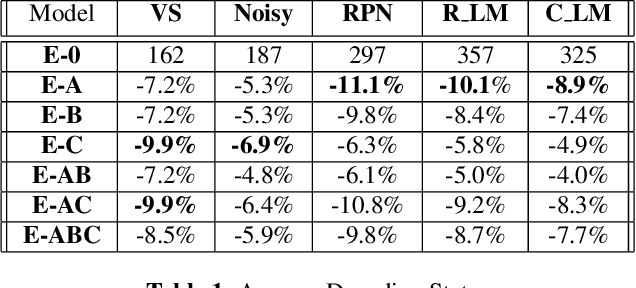
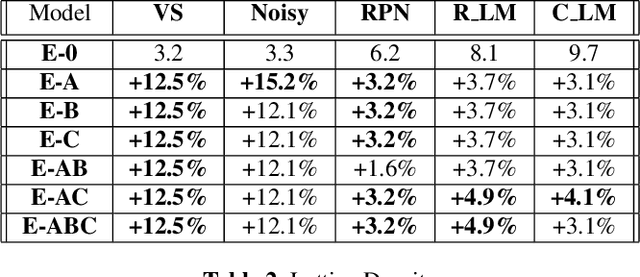
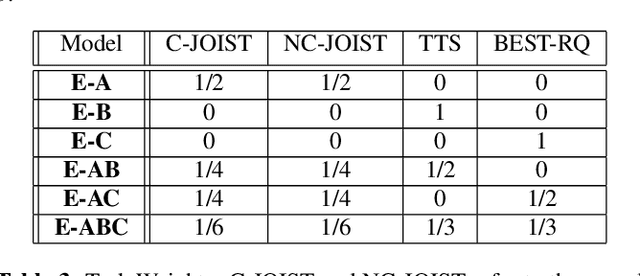
Unpaired text and audio injection have emerged as dominant methods for improving ASR performance in the absence of a large labeled corpus. However, little guidance exists on deploying these methods to improve production ASR systems that are trained on very large supervised corpora and with realistic requirements like a constrained model size and CPU budget, streaming capability, and a rich lattice for rescoring and for downstream NLU tasks. In this work, we compare three state-of-the-art semi-supervised methods encompassing both unpaired text and audio as well as several of their combinations in a controlled setting using joint training. We find that in our setting these methods offer many improvements beyond raw WER, including substantial gains in tail-word WER, decoder computation during inference, and lattice density.