 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Biasing with the Knuth-Morris-Pratt Matching Algorithm
Paper and Code
Sep 29, 2023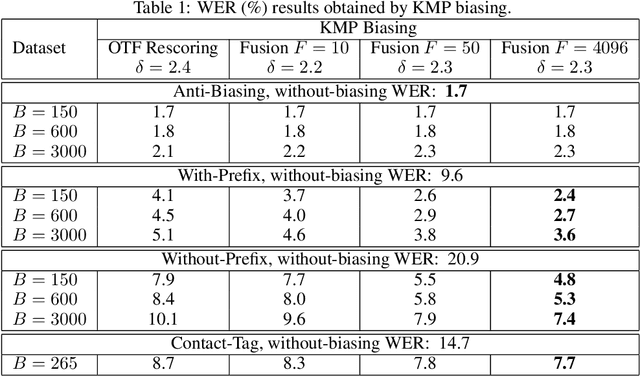
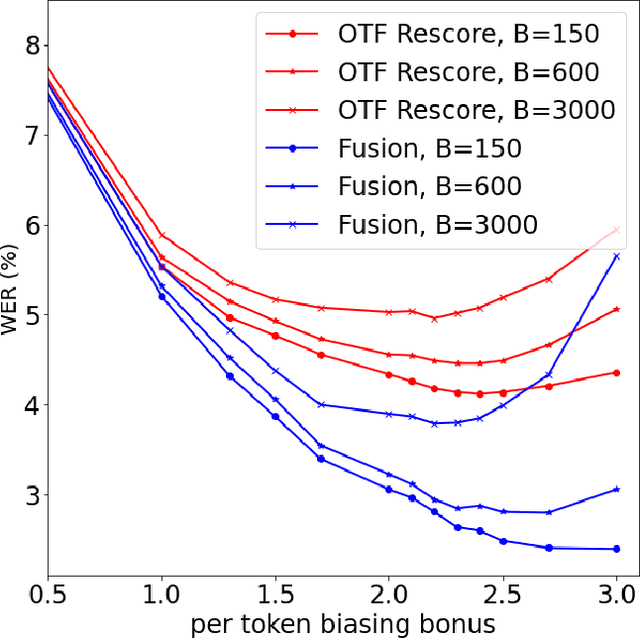
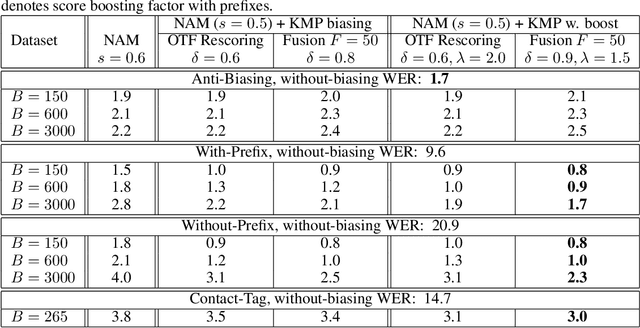
Contextual biasing refers to the problem of biasing the automatic speech recognition (ASR) systems towards rare entities that are relevant to the specific user or application scenarios. We propose algorithms for contextual biasing based on the Knuth-Morris-Pratt algorithm for pattern matching. During beam search, we boost the score of a token extension if it extends matching into a set of biasing phrases. Our method simulates the classical approaches often implemented in the weighted finite state transducer (WFST) framework, but avoids the FST language altogether, with careful considerations on memory footprint and efficiency on tensor processing units (TPUs) by vectorization. Without introducing additional model parameters, our method achieves significant word error rate (WER) reductions on biasing test sets by itself, and yields further performance gain when combined with a model-based biasing method.