 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Really Need 10+ Thoughts for "Find the Time 1000 Days Later"? Towards Structural Understanding of LLM Overthinking
Oct 09, 2025Models employing long chain-of-thought (CoT) reasoning have shown superior performance on complex reasoning tasks. Yet, this capability introduces a critical and often overlooked inefficiency -- overthinking -- models often engage in unnecessarily extensive reasoning even for simple queries, incurring significant computations without accuracy improvements. While prior work has explored solutions to mitigate overthinking, a fundamental gap remains in our understanding of its underlying causes. Most existing analyses are limited to superficial, profiling-based observations, failing to delve into LLMs' inner workings. This study introduces a systematic, fine-grained analyzer of LLMs' thought process to bridge the gap, TRACE. We first benchmark the overthinking issue, confirming that long-thinking models are five to twenty times slower on simple tasks with no substantial gains. We then use TRACE to first decompose the thought process into minimally complete sub-thoughts. Next, by inferring discourse relationships among sub-thoughts, we construct granular thought progression graphs and subsequently identify common thinking patterns for topically similar queries. Our analysis reveals two major patterns for open-weight thinking models -- Explorer and Late Landing. This finding provides evidence that over-verification and over-exploration are the primary drivers of overthinking in LLMs. Grounded in thought structures, we propose a utility-based definition of overthinking, which moves beyond length-based metrics. This revised definition offers a more insightful understanding of LLMs' thought progression, as well as practical guidelines for principled overthinking management.
Multi-Turn Puzzles: Evaluating Interactive Reasoning and Strategic Dialogue in LLMs
Aug 13, 2025Large language models (LLMs) excel at solving problems with clear and complete statements, but often struggle with nuanced environments or interactive tasks which are common in most real-world scenarios. This highlights the critical need for developing LLMs that can effectively engage in logically consistent multi-turn dialogue, seek information and reason with incomplete data. To this end, we introduce a novel benchmark comprising a suite of multi-turn tasks each designed to test specific reasoning, interactive dialogue, and information-seeking abilities. These tasks have deterministic scoring mechanisms, thus eliminating the need for human intervention. Evaluating frontier models on our benchmark reveals significant headroom. Our analysis shows that most errors emerge from poor instruction following, reasoning failures, and poor planning. This benchmark provides valuable insights into the strengths and weaknesses of current LLMs in handling complex, interactive scenarios and offers a robust platform for future research aimed at improving these critical capabilities.
What Matters for Model Merging at Scale?
Oct 04, 2024



Model merging aims to combine multiple expert models into a more capable single model, offering benefits such as reduced storage and serving costs, improved generalization, and support for decentralized model development. Despite its promise, previous studies have primarily focused on merging a few small models. This leaves many unanswered questions about the effect of scaling model size and how it interplays with other key factors -- like the base model quality and number of expert models -- , to affect the merged model's performance. This work systematically evaluates the utility of model merging at scale, examining the impact of these different factors. We experiment with merging fully fine-tuned models using 4 popular merging methods -- Averaging, Task~Arithmetic, Dare, and TIES -- across model sizes ranging from 1B-64B parameters and merging up to 8 different expert models. We evaluate the merged models on both held-in tasks, i.e., the expert's training tasks, and zero-shot generalization to unseen held-out tasks. Our experiments provide several new insights about model merging at scale and the interplay between different factors. First, we find that merging is more effective when experts are created from strong base models, i.e., models with good zero-shot performance. Second, larger models facilitate easier merging. Third merging consistently improves generalization capabilities. Notably, when merging 8 large expert models, the merged models often generalize better compared to the multitask trained models. Fourth, we can better merge more expert models when working with larger models. Fifth, different merging methods behave very similarly at larger scales. Overall, our findings shed light on some interesting properties of model merging while also highlighting some limitations. We hope that this study will serve as a reference point on large-scale merging for upcoming research.
Deferred NAM: Low-latency Top-K Context Injection via DeferredContext Encoding for Non-Streaming ASR
Apr 15, 2024



Contextual biasing enables speech recognizers to transcribe important phrases in the speaker's context, such as contact names, even if they are rare in, or absent from, the training data. Attention-based biasing is a leading approach which allows for full end-to-end cotraining of the recognizer and biasing system and requires no separate inference-time components. Such biasers typically consist of a context encoder; followed by a context filter which narrows down the context to apply, improving per-step inference time; and, finally, context application via cross attention. Though much work has gone into optimizing per-frame performance, the context encoder is at least as important: recognition cannot begin before context encoding ends. Here, we show the lightweight phrase selection pass can be moved before context encoding, resulting in a speedup of up to 16.1 times and enabling biasing to scale to 20K phrases with a maximum pre-decoding delay under 33ms. With the addition of phrase- and wordpiece-level cross-entropy losses, our technique also achieves up to a 37.5% relative WER reduction over the baseline without the losses and lightweight phrase selection pass.
* 9 pages, 3 figures, accepted by NAACL 2024 - Industry Track
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Apr 10, 2024



This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. Our approach introduces minimal bounded memory parameters and enables fast streaming inference for LLMs.
Hierarchical Recurrent Adapters for Efficient Multi-Task Adaptation of Large Speech Models
Mar 25, 2024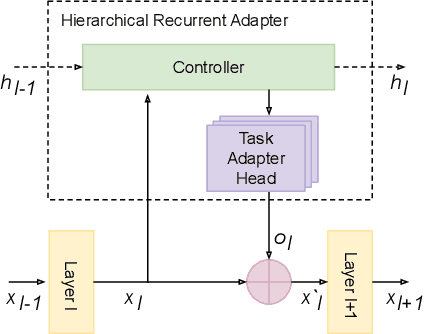
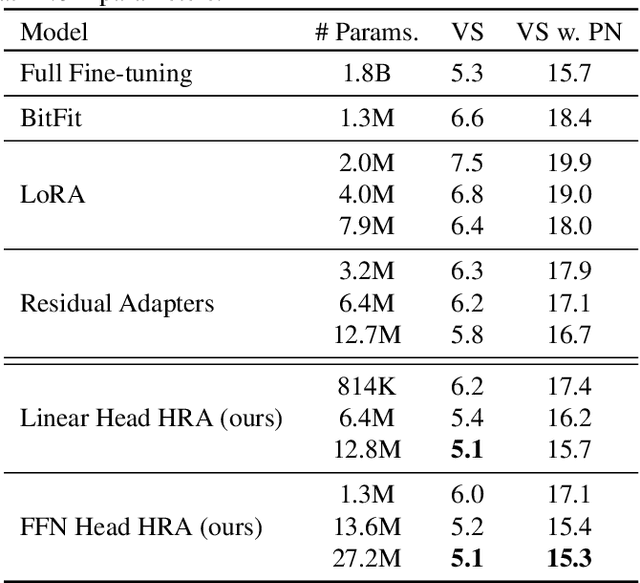
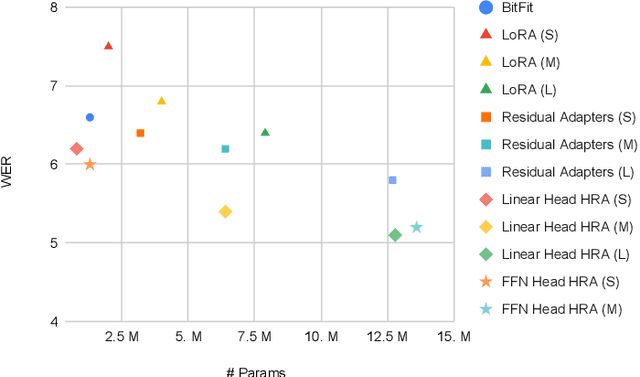
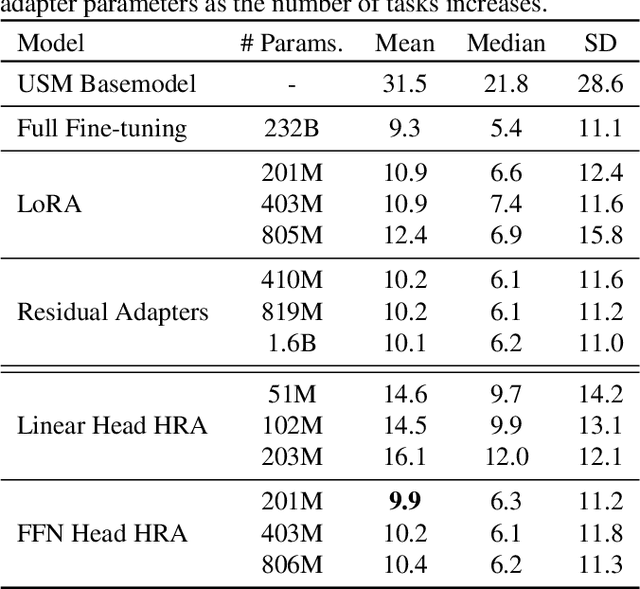
Parameter efficient adaptation methods have become a key mechanism to train large pre-trained models for downstream tasks. However, their per-task parameter overhead is considered still high when the number of downstream tasks to adapt for is large. We introduce an adapter module that has a better efficiency in large scale multi-task adaptation scenario. Our adapter is hierarchical in terms of how the adapter parameters are allocated. The adapter consists of a single shared controller network and multiple task-level adapter heads to reduce the per-task parameter overhead without performance regression on downstream tasks. The adapter is also recurrent so the entire adapter parameters are reused across different layers of the pre-trained model. Our Hierarchical Recurrent Adapter (HRA) outperforms the previous adapter-based approaches as well as full model fine-tuning baseline in both single and multi-task adaptation settings when evaluated on automatic speech recognition tasks.
Contextual Biasing with the Knuth-Morris-Pratt Matching Algorithm
Sep 29, 2023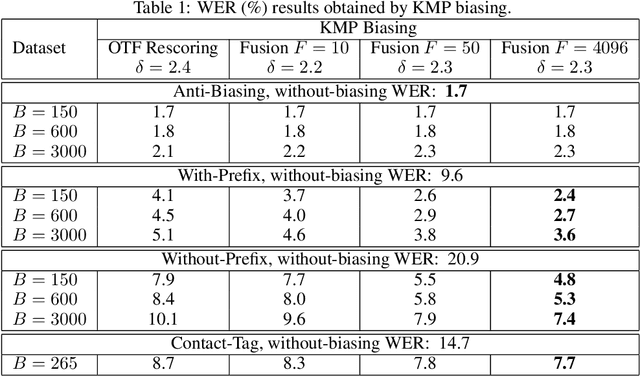
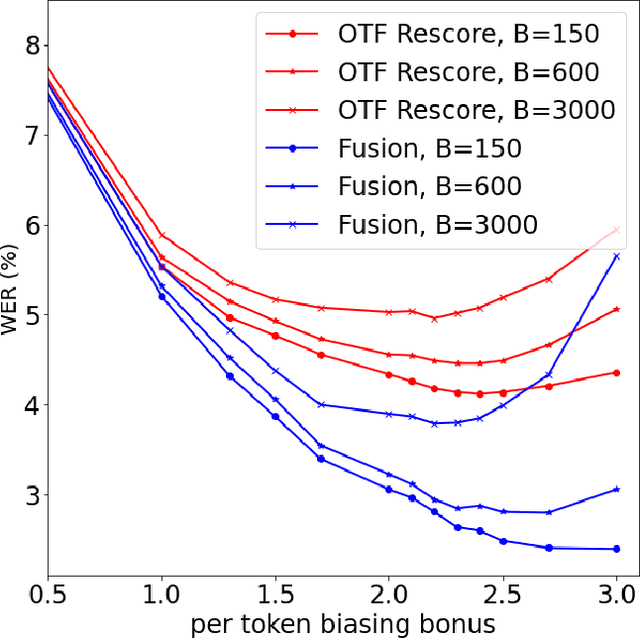
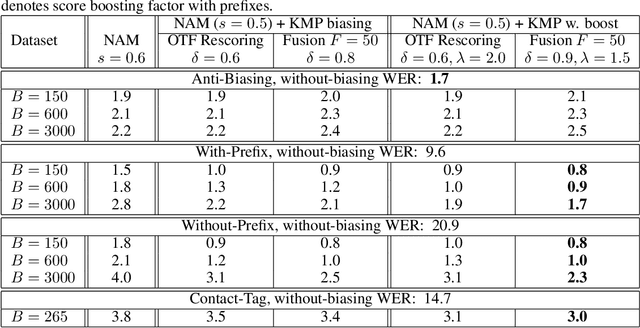
Contextual biasing refers to the problem of biasing the automatic speech recognition (ASR) systems towards rare entities that are relevant to the specific user or application scenarios. We propose algorithms for contextual biasing based on the Knuth-Morris-Pratt algorithm for pattern matching. During beam search, we boost the score of a token extension if it extends matching into a set of biasing phrases. Our method simulates the classical approaches often implemented in the weighted finite state transducer (WFST) framework, but avoids the FST language altogether, with careful considerations on memory footprint and efficiency on tensor processing units (TPUs) by vectorization. Without introducing additional model parameters, our method achieves significant word error rate (WER) reductions on biasing test sets by itself, and yields further performance gain when combined with a model-based biasing method.
Improving Speech Recognition for African American English With Audio Classification
Sep 16, 2023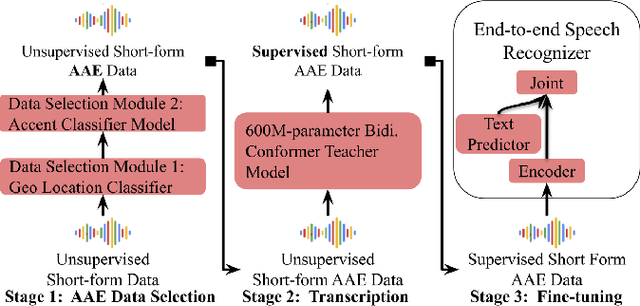
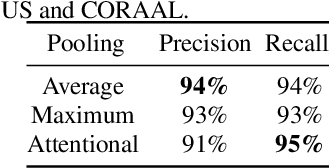

Automatic speech recognition (ASR) systems have been shown to have large quality disparities between the language varieties they are intended or expected to recognize. One way to mitigate this is to train or fine-tune models with more representative datasets. But this approach can be hindered by limited in-domain data for training and evaluation. We propose a new way to improve the robustness of a US English short-form speech recognizer using a small amount of out-of-domain (long-form) African American English (AAE) data. We use CORAAL, YouTube and Mozilla Common Voice to train an audio classifier to approximately output whether an utterance is AAE or some other variety including Mainstream American English (MAE). By combining the classifier output with coarse geographic information, we can select a subset of utterances from a large corpus of untranscribed short-form queries for semi-supervised learning at scale. Fine-tuning on this data results in a 38.5% relative word error rate disparity reduction between AAE and MAE without reducing MAE quality.
Diverse Distributions of Self-Supervised Tasks for Meta-Learning in NLP
Nov 02, 2021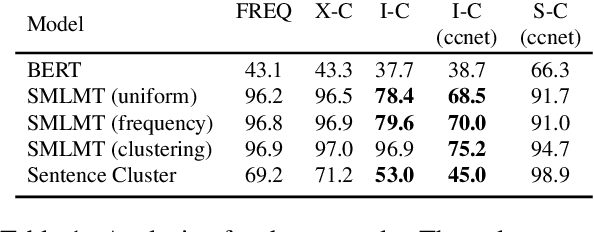
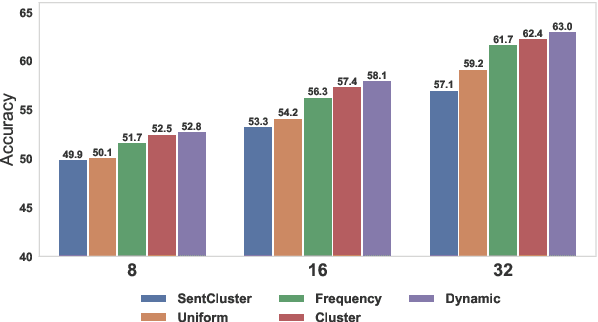
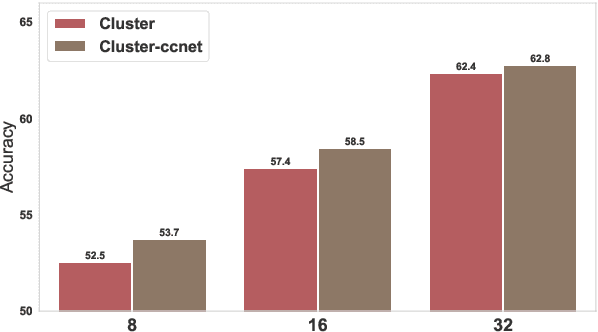
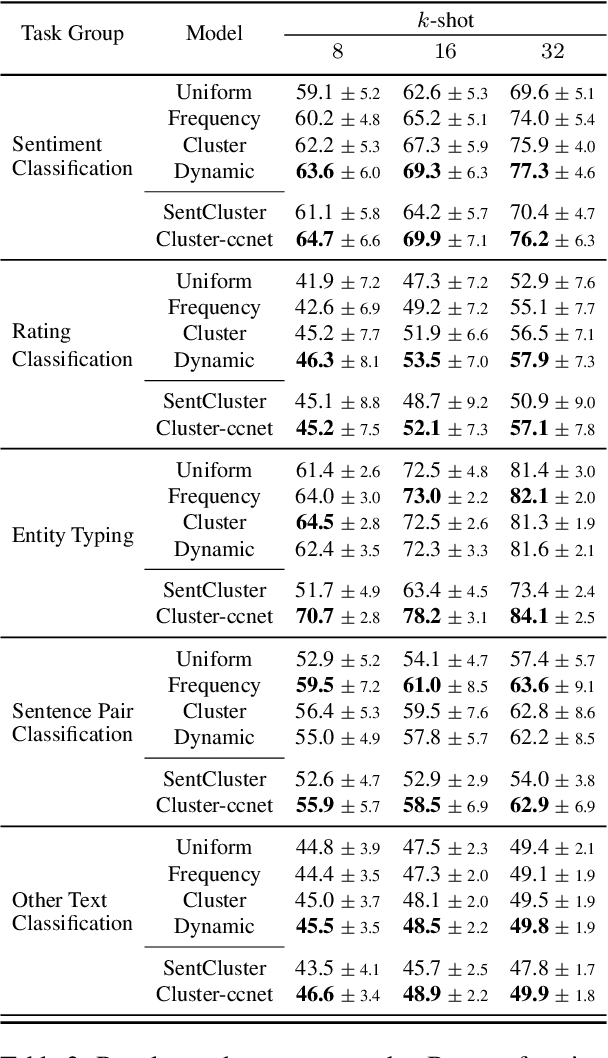
Meta-learning considers the problem of learning an efficient learning process that can leverage its past experience to accurately solve new tasks. However, the efficacy of meta-learning crucially depends on the distribution of tasks available for training, and this is often assumed to be known a priori or constructed from limited supervised datasets. In this work, we aim to provide task distributions for meta-learning by considering self-supervised tasks automatically proposed from unlabeled text, to enable large-scale meta-learning in NLP. We design multiple distributions of self-supervised tasks by considering important aspects of task diversity, difficulty, type, domain, and curriculum, and investigate how they affect meta-learning performance. Our analysis shows that all these factors meaningfully alter the task distribution, some inducing significant improvements in downstream few-shot accuracy of the meta-learned models. Empirically, results on 20 downstream tasks show significant improvements in few-shot learning -- adding up to +4.2% absolute accuracy (on average) to the previous unsupervised meta-learning method, and perform comparably to supervised methods on the FewRel 2.0 benchmark.
Fast Contextual Adaptation with Neural Associative Memory for On-Device Personalized Speech Recognition
Oct 07, 2021

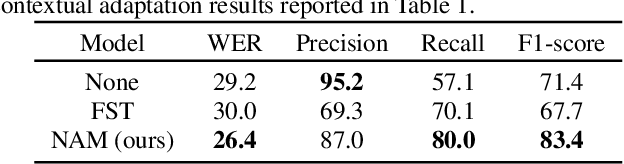

Fast contextual adaptation has shown to be effective in improving Automatic Speech Recognition (ASR) of rare words and when combined with an on-device personalized training, it can yield an even better recognition result. However, the traditional re-scoring approaches based on an external language model is prone to diverge during the personalized training. In this work, we introduce a model-based end-to-end contextual adaptation approach that is decoder-agnostic and amenable to on-device personalization. Our on-device simulation experiments demonstrate that the proposed approach outperforms the traditional re-scoring technique by 12% relative WER and 15.7% entity mention specific F1-score in a continues personalization scenario.