 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpelling Correction through Rewriting of Non-Autoregressive ASR Lattices
Sep 24, 2024



For end-to-end Automatic Speech Recognition (ASR) models, recognizing personal or rare phrases can be hard. A promising way to improve accuracy is through spelling correction (or rewriting) of the ASR lattice, where potentially misrecognized phrases are replaced with acoustically similar and contextually relevant alternatives. However, rewriting is challenging for ASR models trained with connectionist temporal classification (CTC) due to noisy hypotheses produced by a non-autoregressive, context-independent beam search. We present a finite-state transducer (FST) technique for rewriting wordpiece lattices generated by Transformer-based CTC models. Our algorithm performs grapheme-to-phoneme (G2P) conversion directly from wordpieces into phonemes, avoiding explicit word representations and exploiting the richness of the CTC lattice. Our approach requires no retraining or modification of the ASR model. We achieved up to a 15.2% relative reduction in sentence error rate (SER) on a test set with contextually relevant entities.
Deferred NAM: Low-latency Top-K Context Injection via DeferredContext Encoding for Non-Streaming ASR
Apr 15, 2024



Contextual biasing enables speech recognizers to transcribe important phrases in the speaker's context, such as contact names, even if they are rare in, or absent from, the training data. Attention-based biasing is a leading approach which allows for full end-to-end cotraining of the recognizer and biasing system and requires no separate inference-time components. Such biasers typically consist of a context encoder; followed by a context filter which narrows down the context to apply, improving per-step inference time; and, finally, context application via cross attention. Though much work has gone into optimizing per-frame performance, the context encoder is at least as important: recognition cannot begin before context encoding ends. Here, we show the lightweight phrase selection pass can be moved before context encoding, resulting in a speedup of up to 16.1 times and enabling biasing to scale to 20K phrases with a maximum pre-decoding delay under 33ms. With the addition of phrase- and wordpiece-level cross-entropy losses, our technique also achieves up to a 37.5% relative WER reduction over the baseline without the losses and lightweight phrase selection pass.
* 9 pages, 3 figures, accepted by NAACL 2024 - Industry Track
High-precision Voice Search Query Correction via Retrievable Speech-text Embedings
Jan 08, 2024Automatic speech recognition (ASR) systems can suffer from poor recall for various reasons, such as noisy audio, lack of sufficient training data, etc. Previous work has shown that recall can be improved by retrieving rewrite candidates from a large database of likely, contextually-relevant alternatives to the hypothesis text using nearest-neighbors search over embeddings of the ASR hypothesis text to correct and candidate corrections. However, ASR-hypothesis-based retrieval can yield poor precision if the textual hypotheses are too phonetically dissimilar to the transcript truth. In this paper, we eliminate the hypothesis-audio mismatch problem by querying the correction database directly using embeddings derived from the utterance audio; the embeddings of the utterance audio and candidate corrections are produced by multimodal speech-text embedding networks trained to place the embedding of the audio of an utterance and the embedding of its corresponding textual transcript close together. After locating an appropriate correction candidate using nearest-neighbor search, we score the candidate with its speech-text embedding distance before adding the candidate to the original n-best list. We show a relative word error rate (WER) reduction of 6% on utterances whose transcripts appear in the candidate set, without increasing WER on general utterances.
Contextual Biasing with the Knuth-Morris-Pratt Matching Algorithm
Sep 29, 2023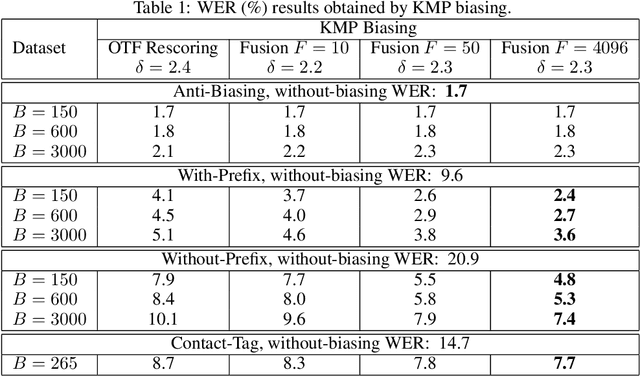
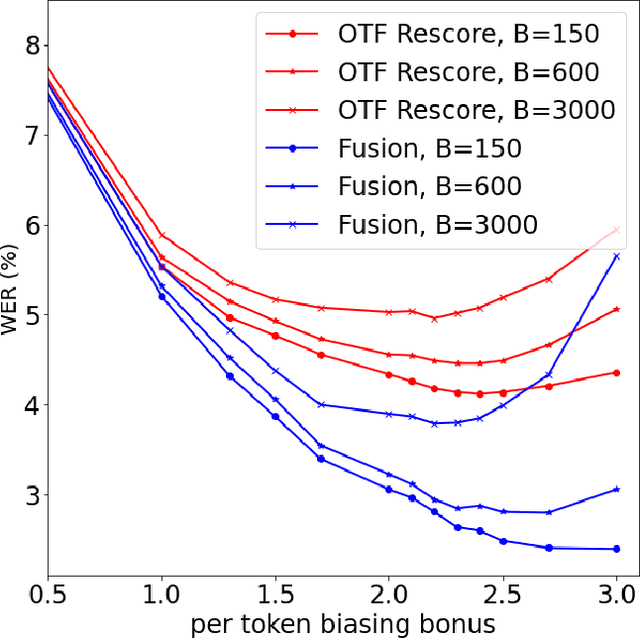
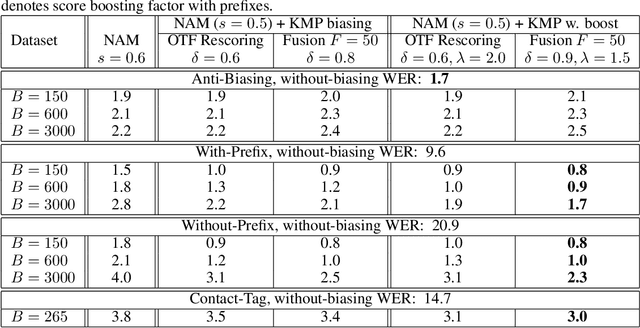
Contextual biasing refers to the problem of biasing the automatic speech recognition (ASR) systems towards rare entities that are relevant to the specific user or application scenarios. We propose algorithms for contextual biasing based on the Knuth-Morris-Pratt algorithm for pattern matching. During beam search, we boost the score of a token extension if it extends matching into a set of biasing phrases. Our method simulates the classical approaches often implemented in the weighted finite state transducer (WFST) framework, but avoids the FST language altogether, with careful considerations on memory footprint and efficiency on tensor processing units (TPUs) by vectorization. Without introducing additional model parameters, our method achieves significant word error rate (WER) reductions on biasing test sets by itself, and yields further performance gain when combined with a model-based biasing method.