 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Embedding Based Personalized Retrieval in Etsy Search
Jun 07, 2023
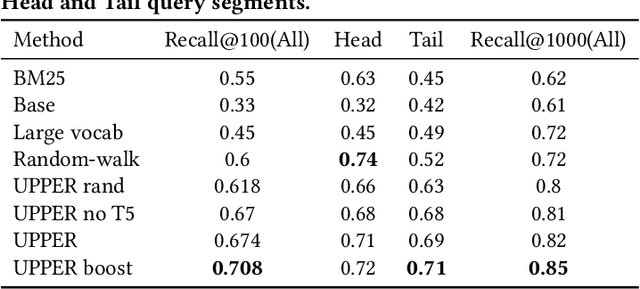
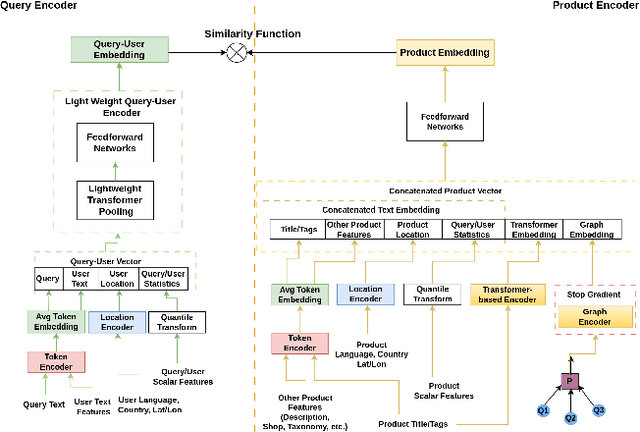

Embedding-based neural retrieval is a prevalent approach to address the semantic gap problem which often arises in product search on tail queries. In contrast, popular queries typically lack context and have a broad intent where additional context from users historical interaction can be helpful. In this paper, we share our novel approach to address both: the semantic gap problem followed by an end to end trained model for personalized semantic retrieval. We propose learning a unified embedding model incorporating graph, transformer and term-based embeddings end to end and share our design choices for optimal tradeoff between performance and efficiency. We share our learnings in feature engineering, hard negative sampling strategy, and application of transformer model, including a novel pre-training strategy and other tricks for improving search relevance and deploying such a model at industry scale. Our personalized retrieval model significantly improves the overall search experience, as measured by a 5.58% increase in search purchase rate and a 2.63% increase in site-wide conversion rate, aggregated across multiple A/B tests - on live traffic.
Self-Supervised Meta-Learning for Few-Shot Natural Language Classification Tasks
Sep 17, 2020
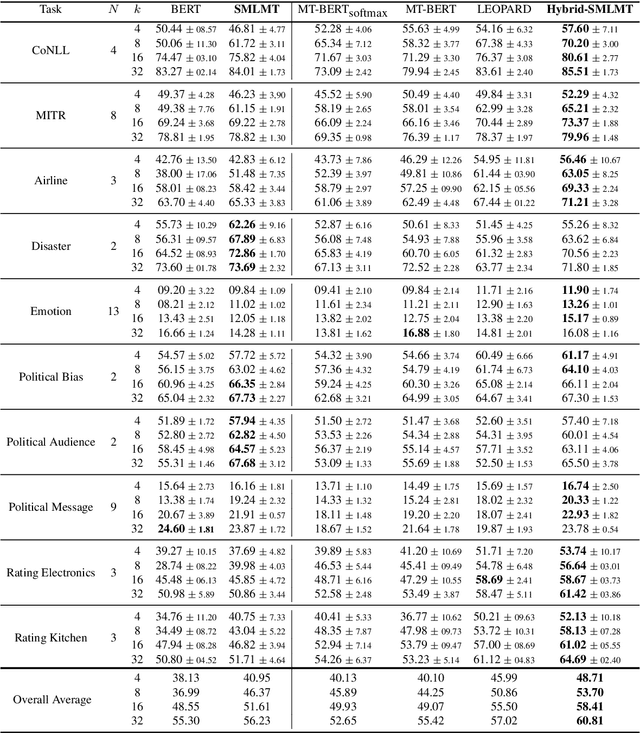
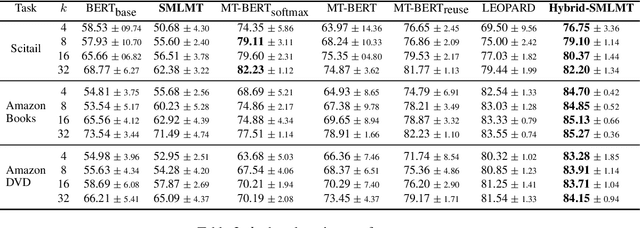

Self-supervised pre-training of transformer models has revolutionized NLP applications. Such pre-training with language modeling objectives provides a useful initial point for parameters that generalize well to new tasks with fine-tuning. However, fine-tuning is still data inefficient -- when there are few labeled examples, accuracy can be low. Data efficiency can be improved by optimizing pre-training directly for future fine-tuning with few examples; this can be treated as a meta-learning problem. However, standard meta-learning techniques require many training tasks in order to generalize; unfortunately, finding a diverse set of such supervised tasks is usually difficult. This paper proposes a self-supervised approach to generate a large, rich, meta-learning task distribution from unlabeled text. This is achieved using a cloze-style objective, but creating separate multi-class classification tasks by gathering tokens-to-be blanked from among only a handful of vocabulary terms. This yields as many unique meta-training tasks as the number of subsets of vocabulary terms. We meta-train a transformer model on this distribution of tasks using a recent meta-learning framework. On 17 NLP tasks, we show that this meta-training leads to better few-shot generalization than language-model pre-training followed by finetuning. Furthermore, we show how the self-supervised tasks can be combined with supervised tasks for meta-learning, providing substantial accuracy gains over previous supervised meta-learning.
Learning to Few-Shot Learn Across Diverse Natural Language Classification Tasks
Nov 10, 2019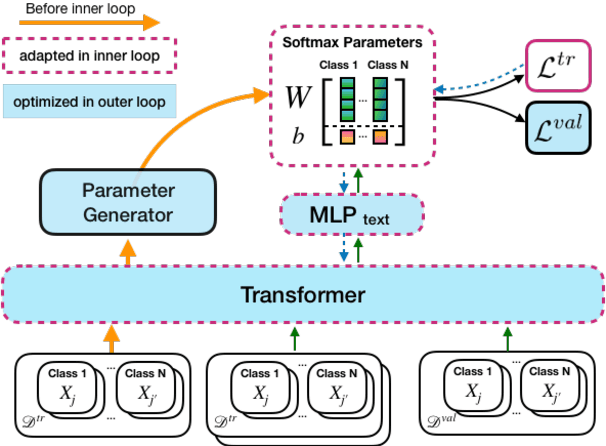
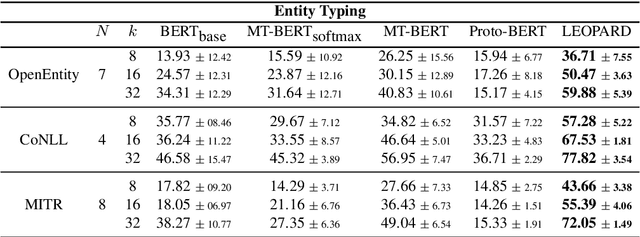

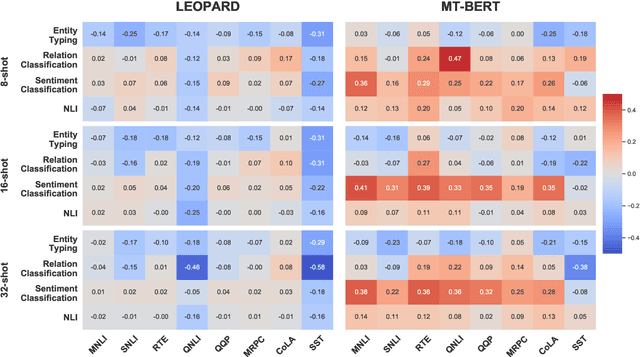
Self-supervised pre-training of transformer models has shown enormous success in improving performance on a number of downstream tasks. However, fine-tuning on a new task still requires large amounts of task-specific labelled data to achieve good performance. We consider this problem of learning to generalize to new tasks with few examples as a meta-learning problem. While meta-learning has shown tremendous progress in recent years, its application is still limited to simulated problems or problems with limited diversity across tasks. We develop a novel method, LEOPARD, which enables optimization-based meta-learning across tasks with different number of classes, and evaluate existing methods on generalization to diverse NLP classification tasks. LEOPARD is trained with the state-of-the-art transformer architecture and shows strong generalization to tasks not seen at all during training, with as few as 8 examples per label. On 16 NLP datasets, across a diverse task-set such as entity typing, relation extraction, natural language inference, sentiment analysis, and several other text categorization tasks, we show that LEOPARD learns better initial parameters for few-shot learning than self-supervised pre-training or multi-task training, outperforming many strong baselines, for example, increasing F1 from 49% to 72%.